
BERTとViT、言語とビジョンモデルの比較

BERTとViT(Vision Transformer、ビジョン・トランスフォーマー)はそれぞれ言語とビジョンのモデルだが同じトランスフォーマーのエンコーダをベースにしています。
この記事では、この二つのモデルを比較して共通点と違いを簡単に考察します。
埋め込みベクトルの作り方
相違点
BERTとViTとの1番の違いは埋め込みベクトルを文章から作るBERTに対してViTは画像のパッチから作ります。
BERT
BERTは次の前処理を行い入力文章の埋め込みベクトルを準備します。
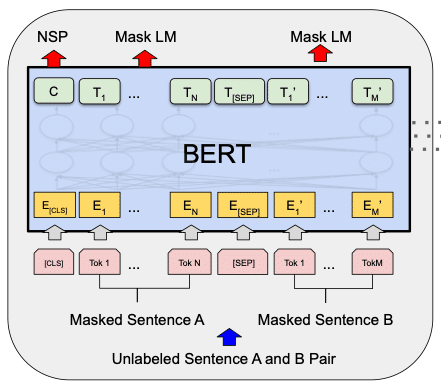
BERTは文章をトークン化します。
各トークンに対して埋め込みベクトルを埋め込みテーブルから取り出します。
位置埋め込みをトークンの埋め込みベクトルに追加(混合)します。
なお、BERTは文章間の関係の特徴を抽出することができるので、二つの文章を区別するためのセグメント埋め込みを追加できます。これはViTにはありません。
ViT
一方、ViTは埋め込みベクトルを画像のパッチから作ります。

画像をパッチに分割します。
画像パッチを線型写像で埋め込みベクトル(パッチ埋め込み)に変換します。
位置の埋め込みをパッチ埋め込みに追加(混合)します。
なお、ViTの位置の埋め込みは1次元と2次元のものが可能ですが、オリジナルの論文ではどちらも差がないので1次元の位置埋め込みを使っています。
共通点
これらの前処理が終わると、BERTもViTも埋め込みベクトルのシーケンス(順番に並んだもの)をエンコーダの入力とするのでトランスフォーマーのアーキテクチャ(アテンションの仕組みなど)からすると基本的に同じ扱いになります。
BERTもViTも分類をするときには、分類用のトークンを入力に加えます。このトークンは特別な埋め込み(訓練中に学習される)で、エンコーダを通して他の埋め込みベクトルのシーケンスからの情報を取り込みます。これが文章の文脈か画像の特徴量かの違いはありますが、トランスフォーマーにしてみれば両方とも数値の羅列でしかありません。
最後に分類用の埋め込みに取り込まれた情報が分類をするための層(線形層など)を通過して判断が下されます。
事前学習とスケーリングの法則
共通点と相違点
BERTもViTもモデルのパラメータを増やすことで性能が向上する傾向があります。これをスケーリングの法則と呼びます。このため、特に巨大言語モデルは基盤モデルとしての発展が近年著しくなっています。
BERTもViTも出来る限り大きなデータセットで訓練をし、それを転移学習やファインチューニングを通して異なるタスクへと利用します。しかし、BERTとViTでは訓練の違いがあります。
BERT
BERTは自己教師あり学習における事前学習を行います。データセットからの文章の一部を隠した部分を予測させる形式の訓練です。マスク言語モデル(Masked Language Model、略してMLM)と呼ばれます。
自己教師あり学習では大量の言語データを扱えるので大きなモデルを訓練するのに向いています。
ViT
ViTは基本的に教師あり学習を行います。よって、BERTなどの言語モデルと比べて大量のデータを利用する点で不利です。自己教師あり学習も試されましたが、オリジナルの論文の段階ではまだ効果があまり出ていませんでした。
しかし、より最近(2023年2月)の論文では220億個のパラメータを持つモデルも登場しています。よって、画像系のトランスフォーマーのモデルもよりスケーリングの法則が成り立つようになることが期待されます。
よって、今年は画像系のトランスフォーマーも注目するべきでしょう。
この記事が気に入ったらチップで応援してみませんか?