
正規表現・ワイルドカードを使って的確な検索語句をヒットさせよう

Pythonに限らず、正規表現はいろいろなUNIXコマンド・ExcelやNotionなどの関数・プログラミング言語にも応用が効きます。特にiPhoneやiPadのショートカットアプリの
文字の抽出
にものすごく役立つので、覚えておいて損はないでしょう。正規表現を覚えれば、ファイルを適切に抽出だけでなく、
特定のルールにおける入力チェック、部分抽出…
などを行うことができます。
⚠注意
正規表現のほかにワイルドカードの書き方も存在します。ここでは、正規表現編とワイルドカード編と分けて解説して行きたいと思います!!
ワイルドカードと正規表現は違う。
そもそも、ワイルドカードと正規表現の書き方は似ています🤔
なので、Googleで検索すると、UNIXのワイルドカードのことを正規表現と書いたりするので、混同しがちだったのを今も覚えています。ですが、混乱してしまうと、たとえば、Pythonでいうと、globモジュールのglob関数を使ったときに正規表現を入れてしまうと、エラーを起こしてしまいます💦
import os,glob
desktop_path=os.path.expanduser('~/Desktop')
files=glob.glob(rf'{desktop_path}/[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]*')#このやり方でもYYYYMMDDで絞れる。
print(files)たとえば、上のコードを見てみると、行頭が数字で始まるファイル・フォルダを抜き出したい場合は、上のようにワイルドカードに基づいた書き方にしなければいけません。
実行結果を見てみると、
![glob関数にワイルドカードのルールに沿ってしたがって検索。 [0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]* は最初が8ケタの数字から始まるファイル・ディレクトリ名を検索した。実行結果は、ちゃんと、ファイル名が表示されました。](https://assets.st-note.com/img/1665896469207-tJ9jRYCVpP.jpg?width=1200)
ちゃんと検索されてファイルのパスをちゃんとリストアップしてくれました☺️
ですがたとえば、正規表現の書き方で
files=glob.glob(rf'{desktop_path}/^\d{0,8}.*')上のように書いてしまうと、glob関数側では認識できず、下の画面のように
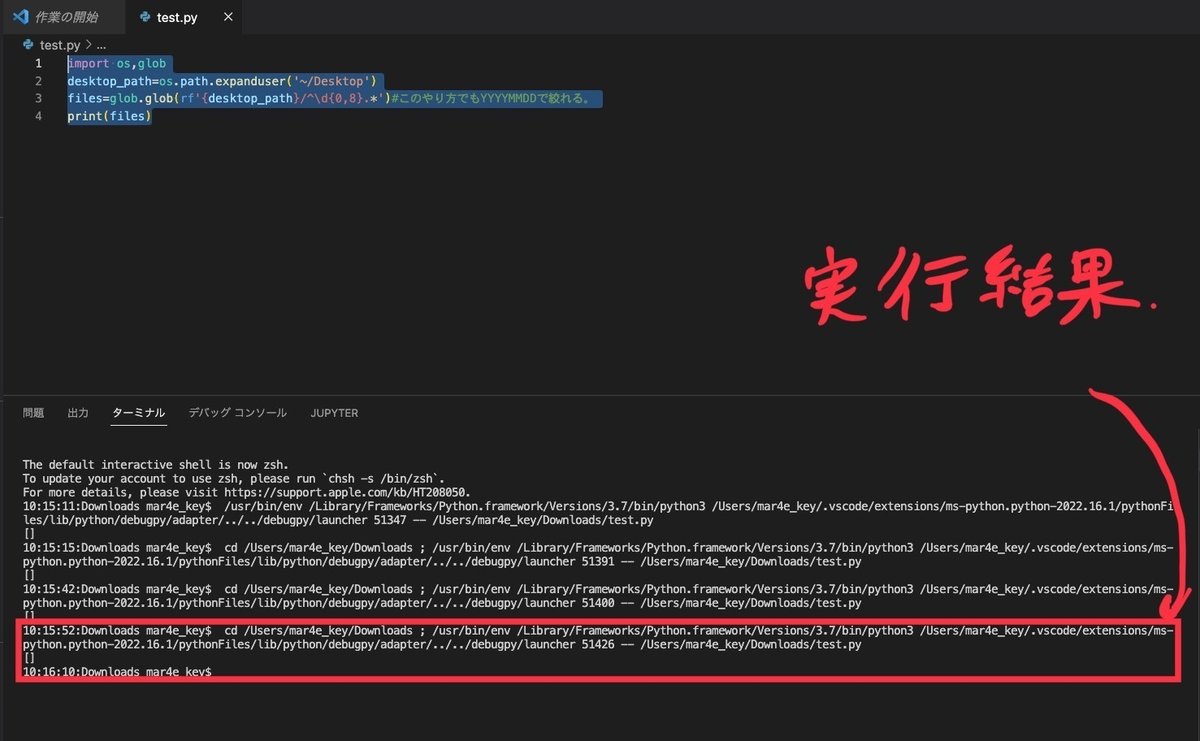
実行結果が、
[]
と何もファイルやディレクトリが検索されずに終わっていることがわかります。
したがって、Pythonのようなプログラミング言語やUNIXのターミナルなどに関わらず、
UNIXのワイルドカードか正規表現が使えるかどうか
を事前に調べる必要があり、しっかりと区別して書かなくてはいけません🤔
さきほど、ワイルドカードや正規表現をいきなり出してしまい、
「??」
となってしまったのかもですが、最後まで読み進めていくと、正規表現とワイルドカードへの理解が深まるように作りましたので、ぜひ、最後まで読みすすめていってくださいね☺️
正規表現編
基本的な書き方
正規表現は、文字列のパターンを表現するための強力なツールです!!まずは、下の表をご覧ください。

