主題図で統計を可視化しよう!

豆腐アドカレ2024の3日目です。
感想は#豆腐アドカレ まで。
こんにちは、マリネで決まりねです。緊急で書いてるので少々短く、雑な記事になると思いますがご容赦ください。
まずは私のことを知らない人も多いだろうので軽く自己紹介からさせていただきます。
19thの1年生です。最近は高校に行っていません。
主題図とは
簡単に言えば、特定のデータ(統計など)を地図上で棒・円グラフや色分けなどで表すものです。
そのデータについて、地域ごとの特色などを簡略に可視化できる素晴らしいツールです。
先輩たちのものを見る限り、課題研究って社会問題を叩き台として提案するものも多いですよね。そういうときに主題図を使えば、特にどんな地域で問題になっているのか、あるいは昔と比べてどうなのか、そういったことがよく分かってもらえるようになります。
今回は時間の都合でほんのさわりだけを紹介しますが、色々応用は効くのでぜひ調べてみてください。
主題図の作り方
いきなり本題です。このあとはパソコンで実際に作ってる様子をスクショして加工して貼って投稿しなきゃいけないのです。雑談をしている時間が無い。
MANDARA10のインストール
主題図を作る方法は色々あります。現在主流なのはQGISというソフトですかね?そちらも紹介したいのですが、時間が無いし私も使い方をちゃんと理解しているわけではありません。
今回用いるのは、もっと簡単に扱えるMANDARA10というソフトになります。
その中でも簡単な、色分けによる階級区分図についてやっていきましょう。
