
そもそもニューラルネットワークとは

この記事では、ニューラルネットワークをより一般的にニューロンや活性化関数といった概念を通して理解することを目的とした解説をします。
基本的なニューラルネットワークとして線形回帰やロジスティック回帰がありますが、両方とも共通の枠組みを通して理解することができます。
この記事では扱いませんが、畳み込みニューラルネットワークや再帰型ニューラルネットワークやトランスフォーマーなどを理解するための土台となる仕組みがニューラルネットワークとその学習手法にあります。
さらに、この記事を読むことによって、次のことが理解できるようになります。
ニューラルネットワークとは何か
なぜ活性化関数が必要なのか
ディープニューラルネットワークとは何か
では、さっそく始めましょう。
生物学的神経回路
生物学的神経回路(生物学的ニューラルネットワーク、Biological Neural Network)とは、生物の脳内に存在する神経細胞(ニューロン)が形成する複雑なネットワークを指します。これらのニューロンは電気的な信号などを受け取り、処理し、伝達することにより、我々が感じ、思考し、行動する能力をもたらします。

イメージとしては、外部からの刺激などから入力を受けてニューロンが信号を増幅したり低減させたりして次のニューロンへと伝えていきます。これが計算の役割を果たしており、複雑に接続されたニューロン達が全体で意味のある計算をしていると考えられています。
ただし、実際には脳内ニューロンの仕組みや働きは完全に解明されているわけではありません。それでも、生物学的ニューロンはその接続の強さを調節することで複雑な計算を行えるという認識が発端となり人工的神経回路の考えを生間れました。
人工的神経回路
人工神経回路の考え方は、1943年のウォーレン・マカロックとウォルター・ピッツの論文から始まりました。彼らは、生物学的ニューロンの動作を単純化した数学的モデルを提案し、これが現代の人工神経回路網(人工神経ネットワーク、人工ニューラルネットワーク、Artificial Neural Network)の開発の基礎を形成しました。
この論文では、彼らは脳内でニューロンがどのように機能するかについての単純化された計算モデルについて説明しています。それは各ニューロンがその入力に対して単純な計算を実行し、他のニューロンに送信される出力を生成するというものです。
1958年にアメリカの心理学者フランク・ローゼンブラットがこのモデルを最初に実装しました。パーセプトロン(Perceptron)という名前で知られています。
最も単純なパーセプトロンは、入力層と出力層のみの2層から構成されています。下図はその具体例です。2つの入力値から出力値として0か1を返しています。

つまり、2つの入力値$${x_1}$$と$${x_2}$$のそれぞれに重み$${w_1}$$と$${w_2}$$を掛けてから足し合わせたものが閾値$${\theta}$$より大きいかどうかで出力値として0か1を返します。
$$
w_1 x_1 + w_2 x_2 > \theta \\
\\
条件成立なら1\\
条件不成立なら0
$$
実は、単純なパーセプトロンでは、解ける問題に限界があります。1969年にマービン・ミンスキーとシーモア・パパートが単純パーセプトロンは線形分離可能なパターンしか識別できない事を示しました。この後、第1次AIブームの熱が冷め、冬の時代になったと言われています。
このように人工ニューラルネットワークは、生物学的神経回路の構造と機能を模倣したコンピュータモデルの一種です。よって、生物学的神経回路を再現しているわけではありません。脳内ニューロンの仕組が完全には分かっていないので当然ではありますが。
人工ニューロン(またはノード)は、生物学的ニューロンと同様に、受け取った値を増幅したり低減させたりして次のニューロンへ伝達します。人工ニューロンは、入力値を受け取り、重み付けされた入力値の和を計算し、さらに活性化関数を適用して(しない場合もあります)出力値を生成します。
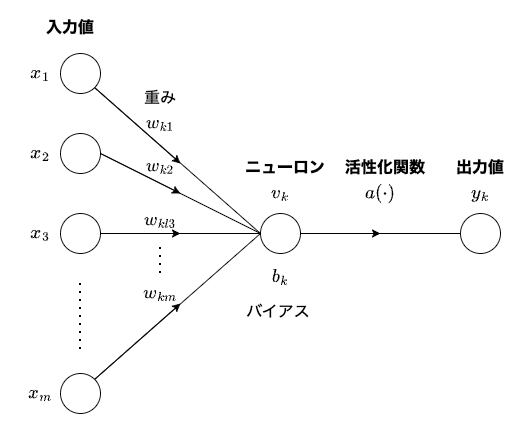
上図では、入力値$${x_1, x_2, x_3, \dots, x_m}$$が$${k}$$番目のニューロンへ渡されています。その際に、各入力値に重み$${w_{k1}, w_{k2}, w_{k3}, \dots, w_{km}}$$が掛け合わせられます。これがニューロンへの接続の強さになります。重みの絶対値が大きいほど反応が大きくなります。