これらの基本的なパターンを理解することで、より複雑な正規表現を作成することができます!!正規表現により、
テキストの検索、置換、抽出
に役立ちます。それでは、正規表現の基本的な書き方について解説していきたいと思います。

上の図のように
対象となる文字を前に持って行き、何文字分必要なのか
を記入していきます。また、何文字分必要かというのは繰り返しとよく表されることが多いです☺️もちろん、1つだけの場合は後ろの部分は省略しても構いません。
正規表現はPythonなどのプログラミング言語だけにしか使えないと思われがちですが、意外とNotionの関数(例えば、test関数。)で使えたりもしますので、無駄にはならないことを保証します!!
Pythonで正規表現を使うには?
お急ぎの方はこちらの動画をご覧ください↓
そもそもPythonで正規表現を使うにはどうすればよいのでしょうか?正規表現を使うには
reモジュール
を用います。それではコーディングをしていきましょう。たとえば、YYYY年MM月DD日で書かれたファイルの頭の8ケタの数字で入力されているのかをチェックするにはどうすればよいのでしょうか?
答えは下のコードで、
import re
re.compile(r'\d{8}')`と書きます。\dは数字という意味で、{8}は直前の文字を8回繰り返すという意味です。なので、
「8文字の数字はあるのか」
という意味になります。
なお、Pythonで正規表現を用いる場合、クォーテーション(')で囲んだあとに
rを頭文字に添える必要
があります。なぜなら、
\n(改行)と認識
されますし、
\dはdのエスケープ文字
と誤認識してしまうためです。
クォーテーション('')にrを添えた文字列のことを
raw(ロー)文字列
といいます。raw文字列と他の文字列の違いはそのままで出力されるところが違います。
print(r'これは\n電気です。')#正規表現を扱うにはraw文字列を使いましょう!!
print('これは\nインクです。')実行結果↓
これは\n電気です。
これは
インクです。このため、正規表現では、raw文字列(r'[文字]')を使わなくてはならないのです!!
※最近のPythonではf文字列(ストリング)が用いられることがありますが、f文字列とr文字列は組み合わせることも可能です!!
それでは実際にコーディングをしていきましょう!!
import re
filestr='20221231名前'
myregex=re.compile(r'\d{8}')#正規表現を使い回すにはreモジュールのcompileメソッドを使う!!
if myregex.match(filestr):#文頭を基準にマッチするかどうかを判定する関数です!!
print(filestr)20221231名前たったこれだけで入力チェックみたいなことができてしまうんです!!
正規表現は一度覚えてしまうと、コーディングの負荷を極力減らすことができます!!これで
「文頭の8ケタの数字のチェック」
ができたので、次は、正規表現で文字の抽出をしていきましょう。抽出するにはfindall関数を用います。正規表現でも抽出ができるとなると、正規表現って便利ですよね!!
では8ケタの数字をfindall関数で抜き出してみましょう。
findall関数では
「部分的に文字を検索」
しますので、文頭を指定したい場合は、
「^」
の文字を用います。なので、文頭から8ケタの数字の抽出したいので、
^\d{8}
とします。それでは、実際にコーディングしていきましょう!!
