
BigQueryを用いたDWH構築とLooker StudioによるBIダッシュボードのMVP作成

PIVOTでインターンとしてプロダクト開発に取り組んでいます、早稲田大学先進理工学研究科修士一年の鏑木惟蕗と申します。
2023年7・8月の二ヶ月間に渡って、PIVOTのプロダクト開発戦略の一プロジェクトとして、BigQueryを用いたデータウェアハウスの整備と、Looker Studioを用いたダッシュボード基盤の作成に取り組みました。
PIVOTが抱えるデータ分析の課題を共有しつつ、実際にこの期間開発したデータ基盤のプロトタイプについて備忘録として解説をします。
1. PIVOTが抱えるデータ分析の背景と課題
急速な事業成長に伴うデータの蓄積
PIVOTでは「コンテンツの力で、経済と人を動かす。」をVISIONに、学びある映像コンテンツを YouTube、Web アプリ、ネイティブアプリ(Android・iOS)の各種プラットフォームで配信しています。
2022年3月のサービスリリースから一年半にあたる2023年9月現在、総コンテンツ数は1000を超え、YouTubeの登録者数100万を達成、自社アプリケーションの総ユニークユーザー数は数十万を超えてきました。これらの数字からもスピード感を持ってサービス規模を拡大してきたと言えます。
サービス規模の拡大に伴って、コンテンツの非構造化データ、ユーザーの属性データ・閲覧情報、アプリケーション内でのユーザー行動データなど、さまざまなデータが蓄積されるようになります。
PIVOTのデータ分析における現在地
データが蓄積されれば、ダッシュボードを使ったデータ理解、詳細なデータ分析からユーザーインサイトの獲得、さらには機械学習を用いたより高度な応用へと繋げていくのが一般的です。
データ分析におけるフレームワークはさまざまなものが提唱されていますが、例えばCRISP-DM(Cross-Industory Standard Process for Data Mining)というフレームワークがあります。
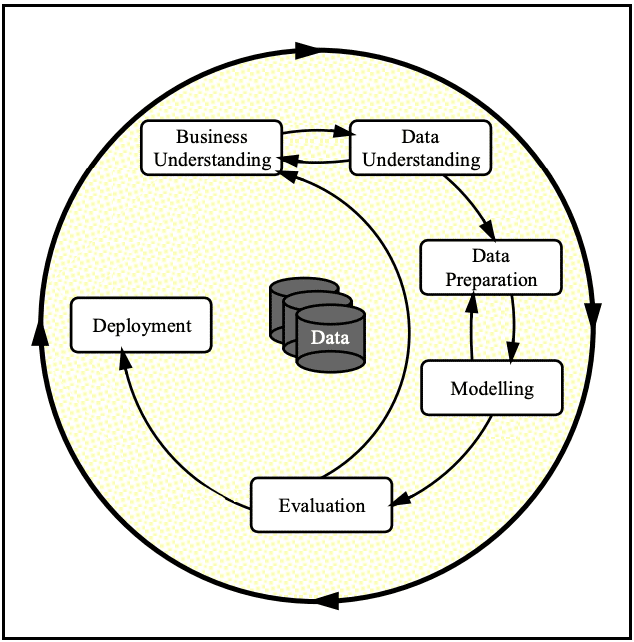
フレームワーク自体に本質的意義はないですが、ここで提唱されているワークフローには二つ重要なポイントがあると理解しています。
一つ目は、データ分析は「ビジネス理解」に基づいて設計・評価されるべきであるという点。二つ目は、ビジネス理解とデータ理解、データ準備とモデリングにあるように、一方通行で完了するフローではないということです。
