
分類AIの進化史①パーセプトロン

2012年にディープラーニングは画像分類で大成功を収めました。しかし、それよりもずっと以前である1958年に、シンプルながらも重要な「パーセプトロン」モデルが発表されました。
AIの歴史の中でも初期の頃に登場した分類モデルであり、二項分類問題(二つのカテゴリーにデータを分ける問題)を対象としています。
また、パーセプトロンは、ニューラルネットワークの一種であり、複数の入力値を受け入れて一つの値を出力します。その基本的なアイデアは、後に登場する複雑なモデルやディープラーニングにも影響を与えました。
しかし、そもそもニューラルネットワークで分類を行うとはどういうことなのでしょうか。研究者たちは、どこからヒントを得てパーセプトロンを開発したのでしょうか。
単純パーセプトロン
パーセプトロンは、人間の視覚と脳が情報を処理する機能をモデル化したものです。つまり、視覚からの入力データに対してどの情報がより重要なのかを考慮して、脳内の神経系統がシグナルを発信するような仕組みを考えました。いわゆるニューラルネットワーク(神経回路)です。
パーセプトロンのアイデア自体は1943年からありましたが、実装を行なったのはアメリカの心理学者フランク・ローゼンブラットでした。有名なAI国際会議であるダートマス会議が行われた数年後の1958年のことです。第1次AIブームの真っ最中でもありました。
最も単純なパーセプトロンは、入力層と出力層のみの2層から構成されています。
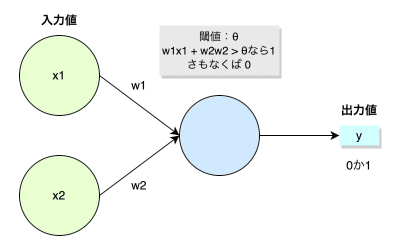
2つの入力値$${x_1, x_2}$$から出力値$${y}$$として0か1を返します。それぞれの入力値に重み$${w_1, w_2}$$が掛けられます。
$$
y = w_1 x_1 + w_2 x_2
$$
この出力値$${y}$$がある閾値$${\theta}$$を越えたならば1(真)、さもなくば0(偽)の判断をします。その基本的な仕組みはロジスティック回帰と同等です。
まとめると、ニューラルネットワークで分類を行うとは「入力データから何が重要なものであるのかを見極めること」によって行われました。そのために、判断に重要な入力値には大きい重み、そうでないものには小さい重みを使って特徴量として計算します。最終的な出力された値を|閾値《 しきいち》と照らし合わせることで分類を行います。
しかし、当時はパソコンもありませんので、人工知能を実装するとはハードウェアを開発することが必要であり、実現までに時間がかかりました。
Mark I パーセプトロン
まず、フランク・ローゼンブラットは、IBM 704を使ってパーセプトロンのシミュレーションを行いました。その後、独自のハードウェアとしてMark I パーセプトロンを開発しました。

このマシンは、20×20 個の光を電気に変換する装置(カメラ)を備えており、合計で400ピクセルの画像を入力として扱うことができました。 入力データのさまざまな組み合わせを設定するためのパッチパネルがあります。
分類が出来るとは、つまりは判断ができるということであり、もっと複雑化すれば人間のような知能が可能になるのではないか、そんな期待が膨れたようです。
ローゼンブラットはかなり自信を持っていたようで、彼の発言に基づいて、ニューヨーク・タイムズ紙は、パーセプトロンのことを「電子コンピュータの胎児」と呼び、人間のように振る舞えるようになると海軍が期待しているとまで報じたほどでした。
[海軍]が期待している電子コンピュータの胎児は、歩き、話し、見、書き、複製し、その存在を認識できるようになるだろう。
the embryo of an electronic computer that [the Navy] expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence.