今回の目的は、8ケタの数字(日付)と名前で名付けられたフォルダの名前を
8ケタの数字
名前
に分割することを目指していきます。
import re
filestr='20221231名前'
myregex=re.compile(r'^\d{8}')#文頭から8ケタの数字を抽出するという意味。
calNum=myregex.findall(filestr)#findallは正規表現で指定した文字列たちを返します。
print(calNum)#実行結果は配列になっています。
['20221231']上のように8ケタの数字が見事に抽出されました。
では、9文字目から抽出したい場合はどうすればよいのでしょうか?そのヒントは目次で見せたショートカットの画像にそのヒントが隠されています!!それでは
重要なところをトリミング
しましょう。

(?<=^{文頭から検索しない文字数})検索したい正規表現
で、○文字目から文字を抽出することができます。たとえば、9文字目から抽出したいときは、検索対象にしない文字数のところを8に置き換え、検索したい正規表現のところに
「.*」
と置き換えればOKです。「.(ドット)」の意味は
「空白」や「空白」以外の文字を抽出する
という意味です。次に*(アスタリスク)は
無限大(∞)の繰り返し
を意味するので、
9文字目からすべてを抽出する
という意味になります。
import re
filestr='20221231名前'
myregex=re.compile(r'^\d{8}')#文頭から8ケタの数字を抽出するという意味。
calNum=myregex.findall(filestr)#findallは正規表現で指定した文字列たちを返します。
print(calNum)#実行結果は配列になっています。
['20221231']import re
filestr='20221231名前'
myregex=re.compile(r'(?<=.{8}).*')#文頭から9文字目を抽出するという意味。{}内の数字は、
calTitle=myregex.findall(filestr)#findallは正規表現で指定した文字列たち(文字列の配列)を返します。この関数の場合、空白の文字列も抜き出すこともあります。
calTitle=list(filter(lambda title: title!='',calTitle))#空白がいらないときはfilter関数を使って前処理をすると良いでしょう。
print(calTitle)#実行結果は配列で返しています。
['名前']これで数字の8ケタとタイトルとの文字に分割ができましたね!!
ちなみに、match関数との違いですが、
match関数は文頭からの文字列の検索の判定するのに対し、findall関数は文頭関係なく、文字列すべてを検索の対象にし、マッチする文字列を返します。