インストールは無料です。パソコンブラウザで「MANDARA10」と入力すると、たぶん一番上かな?にこういうページが出てくると思います。

ここの右上にある「ダウンロード」っていうのを押して、こういうページに飛びましょう。ここで一番上の「インストール版をダウンロード」を押してください。あとついでに3番目の項目、「更新サンプルファイルのダウンロード」を押してサンプルファイルをダウンロードします。zipファイルなので解凍もしましょう。
https://ktgis.net/mandara/download/index.html
このインストール版ファイルの展開のやり方は忘れました。ごめんなさい。調べていただけると幸いです。
実際に作ってみよう
さて、ダウンロードしたMANDARA10を開いてみましょう。最初に「操作選択」という表示が出ますが、それは無視です。閉じてください。
さて、薄黄色のような画面になりましたかね。
ここで左上の「ファイル」というところから、先程解凍したサンプルファイルを選択して、その中からサンプルを選んでいきます。
今回は「都道府県基本」と書いてあるファイルを使います。
開けましたでしょうか。
まずはものは試し、1回作ってみましょう。
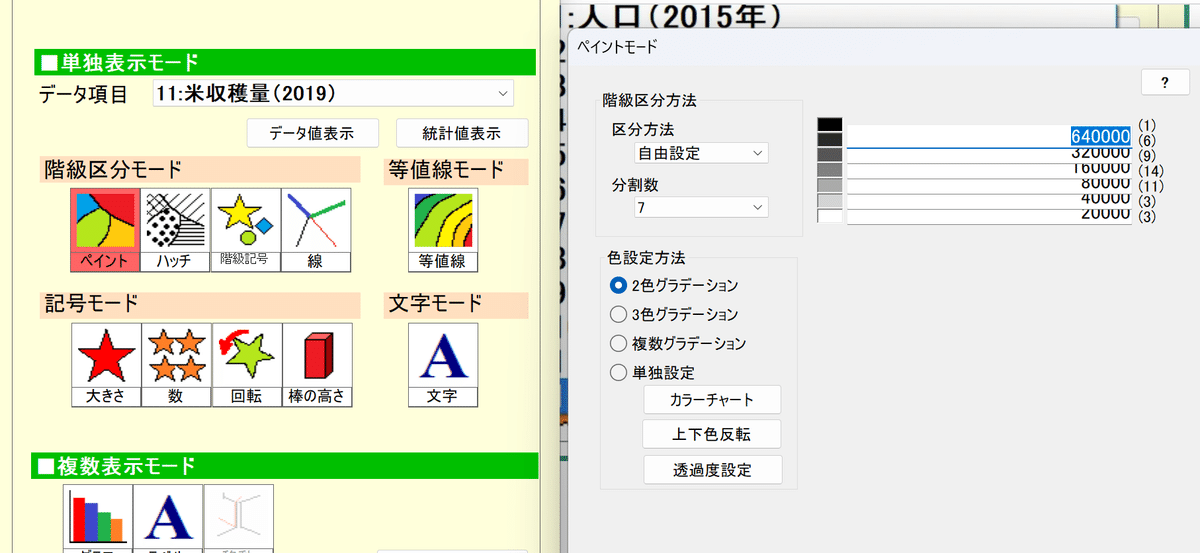
「データ表示モード」の「データ項目」という項目の∨をクリックすると、「都道府県基本」に設定されているデータ一覧が出てきます。今回は一番わかりやすい「人口(2015年)」を使ってみましょう。
まず、この人口を選択して、「階級区分モード」から「ペイント」を選択します。
