tabula.read_pdfでPDFから表を抜き出す

tabula.read_pdfでPDFから表を抜き出すのに苦労したので思い出しながらまとめます。
tabula.read_pdfとは
PythonのモジュールでPDFファイルから表を抽出する事ができます。他にもPDFからを読み取るモジュールはありますがtabulaは表の抽出に特化しているらしいです(Dataframe形式で抜き出してくれる)。ただしJavaで開発されているためJavaのインストールが必要です。
環境
OS:Windows10
使用方法
tabulaインストール
コマンドプロンプトを開きtabulaをインストールします。
$ pip install tabula-pyJavaインストール
続いてJavaを公式サイトからインストールします。
https://www.oracle.com/java/technologies/downloads/#java11-windows
何種類かありますがWindowsを使用している方は一番下の「x64 MSI Installer」をダウンロードしてください。「x64 MSI Installer」との違いは拡張子だけです。
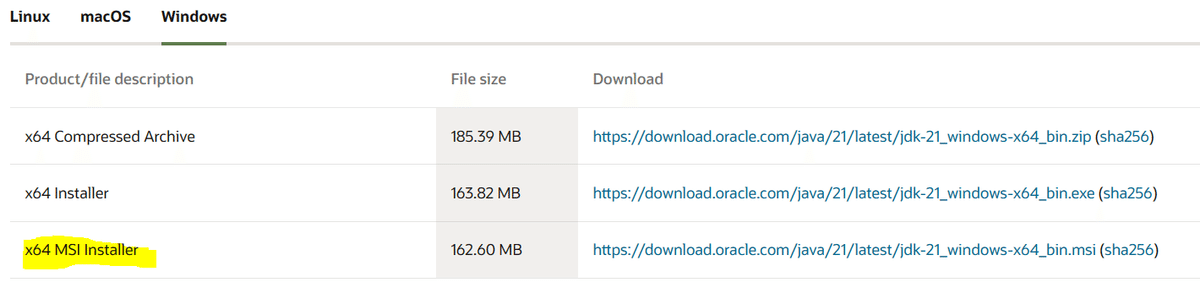
.msiではWindows Installerを使用するためWindows以外の方は「x64 MSI Installer」をダウンロードしてください。(Windows Installerは自動で処理されるのでWindowsの方は何も気にしなくていいです。)msiは「Microsoft Windows Installer」の略です。
次にインストーラーを起動しインストールします。
こんな感じのアイコンをダブルクリックしてください。

必要な項目は最初からチェックされているのですべて「次へ」でインストール完了させてください。
環境変数の設定
Javaをインストールしただけではまだtabulaを使用できません。環境変数を設定する必要があります。設定から「システム環境変数の編集」を開いてください。

次に「環境変数」

新規

ユーザ変数設定

変数名は「JAVA_HOME」。変数値はデフォルトのインストール場所なら「C:\Program Files\Java\jdk-21」のパス(21の部分はバージョンによって異なる)
Pathの編集

Path→編集→新規で「%JAVA_HOME%¥bin」を入力。OKですべて閉じる。
PCを再起動してください。Javaが使用可能になります。私はPCの再起動を忘れて無駄な時間を過ごしました。
tabula.read_pdf使用方法
import pandas as pd
import tabula
data = tabula.read_pdf("PDFのパス", lattice=True, pages='all', pandas_options={'header':None})
print(data)tabula.read_pdf("PDFのパス")でPDFを読み込みます。若干オプションを付けていますが不要であれば削除してください。
表が複数ある場合
PDFの中に表が複数ある場合はリスト形式にして抜き出してくれます。例えばこうです。
リスト[0]→一つ目の表(dataframe型)
リスト[1]→二つ目の表(dataframe型)
データとして管理しにくいPDFもこうすれば表を抜き出すことができます。あとは煮るなり焼くなりお好きにどうぞ。