また、さらにニューロンにバイアス$${b_k}$$が追加されます。数式で書くと以下になります。
$$
v_k = w_{k1} x_1 + w_{k2} x_2 + w_{k3} x_3 + \dots + w_{km} x_m + b_k = \sum\limits_{i=1}^m w_{ki} x_i + b_k
$$
なお、重みとバイアスをまとめて人工ニューラルネットワークのパラメータと呼びます。
上記の式を行列で表記すると以下になります。
$$
v_k = \begin{bmatrix}
w_{k1} & w_{k2} & \dots & w_{km}
\end{bmatrix}
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_m
\end{bmatrix}
+ b_k
$$
ここまでは線形の計算になっています。複数の変数がありますが、やっていることは掛け算と足し算です。
活性化関数がない場合は、これが出力値となります。
活性化関数がある場合は、値$${v_k}$$を活性化関数$${a(\cdot)}$$に通して非線形性を導入したものが出力値となります。
$$
y_k = a(v_k)
$$
後で解説しますが、活性化関数はReLUやSigmoidなど非線形の計算をするので線形の計算だけでは実現できない複雑な表現をすることが可能となります。
通常、ニューロンは複数あり、各ニューロンに対して全て同じ入力値が与えられます。入力値から各ニューロンへの接続の強さは各ニューロン独自の重みで与えられています。

よって、説明が繰り返しにはなりますが、$${v_k}$$の計算では、$${k}$$番目に特有な重み$${w_{k1}, w_{k2}, w_{k3}, \dots, w_{km}}$$とバイアス$${b_k}$$が使われています。
$$
v_k = \sum\limits_{i=1}^m w_{ki} x_i + b_k \quad (k = 1 \dots n)
$$
こうすることで各ニューロン$${v_1, v_2, \dots, v_n}$$は同じ入力値$${x_1, x_2, \dots, x_m}$$に対する異なる反応を数値として表現しています。
これを行列で表すと以下になります。
$$
\begin{bmatrix}
v_1 \\
v_2 \\
\vdots \\
v_n \\
\end{bmatrix} = \begin{bmatrix}
w_{11} & w_{12} & \dots & w_{1m} \\
w_{21} & w_{22} & \dots & w_{2m} \\
\vdots & \dots & \vdots \\
w_{n1} & w_{n2} & \dots & w_{nm}
\end{bmatrix}
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_m
\end{bmatrix}
+
\begin{bmatrix}
b_1 \\
b_2 \\
\vdots \\
b_n
\end{bmatrix}
$$
$${m}$$個ある入力値に対して$${n}$$個のニューロンがあると、$${m \times n}$$個の重みと$${n}$$個のバイアスが必要となります。
だんだん長ったらしくなってきたのでベクトルと行列の記号で置き換えます。
$$
\boldsymbol{v} =
\begin{bmatrix}
v_1 \\
v_2 \\
\vdots \\
v_n \\
\end{bmatrix}
$$
$$
W = \begin{bmatrix}
w_{11} & w_{12} & \dots & w_{1m} \\
w_{21} & w_{22} & \dots & w_{2m} \\
\vdots & \dots & \vdots \\
w_{n1} & w_{n2} & \dots & w_{nm}
\end{bmatrix}
$$
$$
\boldsymbol{x} =
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_m
\end{bmatrix}
$$
$$
\boldsymbol{b} = \begin{bmatrix}
b_1 \\
b_2 \\
\vdots \\
b_n
\end{bmatrix}
$$