プロジェクト当初、PIVOTには各種プラットフォームに分散したプロダクトのデータを統合的に管理するデータウェアハウスが存在しませんでした。そのため、まず「Data Understanding」「Data Preparation」を行う基盤がないということが目下最大の課題と設定できます。
2. PIVOTのプロダクト開発
サービスをGCPホスティングに移管したことがデータ集約を後押し
PIVOTでは、2023年4月から6月末までの三ヶ月間をかけて、オンプレミスサーバーに依存していた各種サービスをGCPに完全移行しました。
BigQueryとの連携がより低コストに行えるようになったことを契機に、今まで各種プラットフォームサーバーに点在していたサービスに関わるデータをBigQueryに集約させました。(Data Preparation)
実際には、各種サービスのAPIを活用し、データをBigQueryに流し込む処理をCloud Functionsでホスティングする。ということを愚直に繰り返す作業になります。
APIの仕様書と睨めっこしながら、ひたすらにデータ分析に必要な情報を定義しては実装しBigQueryに集める、という根気のいる作業でしたが、APIの仕様を把握することで、分析したい事象に対して取得されるデータが仮説通りであるということを確認するためには重要な作業です。(Data Understanding)
ここは社内のエンジニアと連携してスピード感を持って進めることができました。
3. PIVOTのデータ分析基盤
PIVOTでは下記のデータ基盤を構築・運用しています。
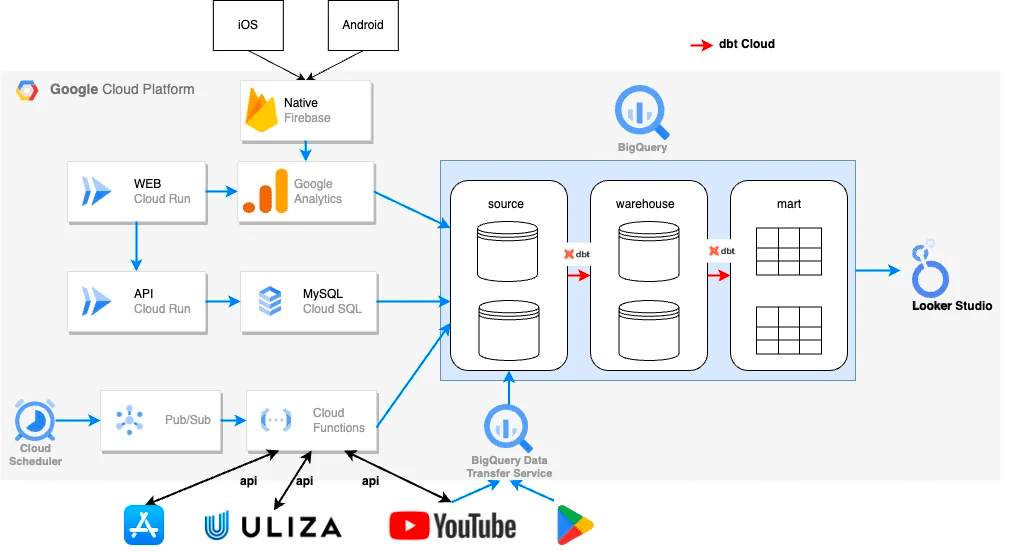
dbt Cloud を用いたData Transferパイプラインマネジメント
dbtとは Data Build Tool の略で、BigQuery(DWH)に集約されたデータの変換を担うツールです。オープンソースのCLIとして提供されるdbt CoreとWeb UI上で提供される dbt Cloudが存在しますが、より容易に運用できるdbt Cloudを採用しました。
dbt Cloudは痒いところに手が届くような機能がサポートされており、データ整形にかかる工数を大きく下げることができます。
実際に開発するにあたって、以下の点で利便性を感じました。
テーブル(ビュー)間の依存関係を解消したクエリ管理
macro とコンパイラを使ったコード可読性の向上
yamlファイルを使ったテキストレベルのモデル定義管理
dbt sqlファイルのドキュメント生成