そうしたら右側に何やら描画の調整を促すツールが出てくるかもしれませんが一旦無視して「描画開始」を押しましょう。
はい、日本地図が塗り分けられて出てきたと思います。
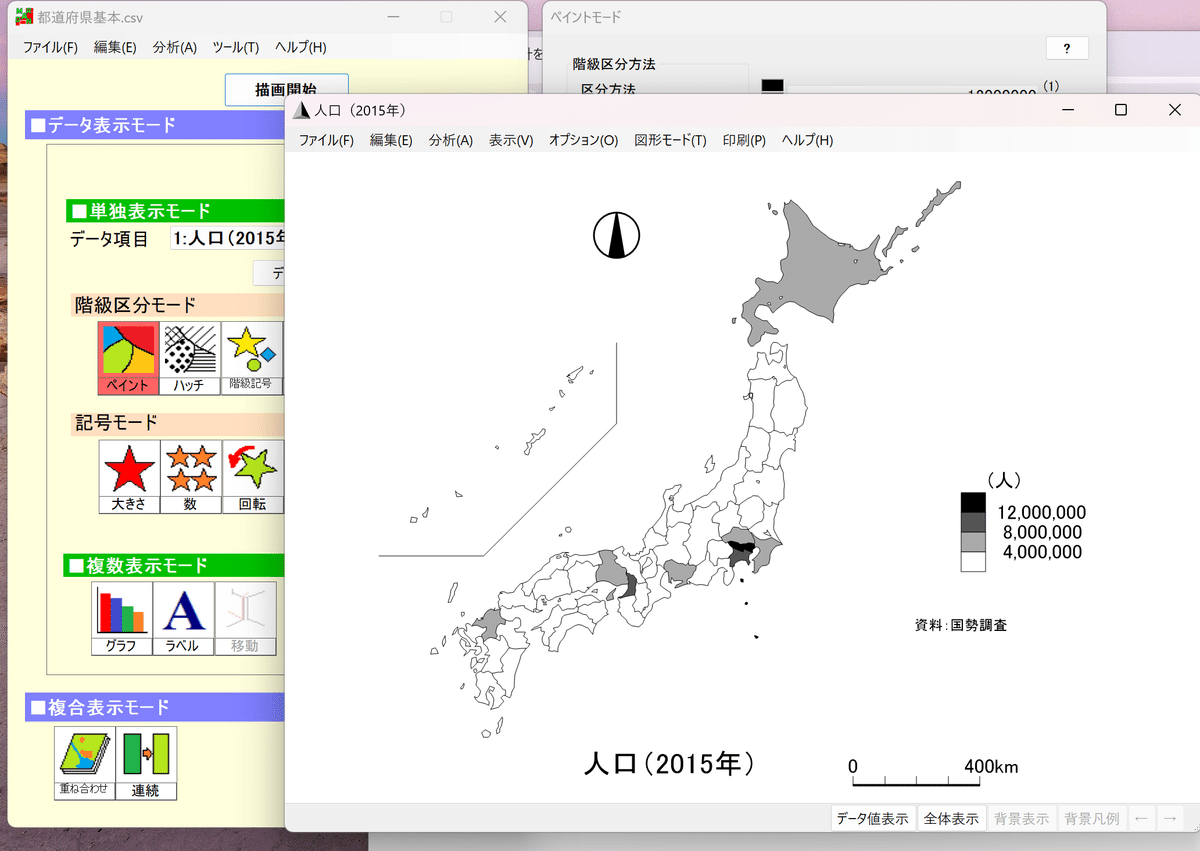
でもちょっと見にくくないですか?一部の人口の多いとど府県だけが塗られています。そういうときは、色を変えたり、階級区分を変えたりすることができます。
では、一旦作った主題図を閉じましょう。地図の❌印を消すと、描画前の状態に戻ります。
ここで、まずは階級を増やして見ましょう。
先程の調整を促すツールの、「区分方法」にある「分割数」をクリックしましょう。今回の場合は6個くらいの区分が欲しいですね。
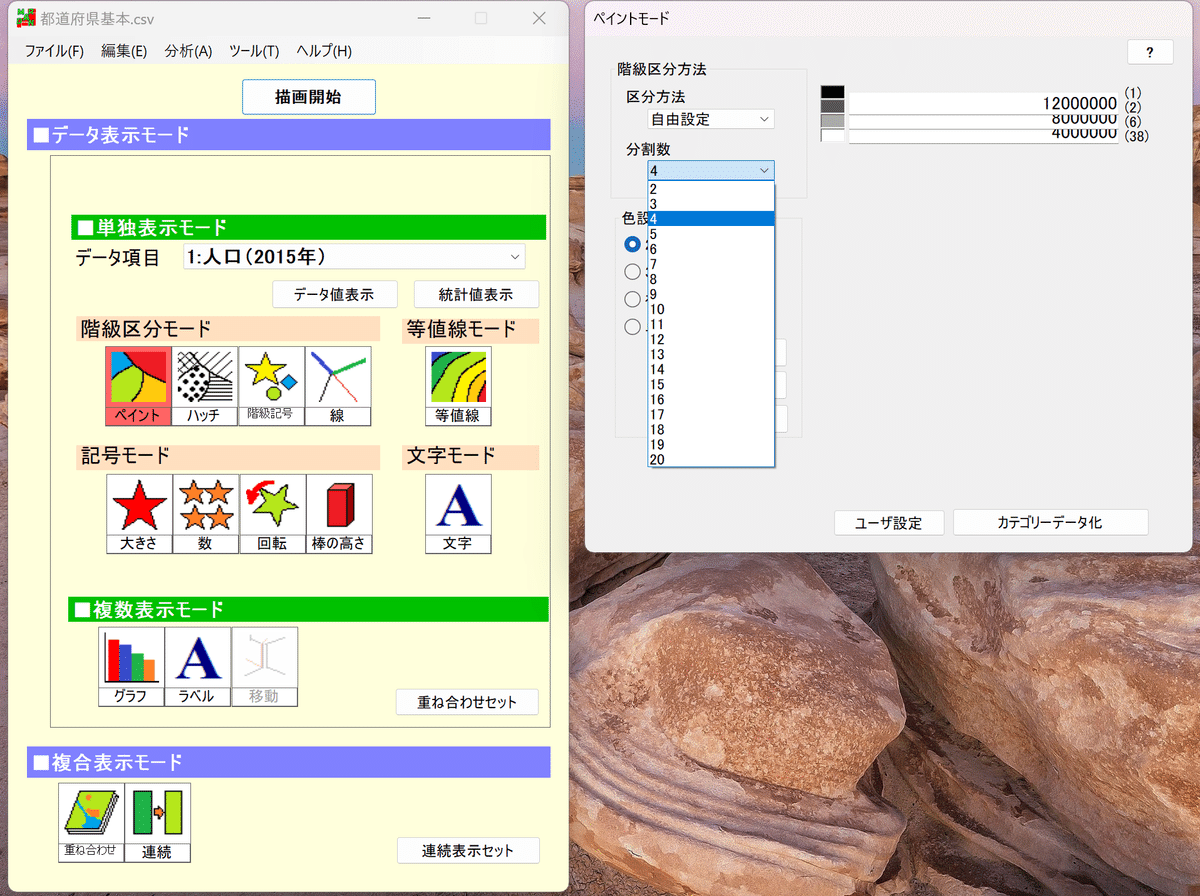
そうすると区分が開きますので、さっそく数字を打ち込みましょうか。
最初が1200万なのは多すぎるので、1000万にしましょう。そして200万ずつ、数字を減らしていきます。
そうして「描画開始」を押すと、この通り。
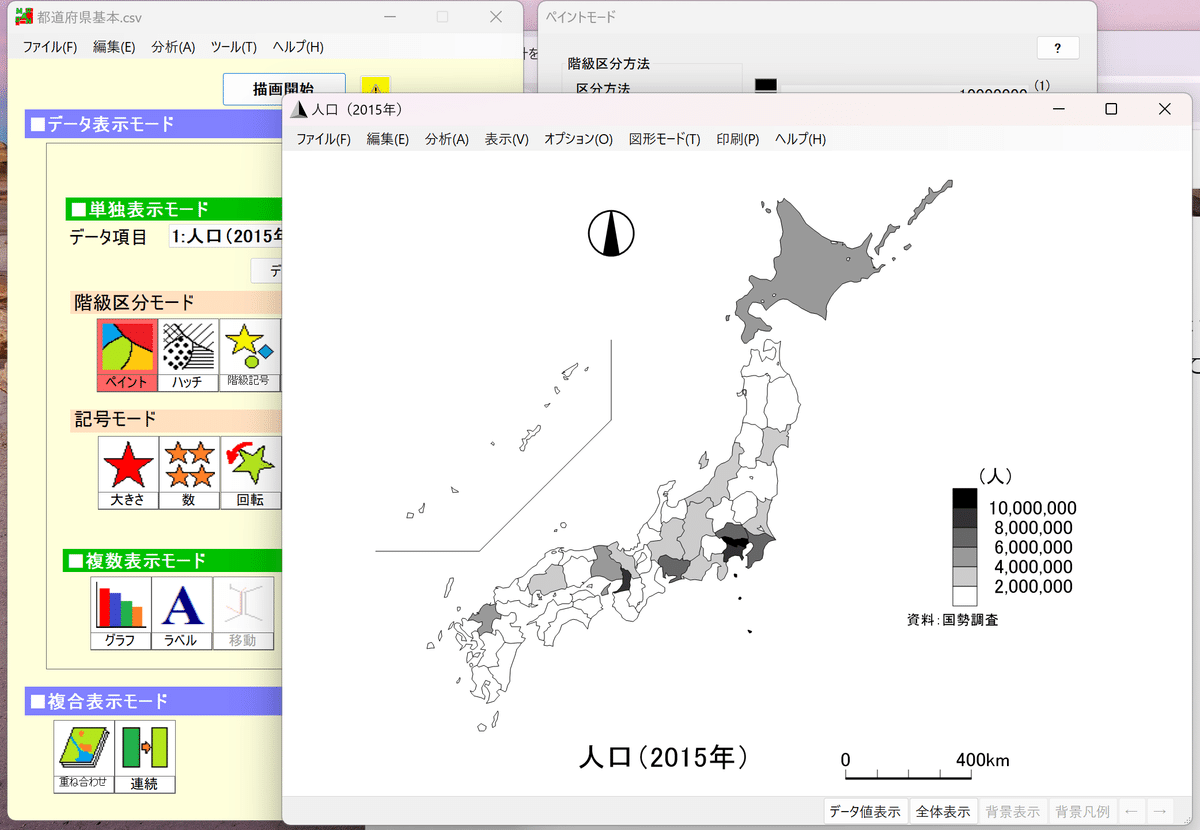
さてさて、ここまで来たら、次は「複合表示モード」について触れていきましょうか。ついでに、使うデータの追加方法についてもやっていきます。
ちなみに、MANDARA10は作業を保存できないので、必要があれば左上の「ファイル」から保存しましょう。
さて、今回は、2つのデータの比較ということで、特徴の見やすい「コメ」と「小麦」の生産量の比較をしてみたいと思います。
