
深層生成モデル

学習目標
生成モデルにディープラーニングを取り入れた深層生成モデルについて理解する。
生成モデルの考え方
変分オートエンコーダ(VAE)
敵対的生成ネットワーク(GAN)
キーワード:ジェネレータ(生成器)、ディスクリミネータ(識別器)、DCGAN、Pix2Pix、CycleGAN
生成モデルの考え方
生成モデルとは画像のデータの分布を推測し、その分布に従って画像をサンプリングすることができるものです。ディープラーニングによって生成モデルはより複雑な画像・データを生成することができるようになりました。これを深層生成モデルと呼びます。
画像の生成では訓練データから画像がもつ潜在空間を学習します。潜在空間は画像を生成するのに必要な情報の空間です。生成する画像データよりも小さいサイズのベクトルに格納されます。その潜在空間の一点がある画像に対応するのですが、潜在空間には無数の点があるのでサンプルすることで毎回新しい画像が生成されるようになります。
深層生成モデルには二つのよく知られたアプローチがあります。
変分オートエンコーダ(Variational AutoEncoder, VAE)
敵対的生成ネットワーク(Generative Adversarial Network, GAN)
変分オートエンコーダ(VAE)
VAEは入力と出力が同じになるように訓練されるという意味でオートエンコーダの一種です。しかし、以前に取り扱ったオートエンコーダは最終的には教師あり学習で使われるための特徴量を抽出したりするものであって、生成モデルではありませんでした。ここで扱うVAEはエンコーダとデコーダのある生成モデルです。
VAEのエンコーダは入力の圧縮を行うのではなく、潜在変数の分布の平均と分散を予測します。また、潜在変数はこの平均と分散を持つ正規分布に従うようにエンコーダが訓練されます。潜在変数はベクトルなので複数の変数の分布があり、それらの分布からサンプルされた潜在変数をデコーダに渡すと画像が出力されます。

敵対的生成ネットワーク(GAN)
敵対的生成ネットワーク(Generative Adversarial Network, GAN)には生成器であるジェネレータ(generator)と識別器であるディスクリミネータ(discriminator)があります。
ジェネレータは画像を生成するネットワークでランダムなベクトルを入力とします。しかし、そこには正解画像はありませんし、オートエンコーダのように入力と出力を同じにする学習でもありません。実は、ジェネレータによって生成された画像はディスクリミネータによって本物かどうか判別されます。つまり、ディスクリミネータが損失関数の役割をになっています。
ただ、ディスクリミネータ自体も訓練される必要があるので、本物の画像と偽物(ジェネレータによって生成されたもの)を交互の与えて真偽の判断を学習させます。このようにして、ジェネレータとディスクリミネータが順番に訓練されていくと、ジェネレータはディスクリミネータを欺くほど本物らしい画像を生成できるようになります。また、ディスクリミネータも本物と偽物の判断が上手になっていきます。
まるでジェネレータとディスクリミネータが敵対するような学習方法で生成ネットワーク(ジェネレータ)を訓練するので敵対的生成ネットワークと呼ばれています。
DCGAN
DCGANはGANに畳み込みを採用しより画像の生成がクオリティの高いものになったものです。

Pix2Pix
Pix2PixはGANに条件画像と正解画像を与えたもので条件付きGANの一種です。ジェネレータは条件画像を与えられ画像を生成します。ディスクリミネータは条件画像と本物あるいは生成された画像を見て画像が条件画像に対応する本物かどうかを判断できるように訓練されます。
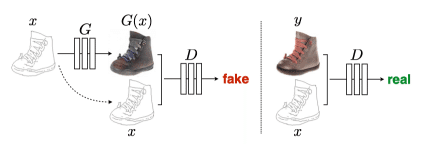
CycleGAN
CycleGANは馬の画像からシマウマの画像へ変換したり、その逆方向(シマウマから馬)の変換をするデモで有名です。
CycleGANは簡単にいうとpix2pixを双方向にしたものです。よって2つのジェネレータを持ちます。馬の画像を条件にシマウマの画像を生成するジェネレータ(F)とシマウマの画像を条件に馬の画像を生成するジェネレータ(G)です。
訓練されたジェネレータFが生成したシマウマを訓練されたジェネレータGに入力すれば馬の画像になります。

ジェネレータFとジェネレータGにはそれぞれにディスクリミネータがあり、合計4つのネットワークを交互に訓練します。
CycleGANの良いところはpix2pixと違って条件画像と出力画像のペアを用意する必要がありません。たくさんの馬の画像とたくさんのシマウマの画像があればよく、ピッタリとしたペアを必要としないのは、2つのディスクリミネータが本物らしさの判断をしているだけだからです。
参照
この記事が気に入ったらチップで応援してみませんか?