Git リポジトリとの連携によるバージョン管理
dbt採用の利点は「データ分析の冪等性確保」と言えます。
可読性の高いSQLモデル記述のサポートや、細やかなクエリ設定をモデル定義に組み込めること、それらをGit上でバージョン管理できるため。分析を常に再現できるという強みがあります。
アナリストによって分析結果が異なったり、時間が経って集計ロジックが曖昧になってしまう、などのケースを避けられます。
DWHのモデル構造管理
分析におけるモデル管理についてはdbtから公式の指針が公開されていますが、PIVOTではこれをベースとしてさらに詳細化したモデル管理を採用しています。
source
外部からロードしてきたデータをそのまま保管(データレイク)
必要に応じて partition 分割することで、金銭的・処理時間の観点での分析コストを低減
(BigQuery:物理テーブル)
staging
warehouseを作成するための事前処理が必要な場合のみ作成する
(BigQuery:論理ビュー)
warehouse
分析readyな状態のテーブルを提供するインターフェイス
(BigQuery:論理ビュー)
secure
warehouseと同様の役割で個人情報をもつ
(BigQuery:論理ビュー)
mart
特定用途(ダッシュボード)に特化したデータを提供する Read-Only
(BigQuery:物理テーブル)
temporary
一時的な分析データ等を格納する 削除前提
(BigQuery:論理ビュー)
上記の分類に従った「モデル命名」と「テーブル定義」は、
分析におけるデータガバナンスの向上
クラウドコストの最適化
を図る目的があります。
モデルの運用指針について共通認識を定めておくことは極めて重要です。なぜならば、初期段階でデータガバナンスを無視すると、後々大きな技術的負債を抱えることになるからです。
現状の運用がベストかはわからないため、開発フェーズに合わせて運用ルールの継続的更新は必要でしょう。しかしながら、現状の運用においては各モデル(テーブル)のスコープを明確化することで第三者が見ても、テーブル設計の意図が理解できるようにしています。
また、分析用途に合わせてBigQuery側の物理テーブルと論理ビューを使い分けることで分析コストを下げることが期待されます。
BigQueryの運用コストは、基本的に「クエリの従量課金」と「ストレージ料金」に依存しています。物理テーブルを増やせばストレージ料金が余分にかかることになりますが、一方で論理ビューをいたずらに増やすと、参照ごとにクエリが実行され従量課金コストが嵩みます。