データを探す
まず必要なのは、統計データです。今回は政府統計局が作っているE-statというサイトから、国内のコメと小麦の生産量を拾って来ようと思います。
ということで、まずはパソコンブラウザで「E-stat」と検索してみましょう。
サイトが開けたら、「分野」を開き、「農林水産業」にある「作物統計調査」を選択します。

そこを開くと、「データベース」と「ファイル」がありますが、今回は「データベース」の方を開きます。
いろいろ並んでいますが、今回は2番目の「作況調査(水陸稲、麦類、豆類、かんしょ、飼料作物、工芸農作物)」の「確報」を選択します。
直近のものはデータがないこともあるので、今回は令和元年(2019年)のものにしましょうか。
それではさっそく、コメと小麦の生産量をまとめていきましょう。
まずは一番上の米 水陸稲の収穫量 水稲(全国農業地域別・都道府県別)から開き、左上にある「DB」を開きましょう。
そしたらそれを、右上の「ダウンロード」で保存します。
ファイル形式は「XLSX形式」にして、他はノータッチで大丈夫です。
さて、ダウンロードしたものをExelで開きましょう。
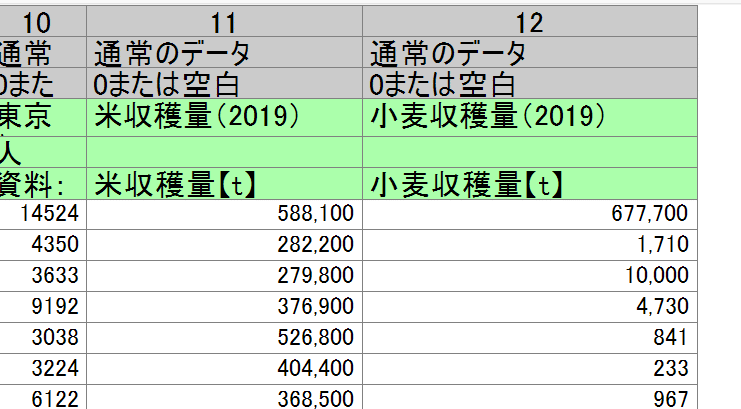
今回使うのは左から3番目の収穫量(子実用)【t】です。
なので、まずは使わないCとDとEの列を削除して、都道府県名と収穫量が横並びになるようにしたら、BとCの2列を別のシートにコピーします。
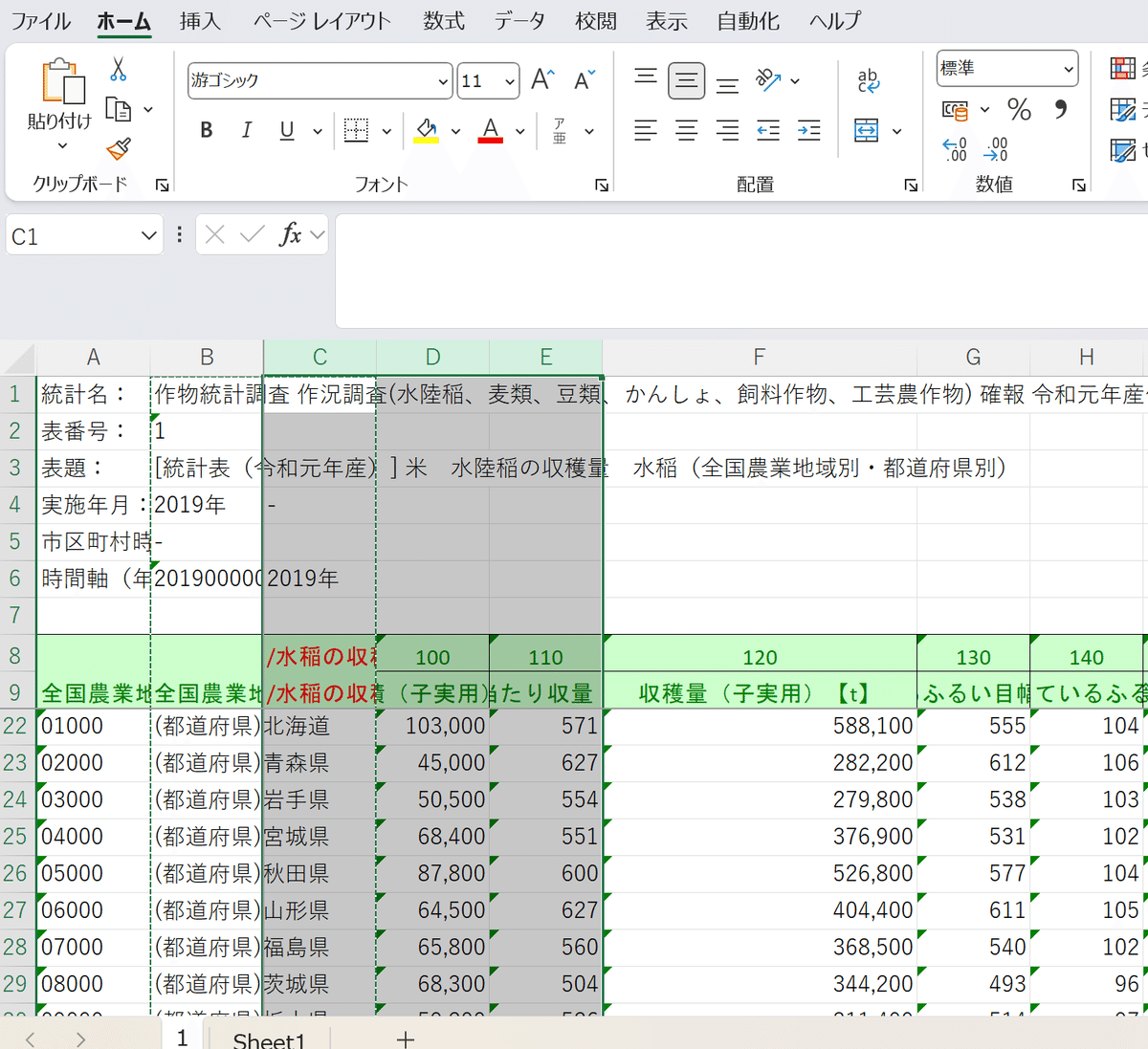
