
GraphRAGの理解:コストと実装の洞察

データ管理と人工知能の絶え間ない進化の中で、Retrieval-Augmented Generation(RAG)アプリケーションの登場は大きな前進を示しています。この進展において、GraphRAGは情報検索の効率化だけでなく、複雑なデータセットとの相互作用を通じて理解を深める変革的アプローチとして際立っています。
GraphRAGは知識グラフの可能性を活用し、従来の方法では見落とされがちな微妙な洞察や関係性を提供することで、組織のデータ管理方法に革命をもたらしています。
GraphRAGをさらに深く理解するには、その構成要素、実装に伴うコスト、そしてその能力を強調した実用例について詳しく説明することが重要です。
GraphRAGとは?
GraphRAGは、その核心において従来型のRAGシステムに基づいています。一般的なRAGアプリケーションはデータセットから特定情報を取得することに優れていますが、多くの場合、複雑な関係性で満ちた文書全体やデータセット全体の包括的理解には欠けています。ここでGraphRAGが真価を発揮します。
知識グラフ(エンティティ(ノード)とそれらの相互接続(エッジ)を表現した構造)を利用することで、GraphRAGはデータへの全体的視点を提供します。その結果、複雑なデータセットへの理解効率が向上し、同時に有意義な洞察も効果的に抽出できるようになります。
この能力の重要性は過小評価できません。企業が顧客フィードバックからソーシャルメディアの相互作用まで、ますます大規模化する非構造化データに対処する際、この複雑さに対応できる能力は情報に基づいた意思決定に不可欠です。
GraphRAGのコスト内訳
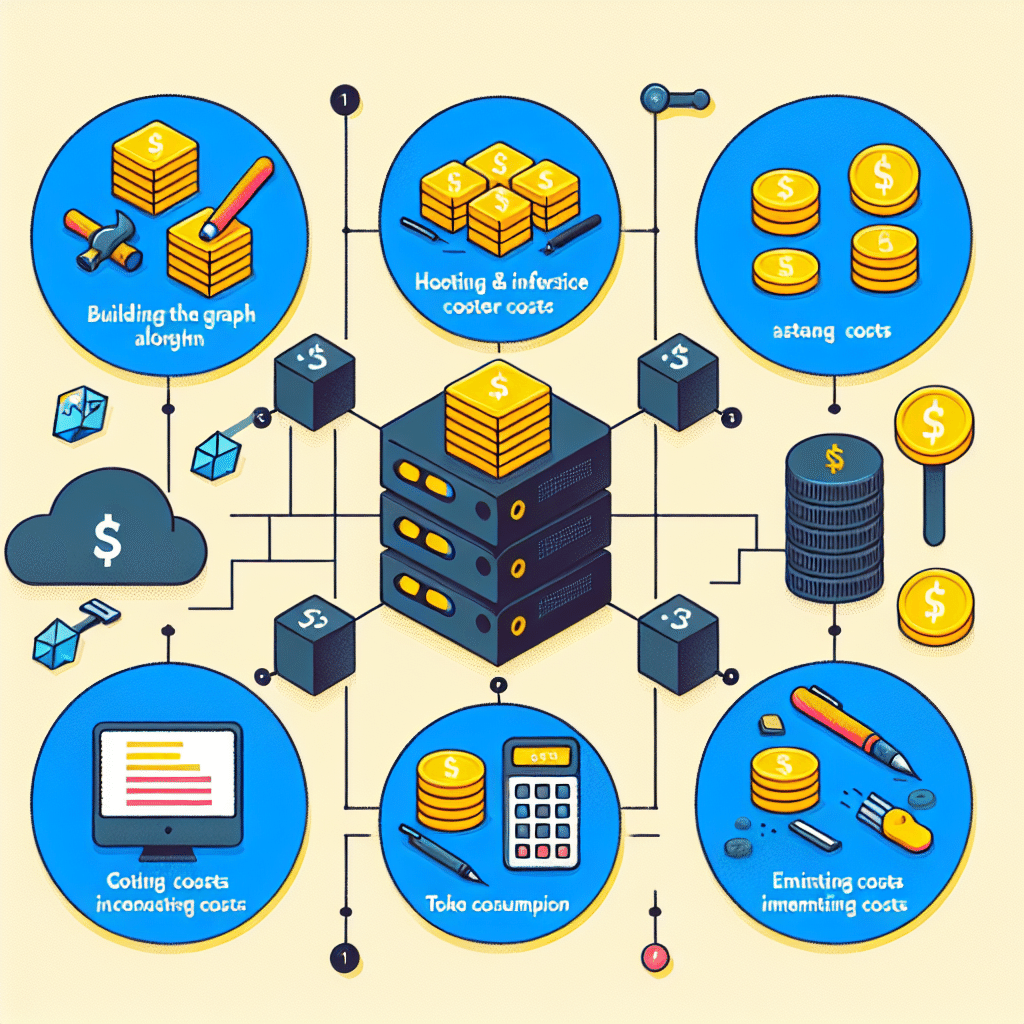
利点が明確である一方で、GraphRAGのようなシステム導入には関連コストも存在します。これらの費用を理解することで、組織はあらゆる技術への投資判断に役立てることができます。
1. グラフ作成
知識グラフ作成には以下のステップがあります:
データ分析:非構造化データソース(テキスト文書やデータベースなど)からノードやエッジを構築する前に、大規模言語モデル(LLM)による広範囲な分析が必要です。この段階ではかなりの時間投資が求められます。
ノード作成:ノードとはデータセット内で異なるエンティティとして表現されるものです。これには在庫管理システム内の商品からHRシステム内の個人まで、様々なものが含まれます。
エッジ定義:エッジはノード間の関係性を示すものであり、それぞれが正確につながり定義されていることが不可欠です。この構造物の形成には労力を要し、初期コストの増加につながります。
2. ホスティングと推論コスト
通常、RAGアプリケーション向けのホスティングソリューションでは、迅速な検索タスクに最適化されたベクトルデータベースが利用されています。ただし、知識グラフ専用のホスティングオプションは業界標準としてはまだ開発途上です。