この辺りは、各社運用に合わせたベストプラクティスがありそうですが、PIVOTでは、現状バッチ処理でBigQueryのテーブル情報を同期していてクエリ回数が明確に固定されているため、基本的には論理ビューを採用し、BIダッシュボードから直接参照されるmartは物理テーブルを採用することでクエリコストを削減しています。
4. Looker Studioを用いたBIダッシュボード構築
PIVOTではBIダッシュボードのインフラとしてLooker Studioを採用しました。BigQueryとの連携が極めて容易であるため、MVPの作成において要件を満たしつつスピード感を持って開発する上で適していると判断しました。
今回の開発ではMVPとして、3つのダッシュボードを開発しました。
主要KPIのダッシュボード化
まずは全社として追いかけている主要KPIの数値を可能な限り全てダッシュボードに集約しました。
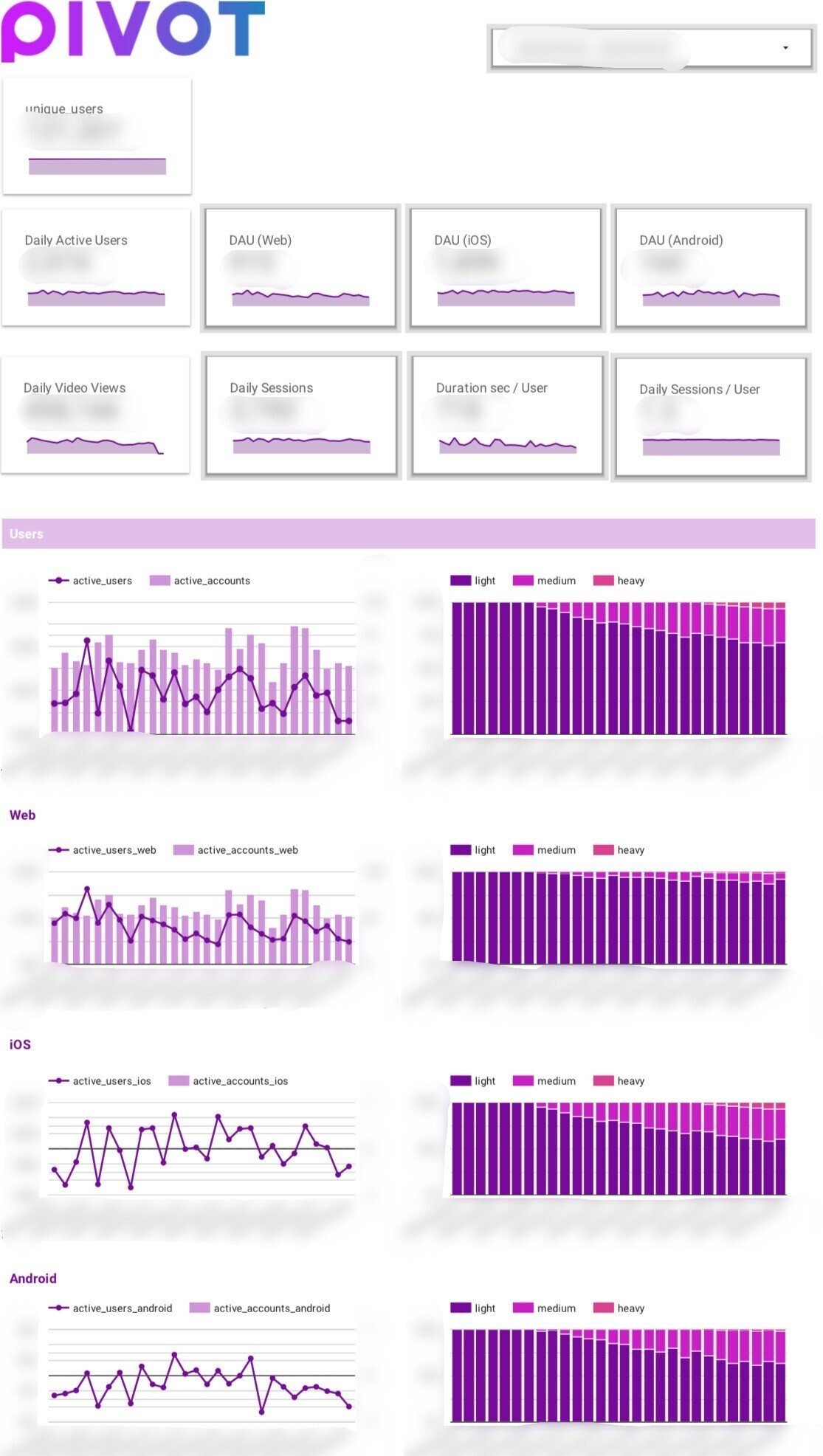
KPIの例をいくつか記載しておきます。
DAU WAU MAU
Web iOS Android 各種プラットフォームのアクティブユーザー数
日当たりの総セッション数
セッションあたりの滞在時間
動画コンテンツの総再生時間
などを追っています。
これらのデータはULIZAで提供されるAPIや、GAの自動収集イベントから取得をしています。標準のイベントパラメータに定義されていない行動に対しては、GTMを用いて新規にデータ取得を定義しています。
前述した通り、これらのデータはCloud Functionsを用いてBigQueryのsourceテーブルに集約された後、dbtでデータ整形をホスティングしてmartを作成します。martに整形されたデータをLooker Studioに接続し、可視化するパイプラインとなります。
コンテンツ軸でのデータ集約
二つ目のダッシュボードはコンテンツ軸でのデータ集約・可視化になります。
このダッシュボードの意義は「プラットフォーム横断的なコンテンツの分析」にあります。分析基盤構築以前は、コンテンツに対する情報が各種プラットフォームで提供されるサーバーに分散していました。
そのため、公開したコンテンツ再生状況は、YouTubeであれば YouTube Studio を参照し、Webアプリケーションでの再生状況はULIZAのダッシュボードを参照する、というような状態です。
各種サービスサーバーに散っていたデータをBigQueryに集約したことで、データのサイロ化問題を解消しました。
