
【Python】SeleniumとBeautifulsoupを理解して使いこなそう

BeautifulSoupとSeleniumってどっちもスクレイピングできるよね?
と思われている方も多いのではないでしょうか?確かに
抜き出す部分は確かにそう言えると思います。言いすぎかもですが、Seleniumがあれば
「一発でスクレイピング」
がこなせてしまいます。ですが単に
情報の抽出に絞られるのであれば、あらかじめHTMLを読み込む必要がありますが、BeautifulSoupの選択肢も出てきます。また、ページの種類によっては、Requestsモジュールがいけることもあります。図で表すと
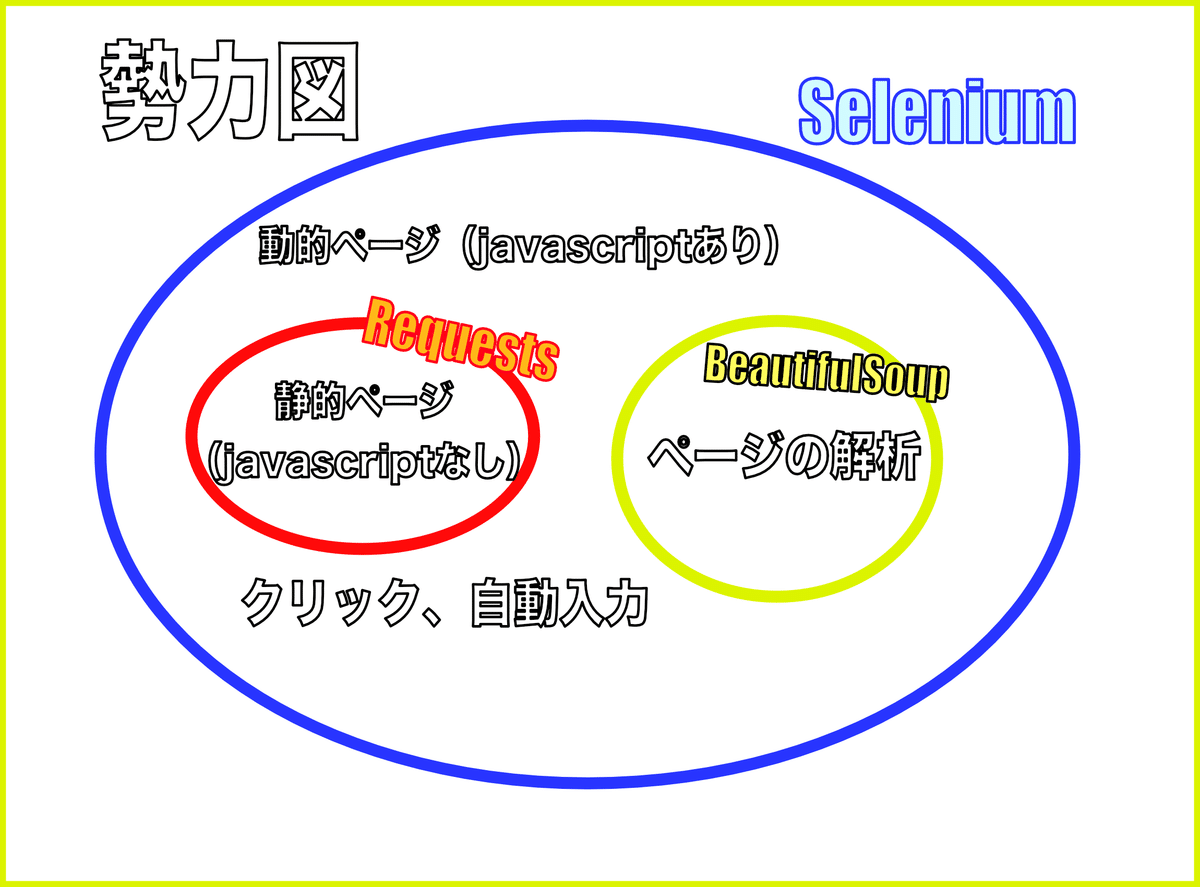
となります。このように、
Selenium
BeautifulSoup
Requests
それぞれ特徴があり、組み合わせて使うことで、よりよいプログラミングができることに気がつきましたので、みなさんにシェアしていきたいと思います!!
⚠注意 こちらの記事はPythonのプログラミングの文法をわかっている方向けに書いています。この記事は、スクレイピングにおいて、Selenium・Requests・BeautifulSoupを使い分け方やそれぞれのモジュールの特性を理解することによって、使いこなせるようになることを目的としています。
そもそもSelenium・Requests・BeautifulSoupの違いってどんな違いがあるの!?