これで次のように簡単に表現できます。
$$
\boldsymbol{v} = W \boldsymbol{x} + \boldsymbol{b}
$$
$${W}$$を重み行列と呼びます。
活性化関数まで含めると以下になります。
$$
\boldsymbol{y} = a(W \boldsymbol{x} + \boldsymbol{b})
$$
この際、活性化関数$${a}$$は$${\boldsymbol{v}}$$の各要素に対して計算されます。つまり、以下の関係が成り立ちます。
$$
\begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{bmatrix} =
a\left(\begin{bmatrix}
v_1 \\
v_2 \\
\vdots \\
v_n
\end{bmatrix}\right) =
\begin{bmatrix}
a(v_1) \\
a(v_2) \\
\vdots \\
a(v_n)
\end{bmatrix}
$$
このように活性化関数は常に要素ごとに計算されます。
さらに、この一連のニューロンを一つの層と考えると、何層にも重ねることで人工ニューラルネットワークの深みが増していきます。

層を重ねることでニューロンによるさまざまな反応が複雑に重なり合って入力値に潜む特徴を数値で表現できるようになります。
これが人工ニューラルネットワークです。生物学的ニューラルネットワークと誤解がない限りは、単にニューラルネットワークと呼びます。
なお、入力層と出力層以外を隠れ層と呼びます。そして、隠れ層は通常必ず活性化関数を持ちます。理由については後述します。
行列とベクトルで上図を表記すると次のようになります。
まず、最初の隠れ層の出力はこうなります。
$$
\boldsymbol{h}^{(1)} = a^{(1)}(W^{(1)} \boldsymbol{x} + \boldsymbol{b}^{(1)})
$$
右上にあるカッコ付きの番号は層の位置を意味します。この隠れ層は、入力層の後の一番最初なので$${\boldsymbol{h}^{(1)}}$$となっています。また、重み行列やバイアスにも同様の番号が振られています。
これを受けて、次の隠れ層の出力はこうなります。
$$
\boldsymbol{h}^{(2)} = a^{(2)}(W^{(2)} \boldsymbol{h}^{(1)} + \boldsymbol{b}^{(2)})
$$
最終的な出力は活性化関数がないとすると次のようになります。
$$
\boldsymbol{y} = W^{(3)} \boldsymbol{h}^{(2)} + \boldsymbol{b}^{(3)}
$$
そうによってニューロンの数が異なれば、重み行列の要素数も変わります。また、バイアスの要素数も重み行列の行数に従います。
以上で、ニューラルネットワークがどのように計算を行うのかの解説になります。
活性化関数が必要な理由
隠れ層では活性化関数が必要です。その理由を知るために次のようなニューラルネットワークを考えます。話を単純にするためバイアスは省略します。
$$
\begin{aligned}
\boldsymbol{h}^{(1)} &= W^{(1)} \boldsymbol{x} \\
\boldsymbol{y} &= W^{(2)} \boldsymbol{h}^{(1)}\\
\end{aligned}
$$
まとめると、
$$
\boldsymbol{y} = W^{(2)} W^{(1)} \boldsymbol{x}
$$
ここで、$${W^{(2)} W^{(1)}}$$は行列と行列の席なのでまた、行列になります。
簡単な具体例を使って計算してみましょう。入力値のベクトルの要素数が2だとします。そして、隠れ層の出力ベクトルの要素数も2とします。
$$
W^{(1)} = \begin{bmatrix}
1 & 2 \\
3 & 4
\end{bmatrix}
$$
$$
W^{(2)} = \begin{bmatrix}
4 & 3 \\
2 & 1
\end{bmatrix}
$$
よって、
$$
\begin{aligned}
W^{(2)} W^{(1)} &= \begin{bmatrix}
4 & 3 \\
2 & 1
\end{bmatrix}\begin{bmatrix}
1 & 2 \\
3 & 4
\end{bmatrix} \\