日付の抽出をすべく、年と月と日をそれぞれ分けて正規表現を使って抽出してみましょう。
え!?Pythonでは文字列では文字を配列の要素で抜き出せるんだけど!?
Pythonでは文字列を文字で抽出することは可能ですが、今回の記事のテーマは、正規表現なので、○文字目から抽出できるってことをお伝えしました!!
ではまとめてコードを書いてみます。目的は数字と文字列を分けることでしたね!!
import re
filestr='20221231名前'
calNum_reg,Title_reg=[re.compile(r'\d{8}'),re.compile(r'(?<=.{8}).*')]#Pythonでも一つの配列を複数の変数に入れることができます。
#文頭から9文字目を抽出するという意味。{}内の数字は、
calNum=calNum_reg.findall(filestr)
calTitle=Title_reg.findall(filestr)#findallは正規表現で指定した文字列たちを返します。この関数の場合、空白の文字列も抜き出すこともあります。
calTitle=list(filter(lambda title: title != '',calTitle))#空白がいらないときはfilter関数を使って前処理をすると良いでしょう。
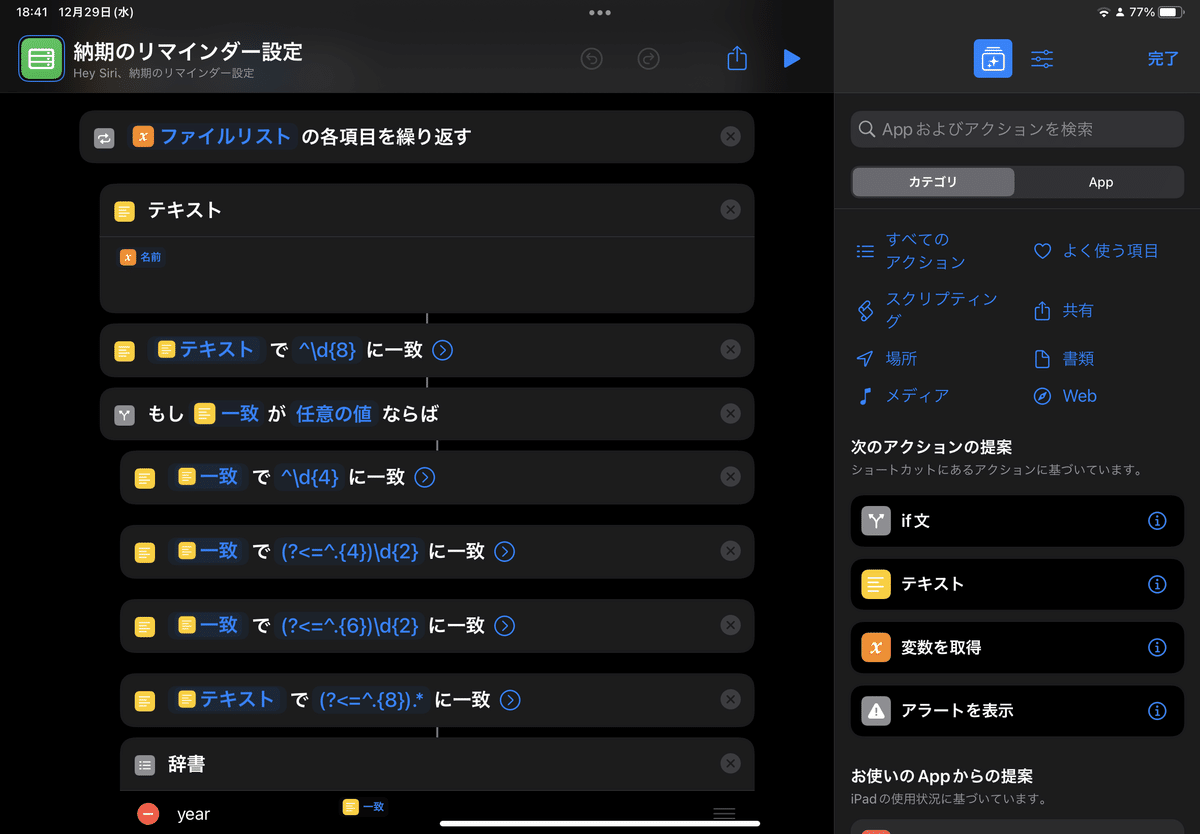
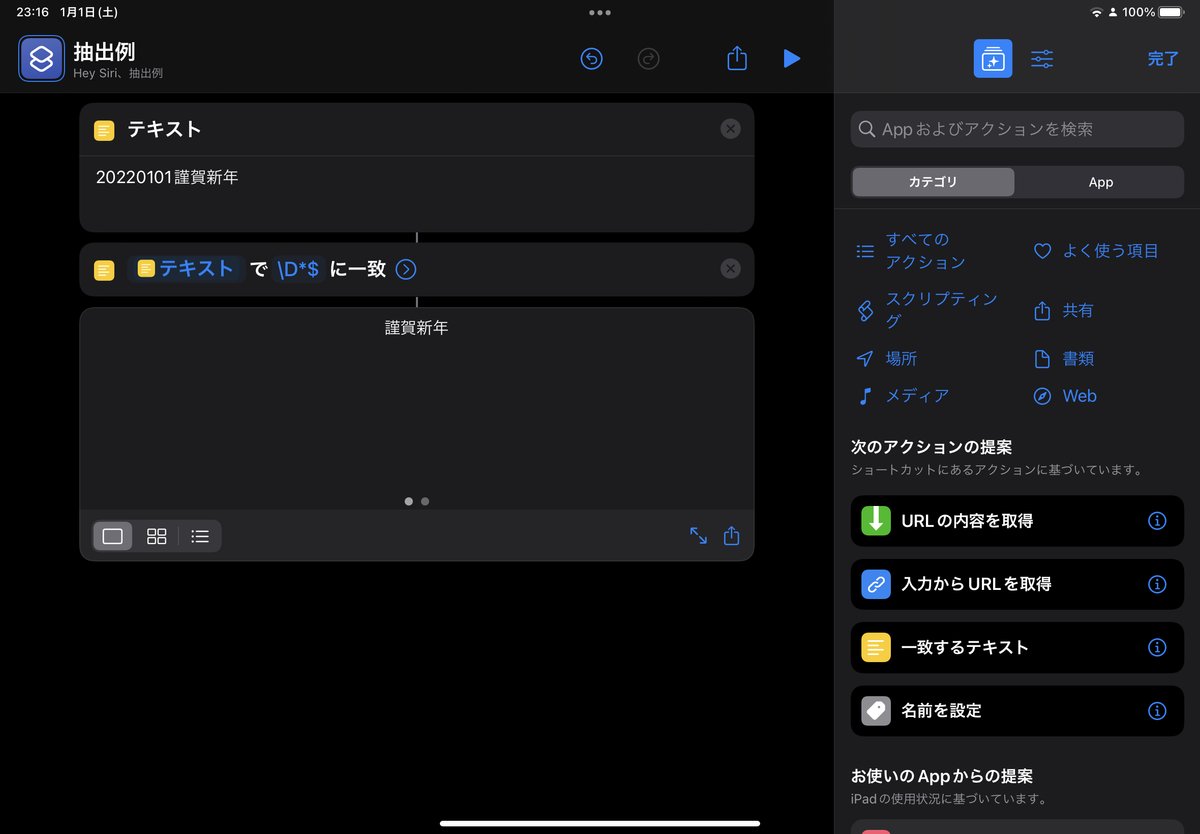
print(calNum,calTitle)#実行結果は配列で返しています。['20221231'] ['名前']応用編①:ショートカットアプリでも正規表現を使ってみよう。
正規表現もショートカットアプリでも応用することができます。
「一致するテキスト」
で正規表現を適用することが可能です。(Pythonのfindall関数に近いが、空白はかえさない。)まず、抜き出したいテキストを用意して、テキストの一致にて正規表現をもとに、結果を抽出したショートカットの一例です。
また正規表現はUNIXコマンドであるsedコマンドやgrepコマンドでも使うことができます。
sedコマンドは置き換え
grepコマンドは行の抽出
するのに便利なコマンドですが、正規表現をわかっていないと、
使いづらいコマンド
となります。でも、正規表現さえ覚えていれば、grepコマンドやsedコマンドなどで
「文字列の操作」
を自在に行うことが可能です。
なので、シェルスクリプトでも応用が可能というわけです。
※なお、シェルスクリプトもできると、AppleScriptでの文字列の操作も容易にできたりするので覚えておいてソンはないです!!