県名が見にくいので、その列の横幅を調整しましょう。
次に、不要なデータを削除します。今回はこの地域別区分が必要ありませんね。これで都道府県単位で見られるようになりましたが、ここでストップ。
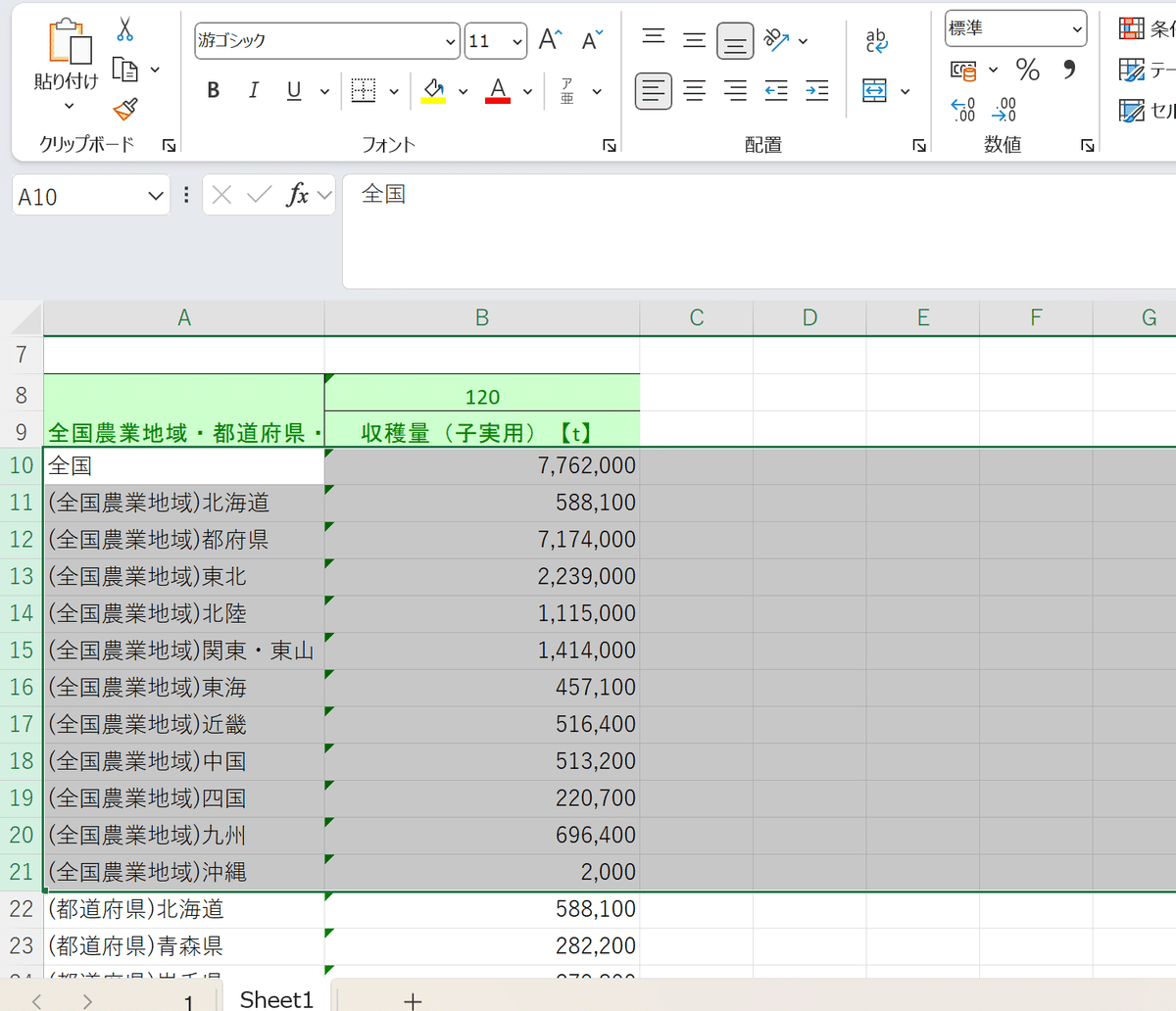
実はこのデータ、一部の県では2回にわたって統計が取られているのです。
それが宮崎、高知、沖縄ですね。しかしその合計数が表示されているので、それぞれの統計は必要ありません。さようならしましょう。

でもctrlキーでまとめて消そうとしたら怒られたので、1行ずつ消す必要アリ。
ここまでできたらまずはExcelを保存しましょう。
次は小麦のデータです。
また同じようにデータを持ってきて、ダウンロードします。
XLSX形式にするのだけは忘れないようにしてください。そしたら同じように収穫量と県名が隣に来るようにしてコピー、別のシートで地域や農政局別のデータを削除しましょう。
それでは、2つのデータを組み合わせていきます。どっちでもいいですが、小麦の方を米のファイルにコピーします。Bの列丸ごとを選択して、米のファイルの、米の収穫量の隣に貼り付けてください。
もしかしたら行がずれるかもしれませんが、慌てずに空いてるマスを削除して上方向に。

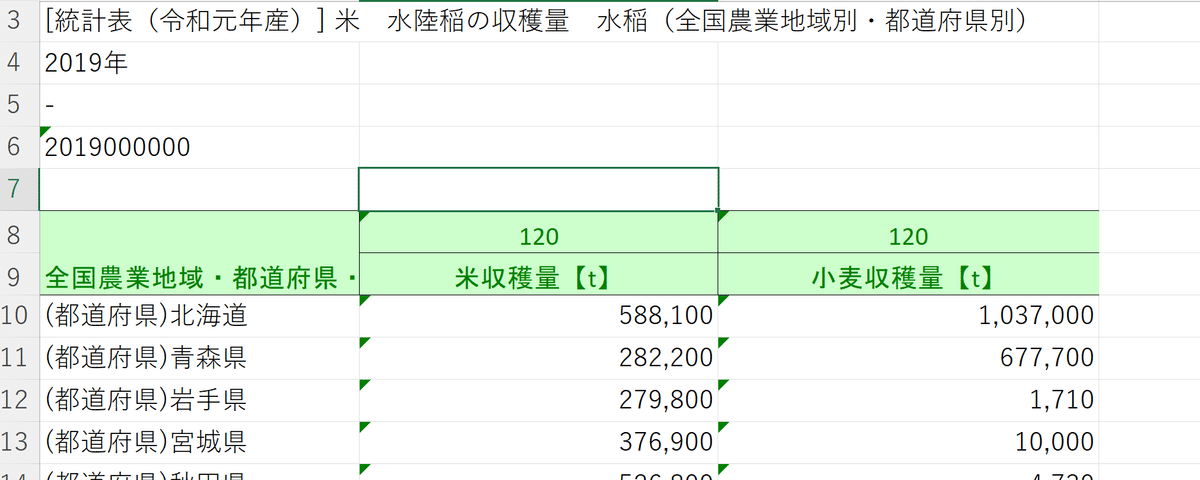
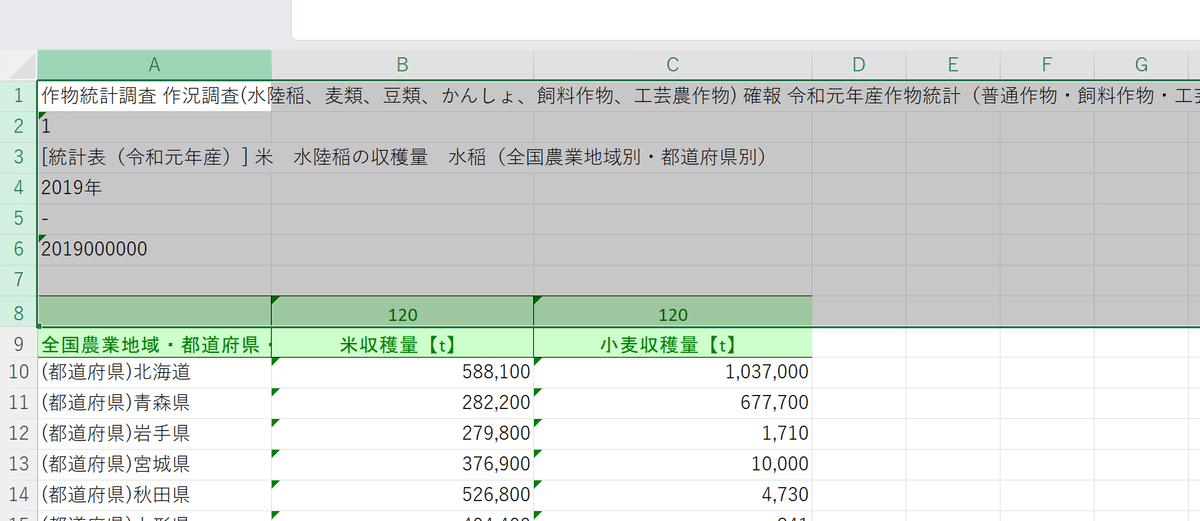
ごめんなさい、ここまでの行程でひとつ誤りがあります。