&= \begin{bmatrix}
13 & 20 \\
5 & 8 \\
\end{bmatrix}
\end{aligned}
$$
よって、二つの隠れ層は一つの層として表現することが可能です。バイアスがあっても同様です(計算が長くなるだけです)。
つまり、非線形性を導入する活性化関数が無いと、隠れ層を複数に分けて考えることに意味がありません。よって隠れ層では活性化関数が必要です。
なお、最後の出力層では、活性化関数はなくともかまいません。これはモデルの目的によって変わってきます。その例として線形回帰とロジスティック回帰を見ていきましょう。
線形回帰モデル
最も単純な線形回帰は一つの入力値を受け、一つの出力値を生みます。また、隠れ層はありません。詳しくはこちらでも解説しています。
$$
y = a x + b
$$
これも要素が一つのベクトルと行列と見ればニューラルネットワークの枠組みで理解できます。また、隠れ層がないので非線形な活性化関数もありません。
もちろん、線形モデルを複数変数に拡張することは可能です。
$$
y = W \boldsymbol{x} + b
$$
さらに、出力が複数であるケースも考えられます。
$$
\boldsymbol{y} = W \boldsymbol{x} + b
$$
なお、何らかの特徴量を抽出するために一つ以上の隠れ層を導入して最終的には線形層から出力するケースもあります。
もっと複雑なケースでは、畳み込みニューラルネットワークなどは典型的な例です。ただし、そこまでくると線形回帰モデルとは呼ばなくなります。
ロジスティック回帰モデル
最も単純なロジスティック回帰では、一つの入力値を受け、一つの出力値を生みます。また、隠れ層はありません。しかし、出力層にシグモイド関数を使って非線形な計算を行なっています。詳しくは、こちらでも解説しています。
ニューラルネットワーク
線形回帰やロジスティック回帰はニューラルネットワークの一種として捉えることが可能です。それは、ニューロン、重み行列、バイアス、活性化関数といった概念で仕組みを理解できるからです。
ただし、簡単な線形回帰の問題などは解析的にも解けてしまいます。そのような解法を使い場合はニューラルネットワークとは呼ばないのが普通です。
ニューラルネットワークという枠組みで考える場合は、学習方法として勾配効果法を使うのが通常です。よって誤差逆伝播法やオプティマイザなどといった概念が共通の概念として登場してきます。これらも詳しくはこちらで解説しています。
また、複数層からなるニューラルネットワークを多層パーセプトロン(Multi-layer Perceptron、MLP)と読んだりもします。
なお、ニューラルネットワークではネットワークの層をどのように構成するのかは自由になっています。よって、畳み込み層や再帰型のニューラルネットワークで使われるLSTMやトランスフォーマーのアテンション層などといった特殊な層を組み合わせても基本的な学習方法は同じになります。損失関数からの値を小さくするようにパラメータを調節していくだけです。
深層ニューラルネットワーク
最後に、ディープニューラルネットワーク(深層ニューラルネットワーク)とは何を意味するのかを解説します。
ディープニューラルネットワークは、多数の隠れ層を持つニューラルネットワークを指します。これらの多層構造により、複雑な非線形関係やパターンを学習できるため、画像認識や自然言語処理などの高度なタスクを実行できます。
では、どのくらい多くの層を持てばディープと呼ぶに相応しいのでしょうか。
実は、”ディープ”という言葉はマーケティングでよく使われた割にははっきりとした定義がありません。一応、隠れ層が2つ以上であれば、ディープニューラルネットワークと言えるということにはなっています。
しかし、今日では隠れ層が2つだけなんて話はほとんどありません。誤差逆伝播法などによってニューラルネットワークの学習がスムーズに行える以前には隠れ層が一つ増えただけで大ごとでしたが、今は何百層も持つモデルがたくさん存在します。
なのでディープニューラルネットワークを何か異次元のニューラルネットワークと考える必要はありません。現状、多くのニューラルネットワークモデルは”ディープ”です。よって、ニューラルネットワークもディープニューラルネットワークも同じような意味で使われることが多いです。また、学習の基本的な方法が異なるわけでもありません。
関連記事
この記事が気に入ったらチップで応援してみませんか?