!echo "20221231名前" | grep -o '^\d\{8\}'
!echo "20221231名前" | grep -o '\D*$'
#ターミナルで入力するときは、「!」を抜いて入力してください。
#{}をターミナルで入力する場合は{}それぞれの頭に\(エスケープ文字)を添えないと、正しく動作しません。20221231
名前grepコマンドで文字列を抽出したい場合は-oオプションを忘れずに入れないと、
「文字の抽出」
をしてくれないので、注意しましょう。
\D(数字以外のもの)
\$(末尾から)
︙
ん?ちょっと見慣れない正規表現があったなと思いませんでしたか?
\Dは数字以外の記号を指したいときに使います。
\$は文字列の末尾を指します。\$は
「単独だけでは」
ダメで
何かの文字列と組み合わせて使うことが多い
です。
コマンドのオプションの引数で、正規表現を入力する場合、
{}(中カッコ)
で囲む場合は
エスケープ文字(\(Windowsでは¥(半角))を両端に添えなければいけない
と頭に入れておけば、ターミナルのコマンドでも応用が可能です。
応用編②: Notionのtest関数で、ルール通り、きちんと時刻が書かれているかどうか判定する
まずは下の動画をご覧ください↓
正規表現の応用例として、Notionのデータベースでちゃんと時刻が形式通りに入力ができているかチェックする正規表現を入力してみましょう。用途は時間帯設定で使うものとします。
正規表現を入力する前に正規表現で特定の文字列を判定する関数を覚えましょう。それがtest関数です。test関数の書き方は
test([対象となる文字列・プロパティ],[判定の基準となる正規表現])
と書きます。指定された正規表現にマッチすると、「True(真)」、マッチしないと、「False(偽)」と返します。まずはデータベースを新たに作り、
開始時間→テキスト
終了時間→テキスト
判定→関数
のプロパティを作ります。
では、作ったところで下の例を参考にし、きちんと時間が入力されているか判定する関数を入力してみましょう。