これにより、あるコンテンツに対して、YouTubeのユーザー層には刺さっているが、自社アプリケーションを利用するユーザーの閲覧状況はすぐれない、などのプラットフォーム毎の傾向に起因するインサイトを得やすくなりました。
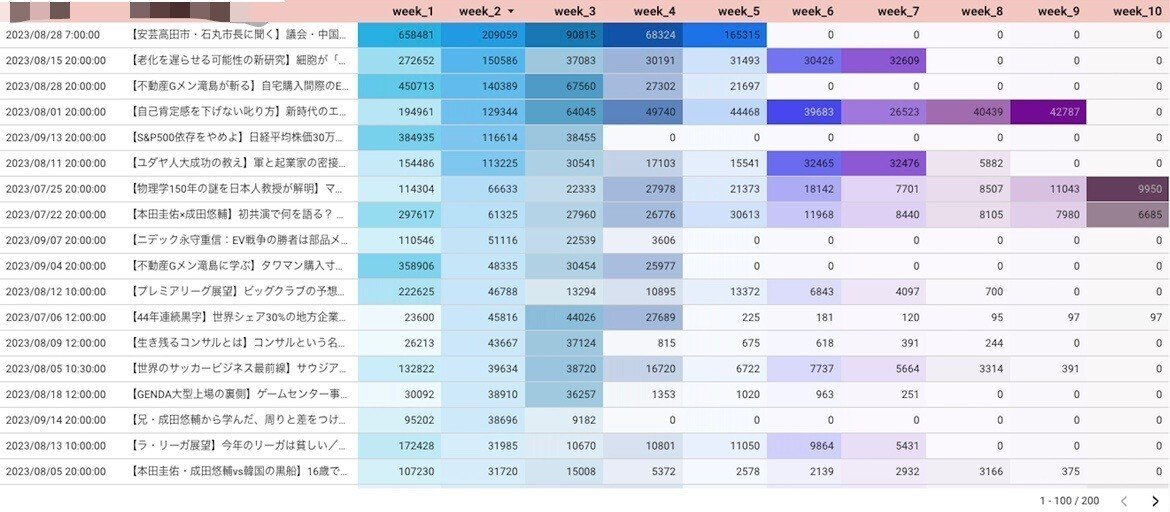
ユーザー軸でのデータ集約
三つ目のダッシュボードはユーザー1人単位での行動ログデータ解析・可視化になります。
このダッシュボードの意義は、ユーザーの「N=1を深掘り」することで質の高いユーザーの仮説を得ることにあります。
設計した指標は以下のようなものです。
最終ログイン日時/時刻
総視聴回数・視聴時間
直近一週間の視聴回数・視聴時間
視聴クライアントの割合
視聴しているコンテンツのカテゴリ割合
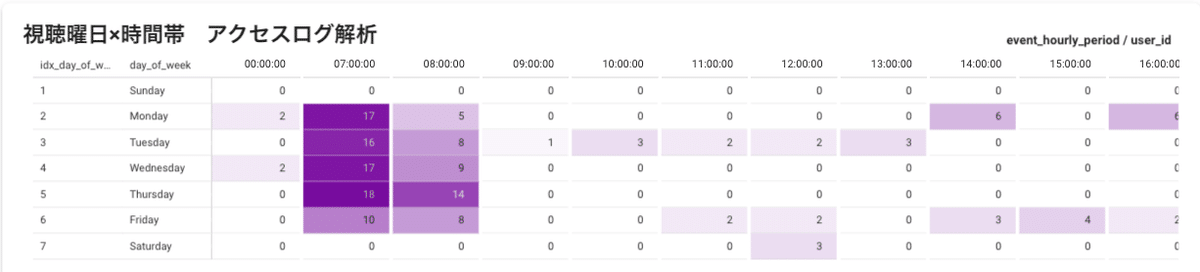
アプリケーションへのアクセス時間帯のヒートマップ
視聴時間帯のヒートマップ
アクセス時間帯のヒートマップなどを見ると、PIVOTのアプリケーションは平日朝と夜方にアクセスが多く、休日はアクセスが少ない傾向が見られます。PIVOTユーザーはビジネスマンが多く出勤時と帰宅後睡眠前に見ている人が多いのだろうか、という仮説が立てられます。さらに、朝方にはどんなカテゴリのコンテンツが再生されやすいか、休日に再生されやすいコンテンツの傾向は何か、などもダッシュボードから閲覧ができます。
このような情報から仮説を得て、コンテンツの公開時間帯や曜日毎の編成などを最適化する運用がなされています。
5. プロジェクトの振り返り
感想
今回は、PIVOTの統合的データ分析基盤の構築とダッシュボードの設計・実装を二ヶ月間で行いました。プロジェクト開始時点では空っぽだったBigQueryワークスペースに、現在では100近いテーブルが作成され、さまざまなデータが集約されました。内、Looker Studioで参照しているmartテーブルは40近く存在します。まさしく0→1のフェーズを体感できたという点で面白い経験ではありました。
データ可視化は本質的には価値と言えるのか?
僕自身常々「プロダクト開発におけるデータ分析の本質的意義は何か?」ということを考えています。
基本的に、プロダクト開発においてはデータ分析はそれ単体では意味を成さないと考えています。分析そのものがユーザー体験が向上したり直接的に企業成長や損益に寄与することはないからです。(ただしメディアという性質上、どのコンテンツが、いつ・どの媒体で・誰に・どれだけ見られたか、を詳細に定量化することはそれ自体重要性が高いということは大いに理解しています)
