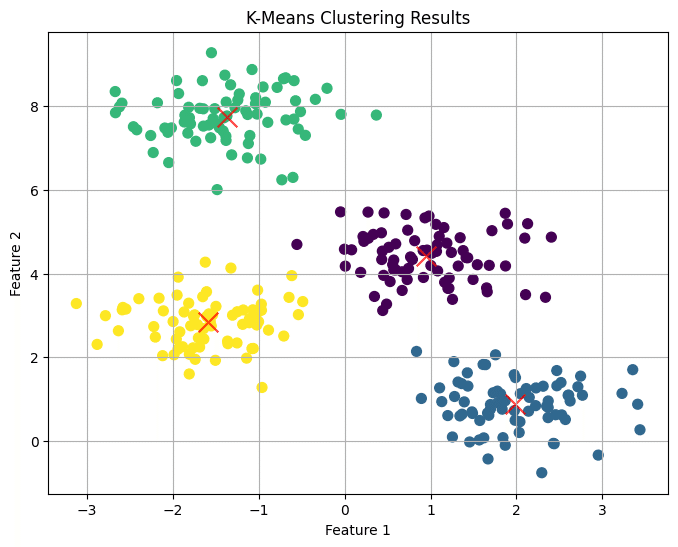
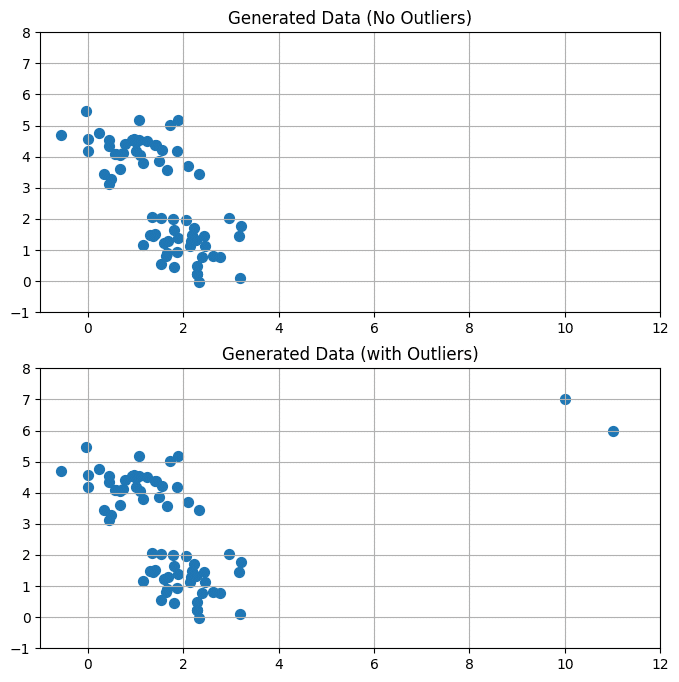
scikit-learn機械学習㉚k-means実践編 澁谷直樹 @ キカベン 2024年11月5日 11:06 前回は、k-meansの仕組みを紹介しました。今回は、scikit-learnのKMeansを使った実験を行います。このようのデータを生成し、k-meansでクラスタリングを行います。また、最適なクラスタ数$${k}$$を決めるために、エルボー法やシルエット係数を試してみます。さらに、k-means が苦手なケースとして複雑な境界線を持つデータを試します。そして、k-means に対する外れ値の影響も調査します。どんな結果になるでしょうか。さっそく始めましょう。 ダウンロード copy ここから先は 7,828字 / 11画像 キカベン・読み放題 ¥1,000 / 月 初月無料 アルゴリズム、機械学習、深層学習、強化学習、量子技術をわかりやすく すべての記事とマガジンが読み放題 メンバー限定の会員証が発行されます 活動期間に応じたバッジを表示 メンバー限定掲示板を閲覧できます メンバー特典記事を閲覧できます メンバー特典マガジンを閲覧できます このメンバーシップの詳細 ログイン #kmeans #エルボー法 #シルエット係数 #kmeans_plus この記事が気に入ったらチップで応援してみませんか? チップで応援