let(時間の形式パターン,"([0-1]\d|2[0-3]):[0-5]\d",if(and(test(prop("終了時間"),時間の形式パターン),test(prop("開始時間"),時間の形式パターン)),"OK","NG"))すると、下のデータベースのように判定の部分がきちんと時間が入力されていれば「OK」、入力されていなければ、「NG」と表示されます。

まず、let関数を用いることによって繰り返し入力を避けることによって関数に対し、見やすい工夫を施しました。またand関数を用いて、開始時間と終了時間、いずれかに入力ミスがあると、NG(False「偽」)を出すようになっています。たとえば、タスクシュートのようなセクション時間帯のような時間帯を指定する際に役に立ちます。では次に本題、先ほど用いた正規表現の意味について解説したいと思います。
ちなみにlet関数、if関数詳しく知りたい方は、1文字以下のnoteで説明しています☺️↓

まず、時:分の時の部分から説明して行きます。(セミコロン「 : 」は正規表現ではないので説明は省かさせていただきます。)
結論から言うと、「時」のルールは00~23となっています。まず、赤字の()カッコのグループに着目してみてください。中カッコ「 () 」はグループとしてみなすと言うことを先ほどの正規表現の表で説明しました。次に
[0-1]\d
に着目してみますと
1文字目は[0-1]なので、0~1かの数字
2文字目は\dは数字
を表す正規表現となります。また、
2[0-3]
は
1文字目は2なので、2の数字
2文字目は[0-3]は0~3の数字
と言う意味になります。で1文字目と2文字目を挟んで「 | 」があります。「また(OR)」と言う意味でしたね☺️
[0-1]\d|2[0-3]
で
00~19または20~23
すなわち
「0~23」
を意味することになります。「分」の場合も同じ考え方で、
[0-5]\d
ですから、
1文字目は[0-5]なので、0~5の数字
2文字目は\dなので、数字
なので、
00~59
と言う意味になります。こうして時:分で入力しているかをtest関数を使ってチェック・判定することができるのです☺️