今小麦収穫量の一番上にある「1037000」という数字、これは全国の数字だったので、ここを削除して1つ上に詰めると完成です。
それでは、この示した部分、データ名等をコピーしましょう。
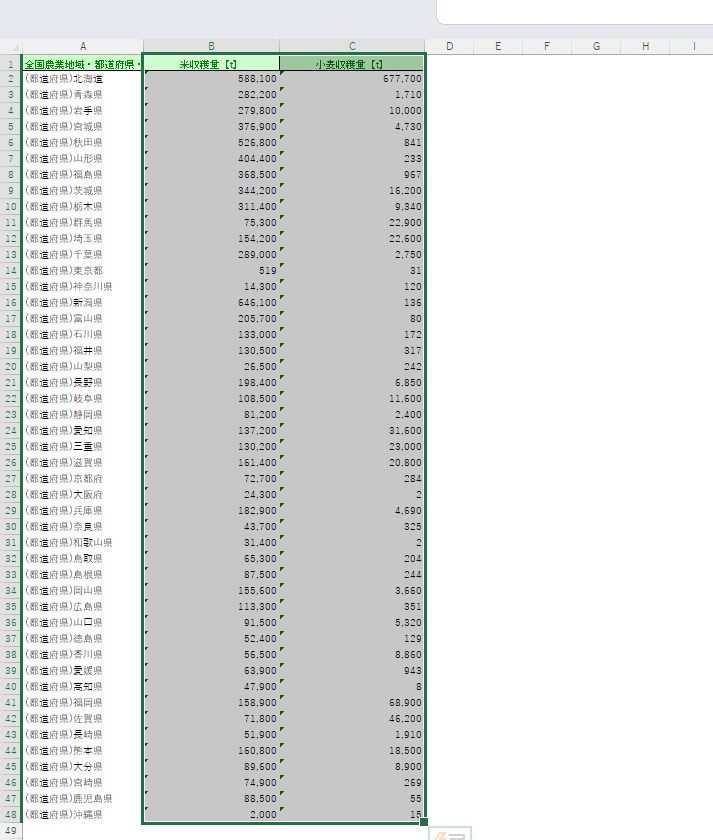
さて、もう一度MANDARA10を開いて、今度はこちらの「編集」から「属性データの編集」に入ります。
↓こんな画面になったら、一番右の10のところにカーソルを合わせ、右クリック。


ここから、先ほどの米と小麦の生産量のデータを入れていきます。
うまくいくと、こうなるはずです。データ名は、その2個上のマスに入れましょう。そうすると準備完了です。
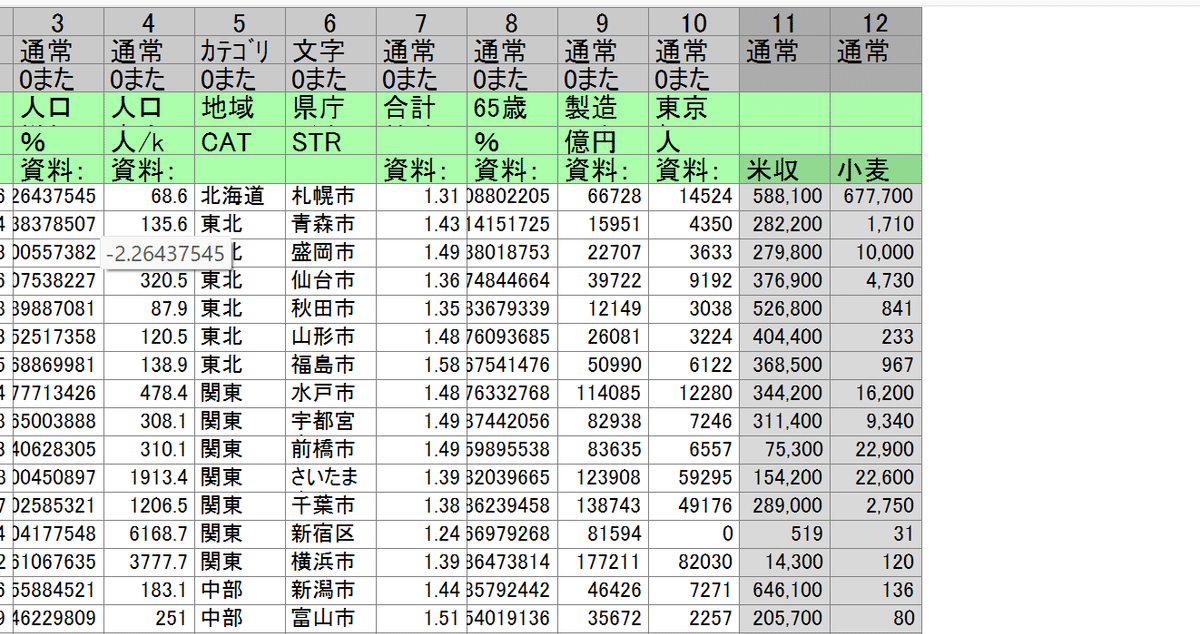
最後に、枠外上真ん中あたりにある「OK」を推して反映されます。

反映されましたね。それでは実際に作っていきましょう。今回は重ね合わせ図ということで、「ペイント」と「ハッチ」を重ねます。なのでペイントの方は何か白黒以外の色を使いたいですね。
まず米ですが、少し特殊な分け方をしますか。学術的にこれが許されるのかは知りませんが、倍、倍、倍といった階級分けをします。あくまで、「どんな都道府県に多いか」という傾向が大事なので許される、という意見もあります。
あとは「カラーチャート」から好きな色を選んでください。オススメは赤のグラデーションか、オレンジと水色のグラデーションですかね。あとでハッチを重ねるので、あんまり濃い色は難しいです。
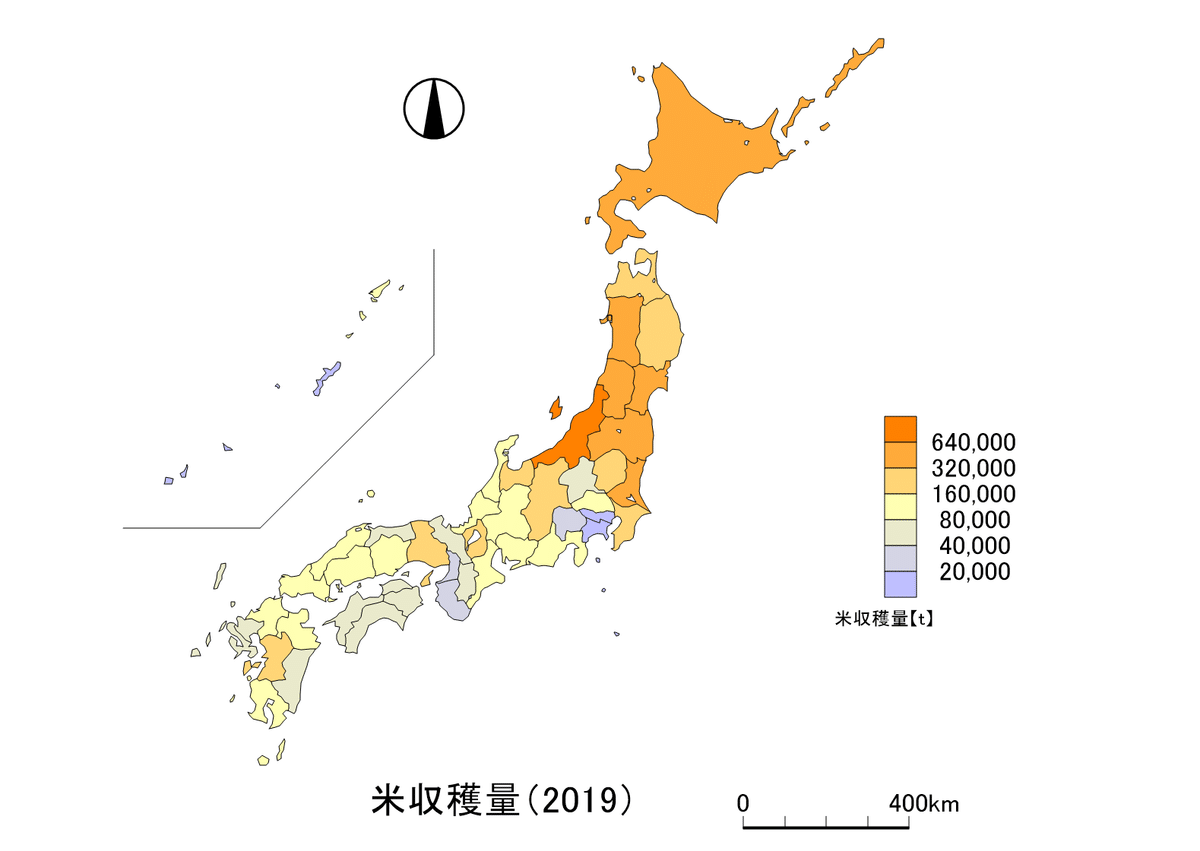
