
言語AIの進化史⑱トランスフォーマー(自己アテンション機構)

前回は、機械翻訳(Machine Translation)の発展を通して、IBMの統計的機械翻訳からGoogleのトランスフォーマーまでの軌跡を辿っていきました。
特に、2016年に登場したGoogleのGNMT(Google's Neural Machine Translation System)は、それまでのRNN(LSTM)ベースの機械翻訳モデルの集大成でした。
GNMTは、下図のようなエンコーダ・デコーダ構造を持ちます。
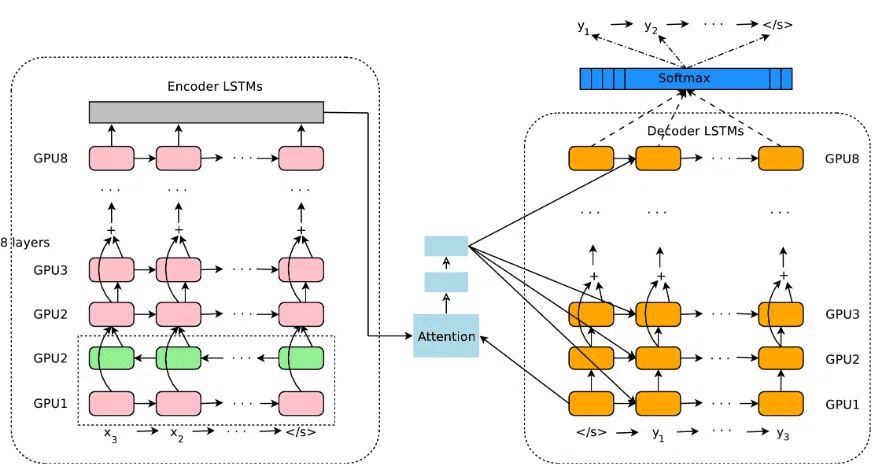
左にエンコーダ、右にデコーダがあります。また、その間にアテンション機構が描かれています。
エンコーダもデコーダも8層に積み重なったLSTMが使われており複雑な特徴を捉えられるようになっています。さらにエンコーダの最下層ではシーケンスを双方向から処理して前後からの文脈を混ぜ合わせています。
デコーダは、アテンション機構を使って、エンコーダが取り出した入力シーケンスの文脈を活用し、各ステップで必要な情報を効率的に取得して出力を生成します。
GNMTの翌年である2017年には、新しい機械翻訳モデルとしてトランスフォーマーが登場しました。
トランスフォーマーもまたエンコーダ・デコーダ構造を持っており、エンコーダとデコーダの間にアテンション機構があります。

ただし、トランスフォーマーでは多層LSTMの代わりにマルチヘッド・アテンションとフィードフォワードが積み重なっています。
なお、トランスフォーマーの詳細は、これまでたくさんの記事で解説しています。
今回は、GNMTとの違いやその後のアテンションの発展を追いながらトランスフォーマーがなぜこのような構造になったのかを考察します。
この記事が気に入ったらチップで応援してみませんか?