ワイルドカード編
基本的な書き方
まず、代表的なワイルドカードについて以下の4種類があります。
[!0-9] :0~9以外の数字
[0-9] :0~9である数字
? :対象となる1文字。
* :0文字以上
正規表現と違うのは「?」と「*」だけ文字と繰り返しがセットになっているという点です。あと、[!0-9]は正規表現だと[^0-9]となりますので、くれぐれも混同しないように気をつけてください。
また、ワイルドカードを正規表現と書かれて説明するところもありますが、ワイルドカードと正規表現は区別して覚えましょう。
「正規表現とワイルドカードの表記方法の違い」
さえおさえていれば混同せずにワイルドカードと正規表現を区別して書くことができるようになります。ではまず、ワイルドカードの具体的な使い方をWordと Excelを使って実際に一緒に勉強して行きましょう。
またこのNoteでは、Pythonのglob関数でワイルドカードにおけるファイルの検索の仕方についても解説していますので、ぜひこの機会に覚えていってください。
Wordでもワイルドカードは検索できる。
では、ワイルドカードの使い方に慣れるべく、Wordの検索画面で実際に使ってみましょう。
ワイルドカードの検索方法はiPad版ではできませんので、ここはPC、Mac版のオフィスを開いてください。

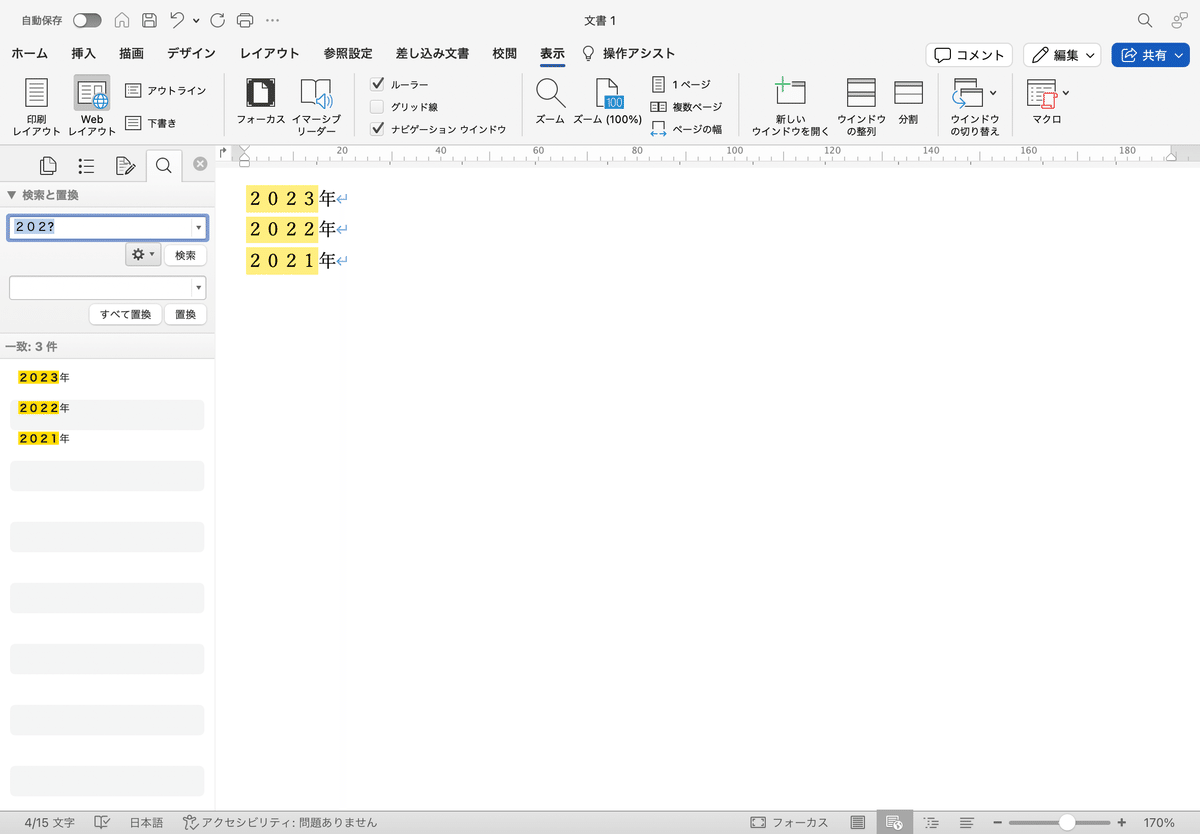
①まず、⌘F(Windows版では、Ctrl+F)でWordのサイドバーを使って検索画面を開きましょう。(※1)そして、虫眼鏡の部分をクリックし、検索結果をサイドバーに表示するをクリックします。(※2)
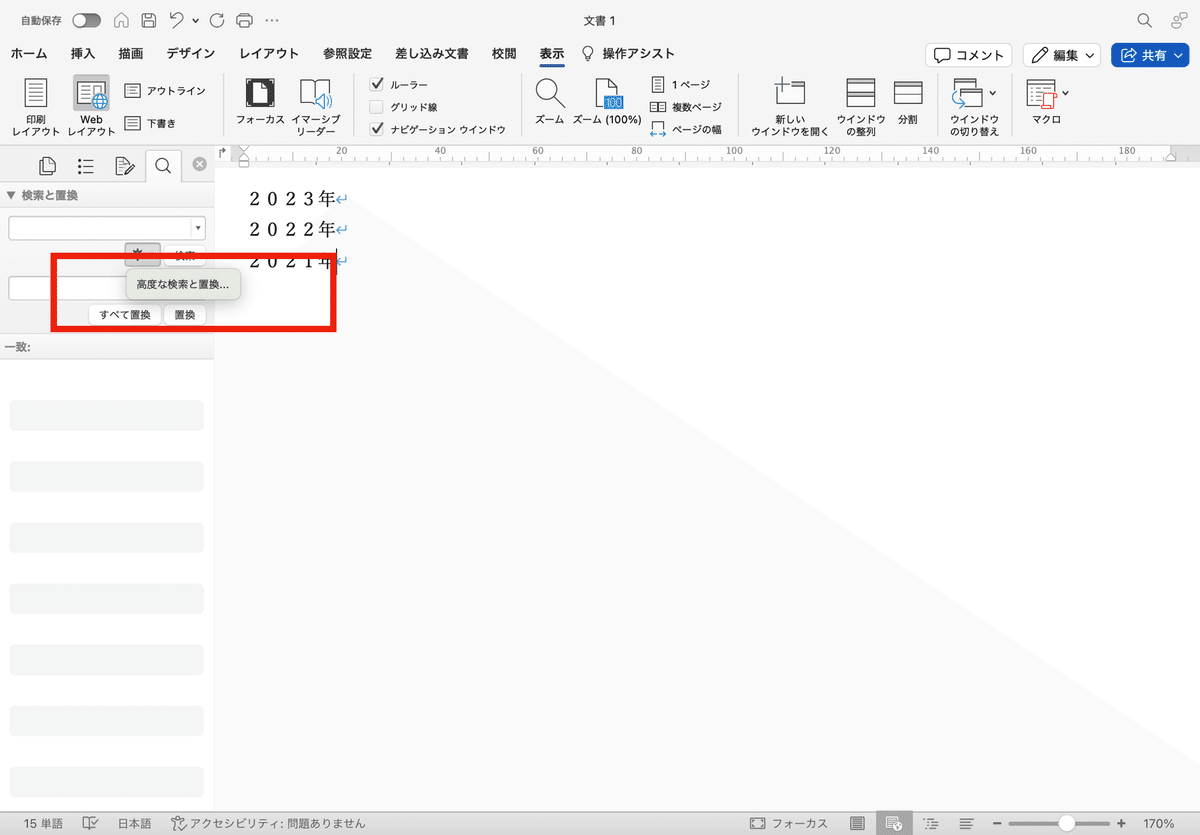
②そして、検索と置換のサイドバーを開き、歯車(⚙)のマークをクリックし、「高度な検索と置換」をクリックしてください。

③検索と置き換えの画面で、「ワイルドカードを使用する」のところにチェックを入れます。
以上のところを踏まえて、実際に202◯の部分だけを検索候補に残したいものとします。実際に、
202?