そのため:
組織ごとの選択技術スタックによって、変動するホスティング料金に直面する可能性があります。
クラウドホスティングかオンプレミスソリューションかを選択する際には、追加のインフラ要件を考慮する必要があります。
3. トークン消費
トークン消費とは、具体的にLLM使用時の推論段階で処理されたトークン数を指します:
従来型の埋め込み手法は、固定表現の運用よりもダイナミッククエリプロセスや多層設計を含む高度な設定下で、低トークン使用傾向を示す傾向があります。
4. コスト見積もり
多くの組織に共通する落とし穴として、一般的な記事や類似事例研究のみに基づいてコスト見積もりを行い、自社特有の特徴を考慮しないことがあります:
正確なベンチマーク算出時には、データ量やサイズなどの諸要因に留意すべきです。
システムの複雑度レベル、
そして展開フェーズ中に第三者統合を通じて生じ得る追加のオーバーヘッドなども考慮が必須となります。
LLMとともに知識グラフを導入

Llama 3.1のようなツールとの統合によって、知識グラフ内部に保存された体系的情報の取得機能が著しく強化されます。これは医療記録や金融取引ログなど、貴重ながら断片的な情報が蓄積された幅広い資料を扱う際に極めて重要な側面といえます。
例えば: 動的クエリ生成を使用することで、ユーザーは静的クエリーのみに依存する場合と比べて、より柔軟な検索が可能になります。
この手法は、LLMsの提供する機能呼び出しをサポートし、既存の設計よりも堅牢な解決策を生み出します—FDA FAERSシステムを通じて直接得られる有害事象報告資料などを含む場合でも対応可能です。
この統合により、精度の改善と応答時間の短縮が促進され、従来のプロセスや人力のみに頼る場合と比べて優れた結果が得られます。
知識グラフの自社設定
実世界の状況を効率よく扱える効果的な知識グラフを構築するためには、適切な技術選択が非常に重要です。
Neo4jは優れた選択肢の一つです。ネイティブなグラフデータベースの構築・保管・管理が整然と行え、関連情報や薬剤反応、患者経験などを密接に結びつける容易さを保証します。
Neo4jの強力な機能を活用することで: 各種関係の追跡や分析を遂行可能なツールにアクセスでき、利用対象の各種データセットを通じて様々な関係性や概念の包括的な把握が可能になります。
Retrieval-Augmented Generationや高度な視覚表現概念の成功環境形成を志向する先駆者たちの枠組みは、周辺に非常に深い影響力を持っています。
今日、多層的で複雑な事象の認識増強を促進するだけでなく、チームが直面する挑戦に対する支援を育み、新しい成果物の生成へと導き、未踏領域の探求や活動の拡張を促進しています。
今後、新たな技術景観の潜在能力を探求し続ける過程で、従来の枠組みを超越する手法の議論に参加することが極めて重要になっていくでしょう。