だからこそ、CRISP-DMにあるように、分析の起点はビジネス理解であり、その効果もビジネスの観点において評価されなければいけないのです。
この点はエンジニアサイド、ビジネスサイド関わらず、相互にリテラシーを高めていかないといけません。
PIVOTの更なる事業成長のために
客観的に見て、PIVOTはこの一年急速に成長していることは間違いないです。インターンとして関わるようになって半年ほど経ちますが、この成長は、PIVOTのビジネス的な成長戦略とそこに合わせた各社員のコミットメントによるものだと感じます。
これから先さらに加速度的に成長していくためには、プロダクトの成長、ひいてはデータの活用が非常に重要であると感じています。
今回のプロジェクトは、基盤設計・可視化までしか行えていませんが、今後はユーザー体験を高めるようなデータの利活用にもスコープを広げていきます。
今後の展望
さて、データの利活用の一環として現在レコメンド機能の検証・開発に取り組んでいます。YouTubeやNetflixなど現在の映像配信プラットフォームには必要不可欠な一機能、特にNetflixの再生は8割がレコメンドに起因するものであるという報告もあることからユーザー体験に直結する機能の一つです。
今後実装予定になるので、PIVOTユーザーの方はお楽しみにお待ちください、、、
終わりに、、
本プロジェクトを進めるにあたってプロジェクトマネジメント・ビジネスインサイトに基づいた指標設計の部分でPMの蜂須賀さん、データ基盤構築においてはエンジニアの黒澤さんには設計から実装まで一緒に仕事を進めさせていただきました。
また、データ分析設計と実装においては外部顧問であるコンサルティングチームapnea代表である田島将太さんに大変お世話になりました。特にWeb上の行動分析において、技術的側面から分析設計まで質の高いサポートをいただき大変勉強になりました。
筆末で恐縮ですが、田島さんが書かれたこちらの記事も、KPIに対する向き合い方に深い洞察を与えていて勉強になります。
皆様にこの場をお借りして感謝申し上げます。
PIVOTでは、Mobile Engineerの方を募集しています。
YouTubeチャンネルはこちら
Web版はこちら
iOS アプリはこちら
Android アプリはこちら
[1] https://www.cs.unibo.it/~danilo.montesi/CBD/Beatriz/10.1.1.198.5133.pdf