と入力します。「202?」の「?」は202以降の1文字ということをさきほど説明しました。よって、2023、2022、2021と選択されていることがわかります。このように、ワイルドカードは覚えておくだけで
狙ったところを検索する
のに使えます。みなさんもぜひWordを使う機会があったら、試してみてくださいね!!
glob関数でワイルドカードを使って検索する。
Excelでワイルドカードの検索になれたところで、Pythonのglob関数を使い、ワイルドカードを使ってファイルの検索をしていきましょう。はじめは正直に言って、glob関数でも正規表現はいけると思っていたときがありました。ですが、
「ワイルドカード」
の書き方でないと、ちゃんとファイルを探してくれません🥺はじめに書いたワイルドカードの意味も合わせて解説していきたいと思います。では、まずはコードを見てみましょう。
import os,glob
desktop_path=os.path.expanduser('~/Desktop')
files=glob.glob(rf'{desktop_path}/[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]*')#①このやり方でもYYYYMMDDで絞れる。
print(files)まず、
[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]*
の意味をみていきましょう。
[0-9]
の意味は正規表現の [] と同じ意味で、
「1から9までの数字」
を捜せということを意味しています☺️
また、
「*」
の意味ですが、正規表現では、
「*」は単に何回も繰り返す
のに対して、ワイルドカードの意味では、
「*」
だけで、
あらゆる文字列を探せ
という意味になります。ですので、
[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]*
の意味は、
8ケタの数字から始まるあらゆるファイルとフォルダを列挙せよ
という意味になります。
これをglob関数などで実行することによって、
['/Users/mar4e_key/Desktop/20221012買い出し.pdf',...]というふうにファイル・フォルダを探すことができるというわけです。
ターミナルのfindコマンドでもワイルドカード検索できます!!
ターミナルのfindコマンドでも
ワイルドカードでファイルの検索
が可能になります!!さきほどのglob関数のやり方でワイルドカードを使ってファイル検索していきましょう!!ワイルドカードの理解をさらに深めるため、今度は違ったワイルドカードを使って検索していきましょう!!
今度は[] の否定の意味である。
[0-9]
の反対の意味から発想を膨らませていって、
[!0-9][!0-9][!0-9][!0-9][!0-9][!0-9][!0-9]*
を使ってみましょう。ちなみに[]に
「!」
をつけることで、
[]以外の文字を検索する
という意味になります。つまり
[!0-9][!0-9][!0-9][!0-9][!0-9][!0-9][!0-9]*
は
「文頭が半角数字の8ケタから始まらない文字列を探せ!!」
という意味なります!!それでは、実際にやってみましょう!!ターミナルに実際に
find . -name [!0-9][!0-9][!0-9][!0-9][!0-9][!0-9][!0-9][!0-9]\*と入力してみましょう!!正規表現の [] とは書き方が異なりますので、
えっ!?なんでアスタリスクの前に
\(バックスラッシュ)
をつけるの?思ったかもしれません🤔なぜ、ターミナルのコマンドを使うときは、アスタリスクの前に
\(バックスラッシュ)
をつけなくてはいけないのかというと、
実際に
\(バックスラッシュ)
の入力をしてみたところ、以下のエラーが出ました。
![find . -name [!0-9][!0-9][!0-9][!0-9][!0-9][!0-9][!0-9]* ▶ find: [何かのファイル名]: unknown primary or operator](https://assets.st-note.com/img/1666181100746-4owhNF5a63.png?width=1200)
では、あらためて、*(アスタリスク)の前に、
\(バックスラッシュ)
をつけて、再度実行してみましょう!!
下の画像の通り、無事に検索されました!!
![Desktopフォルダにて、find . -name [!0-9] [!0-9] [!0-9] [!0-9] [!0-9] [!0-9] [!0-9] [!0-9]\* 8桁の数字から始まらない名前を順次、ファイルを列挙してくれている🤔](https://assets.st-note.com/img/1666098456880-NPzontOqjg.png?width=1200)
すると、
8ケタの数字から始まるファイル以外
が抜き出されました!!成功です!!よしっ💪
ワイルドカードはおおまかにしかパターン文字列を指定することができない。
ワイルドカードの使用の場合、
「正規表現」
と同じように細かく指定できない点に注意が必要です。またワイルドカードは正規表現と全く同じ表現もあれば、違う表現もあるので、注意が必要です🤔
下の記事は、ワイルドカードと正規表現を実際に応用してる例を解説していますので、よろしければ、ご覧ください↓
まとめ
いかがでしたでしょうか?ワイルドカードや正規表現はちょっとクセがありますが、使い方さえ覚えれば、
痒いところに手が届く検索結果の提供や、ファイル名の抽出&入力チェッカーにもなってくれる
ので、検索するのが楽しくなっているように感じました。みなさんもワイルドカードと正規表現の知識がこのNoteを通じて学びそして活用してくれれば、これほどうれしいことはありません!!
それではここまで読んでくれてありがとうございました〜!!