今でいうハイプですが、期待感は相当高まっていたようです。
ただし当時は、まだ誤差逆伝播法も勾配降下法も知られていなかったので、値を調節しながら反復して問題を解くというものでした。また、非線形な問題も扱うことができませんでした。当然、今日のディープラーニングからは程遠いものでした。
そのため、1969年にマービン・ミンスキーとシーモア・パパートが単純なパーセプトロンは線形に分離可能なパターンしか識別できない事を発表します。これが第1次AIブームの熱が冷めるきっかけを作ったと言われています。また、研究費に対して成果が出ていないことから投資も激減しました。
そして、AIの冬の時代が訪れました。
当時の機械学習
この当時はAIというよりも、機械学習と呼ばれるアルゴリズムが盛んに提案されていました。ただし、AIや機械学習という言葉の区別は人や時代によって異なります。
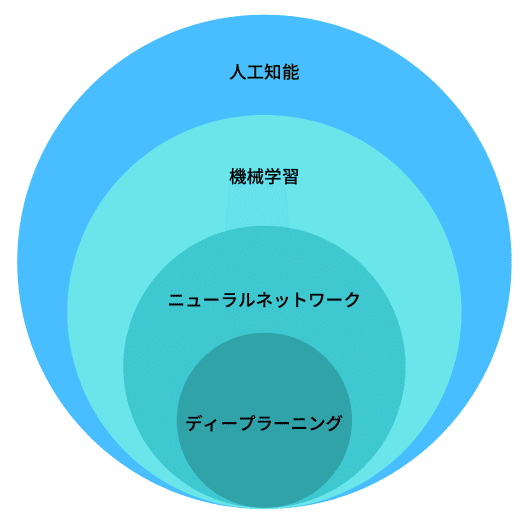
人工知能(Artificial Intelligence)という言葉自体は、ダートマス会議から使われ始めたものですが、広義の意味を持ち、曖昧でもあります。機械学習はその一部として考えられ、さらにニューラルネットワークから多層化したディープラーニングへと進化していくイメージです。
ただし、最近ではディープラーニングとAI(人工知能)が同義語のようにも使われているので、結局のところ曖昧な意味しか持たず、一周回ってまた元に戻っているような感じです。
当時の機械学習の例を挙げると、パーセプトロンと同年にロジスティック回帰が発案されています。また、1963年には、決定木(Decision Tree)や線形のサポートベクトルマシン(Linear SVM)が登場しています。1967年にはk-平均法(k-means)というクラスタ分類の手法も現れました。
このような機械学習は、ディープラーニングが全盛期になる以前はKaggleなどの機械学習コンペなどで、よく使われていました。また、少ないデータでも効果的に使えることがあることから現在でもデータサイエンティストなどによって使用されています。
ただし、多くの機械学習は、人間がアルゴリズムや実装を細部まで考える必要がありました。画像処理におけるエッジ検出などコンピュータビジョンではさまざまな工夫による特徴量抽出の技が編み出されました。
もちろんディープラーニングの登場によって、特徴量の抽出が自動的に学習されるようになるのですが、1958年に単純なパーセプトロンが登場した当時ではまだ長い道のりが残っています。
そして、ニューラルネットワークに対しては、長いこと冬の時代が続きました。誤差逆伝播法や勾配降下法がまだありませんでしたし、ディープラーニングのモデルを訓練するための巨大なデータセットもコンピューティング力もありませんでした。
そうは言っても、ニューラルネットワークの研究は綿々と続いていました。
多層パーセプトロン
単純パーセプトロンの限界を克服するために、ニューラルネットワークに隠れ層を追加したものを多層パーセプトロンと呼びます。
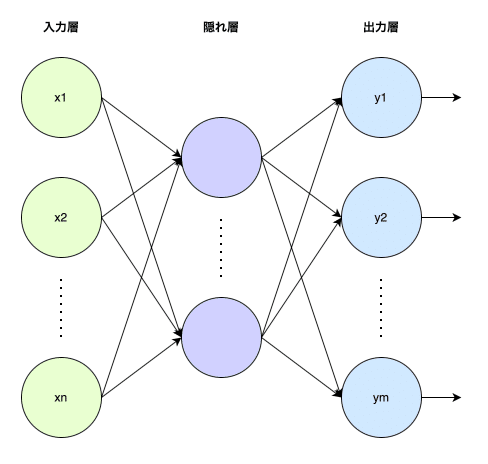
英語ではよくMLP(Multi-Layer Perceptron)と呼ばれます。現在でも線形の隠れ層を含む多層の部分をMLPと呼ぶことがあります。
実は、フランク・ローゼンブラット自身もMLPを考えていました。ただし、効果的に訓練する方法がわかっていませんでした。また、当時のMLPは隠れ層が一つだけであり、ディープニューラルネットワークではありません。
冒険は始まったばかり
ディープラーニング的なものが現れるのは1965年まで待つ必要があります。そして、勾配降下法はさらにその後になります。また、分類AIが進化するにつれて新たな問題やチャレンジも生まれていきます。
当時の研究者たちは知りませんが、今日のAIのレベルに達するには、まだ50年以上の絶え間ない努力と技術の進歩が必要でした。
(続く)
この記事が気に入ったらチップで応援してみませんか?