そしたらこれを「重ね合わせセット」を押して保存します。
次は小麦です。基本は同じですが、数値は80000スタートにするといいかもしれません。北海道は外れ値なのであきらめましょう。
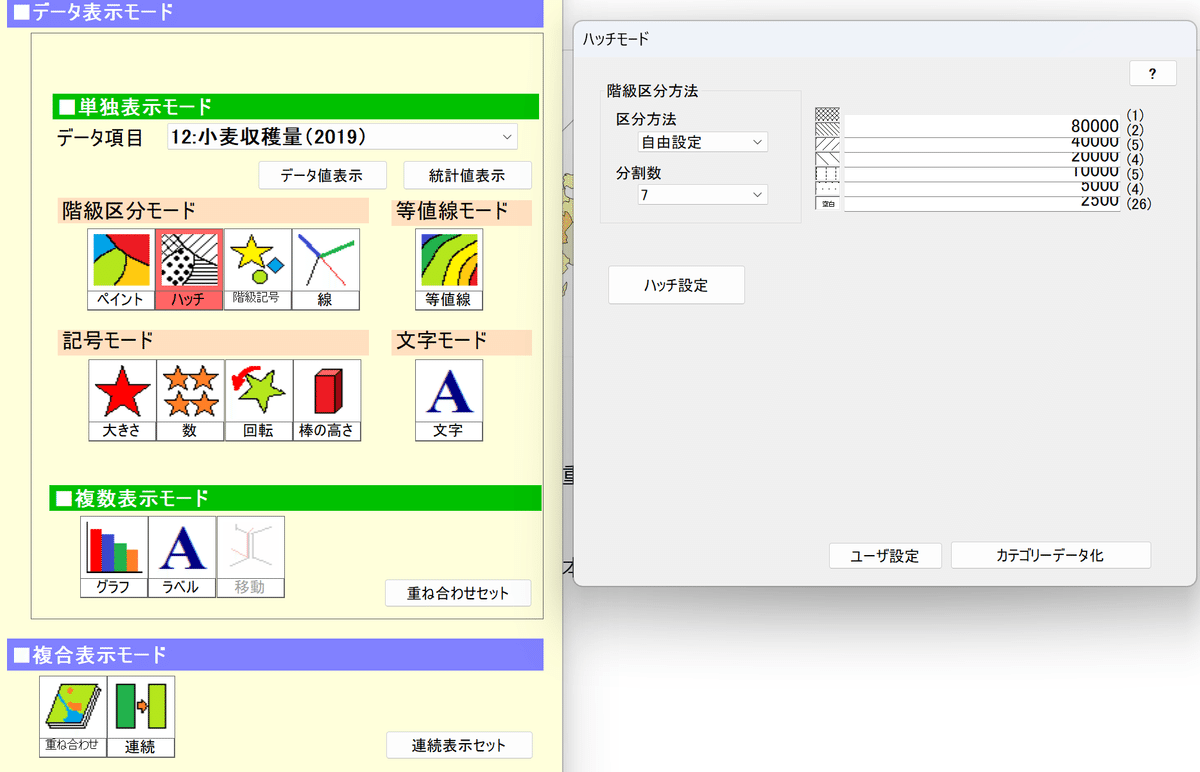
上のような状態になったら、「重ね合わせセット」をクリックしてから、複合表示モードにある「重ね合わせ」をクリックします。
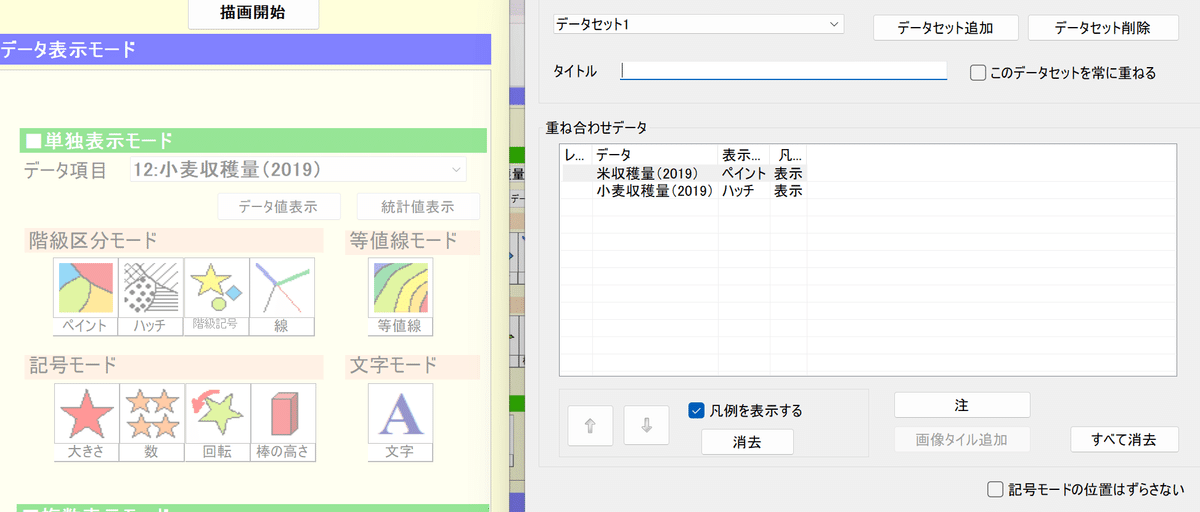
こんな表示になっていたら成功です。あとはタイトルを入力してから「描画開始」を押しましょう。

(タイトルが不適切だけど今回はしーらね)
(本当は凡例をもう少し小さくした方がいいけどもう疲れました)
凡例が被ったりしていたら。ちょっとずらしてあげましょう。
(おまけ)主題図の読み取りをしてみよう
さて、こうしてそれぞれの収穫量を比べてみると何が見えるでしょうか。
まず目を引くのはやはり北海道でしょうか。どちらも多くの収穫量を誇ります。
一方で、米の生産量日本一の新潟県、小麦は真っ白です。
あくまで私の考察ですが、雪が多く降る地域は、秋にまいて春に収穫するのが基本の小麦を栽培するには向かないのだと思います。
そして、雪が多く降る地域はとにかく米。他のことにリソースを割けないのもあるでしょう。
ん?北海道はどうなんだ?と思ったあなた。北海道は外れ値です。気にしたら負けなのです。
答えとしては広いから、というのもあるのですが、実は北海道にも「雪がめっちゃ降る」ところと、「雪が降る」ところがあります。
前者は石狩平野や札幌といった地域、後者は道東と呼ばれる地域です。
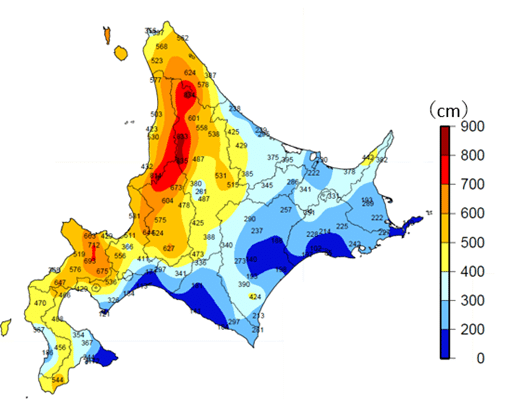
リンク:https://www.data.jma.go.jp/cpd/j_climate/hokkaido/main.html
<閲覧日2024/12/02>
上図の通り、降らないわけではないですが、小麦の品種次第では問題ないらしいです。雪の下に埋まっても腐りにくい品種があるんだとか。
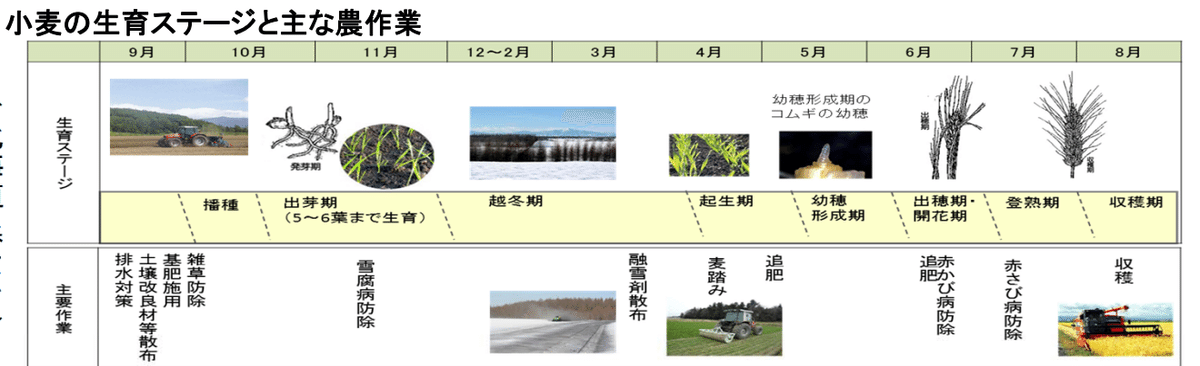
リンク:https://www.maff.go.jp/j/seisan/gijutsuhasshin/techinfo/attach/pdf/komugi-2.pdf
<閲覧日2024/12/02>
特に九州北部や東海などの比較的暖かい地域でどちらの収穫量も多い地域では、二毛作が行われていたりもするみたいです。また、先ほど消したデータのように、もっと南の暖かい地域では、米も2回収穫したりできます。
というように、今回は都道府県+収穫量という分かりやすいデータを使って作業しましたが、MANDARA10ではほかにも市区町村別だったり、他の国だったりでいろんなデータを用いることができます。
もし何かレポートとかを描くときに、階級区分図を使いたいのに見つからない!なんてとき、そのデータを使うのをあきらめてしまうことってありませんか?そういうときに、「そうだ、自分で作ればいいんだ!」と、ひとつ選択肢を増やすことができたら幸いです。
それでは皆さん、テストとか頑張ってください。