まずは、動画を見て、Selenium、Requests、BeautifulSoupの使い分けに関して学びましょう↓
では、もう一度さきほどの図をもう少し詳しく見てみましょう。
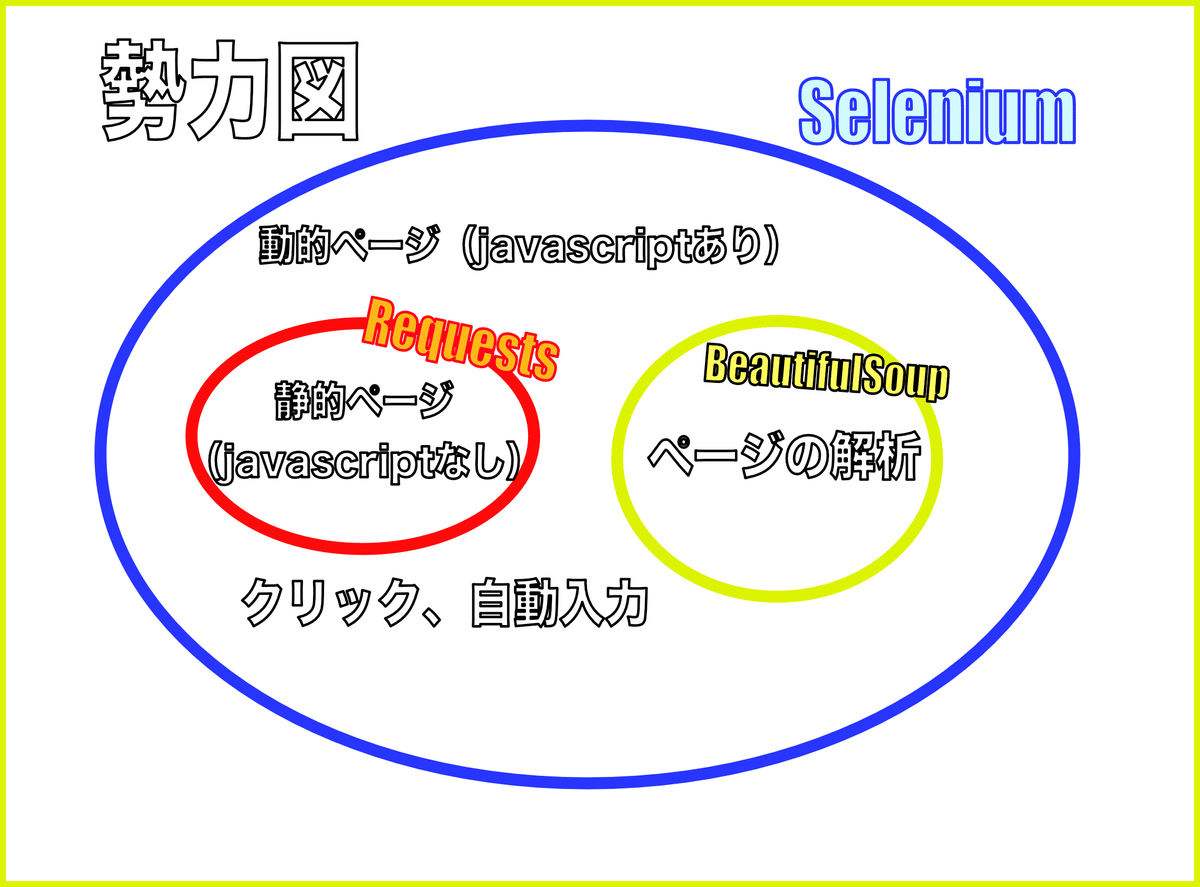
Seleniumはスクレイピングにおいては、
「なんでもこなせちゃうよ君」
で
ページの種類関係なくダウンロードできる。
情報の抽出
クリック操作
キーボード入力操作
などスクレイピング機能に関しては申し分ない機能を搭載しています。
一方、Requests単体では
「ダウンロード」
に特化しており、抽出においてはあまりコントロールが効かないライブラリとなっています。 一方、BeautifulSoupは
「情報の抽出」
が得意なモジュールとなっています。ですので、BeautifulSoup単体では、使えません🤔ちゃんとSeleniumやRequestsモジュールを使い、HTMLを前もって読み込んでおく必要があります。
Seleniumはなんでもこなせちゃうよ君☺️
そういうことで、
ページの種類関係なくダウンロードできる。
情報の抽出
クリック操作
キーボード入力操作
ができる
スクレイピング界のオールラウンダー、Selenium
なのですが、本当にそうなのでしょうか?まずは、Seleniumのみでテキストを抽出してみましょう!!
Seleniumを使ってテキストを抽出するには?
では実際にSeleniumを使って、サイトをスクレイピングしましょう。今回は、ローカルネットワーク上にあるjupyterにアクセスして、スクレイピングをおこなっていきたいと思います。
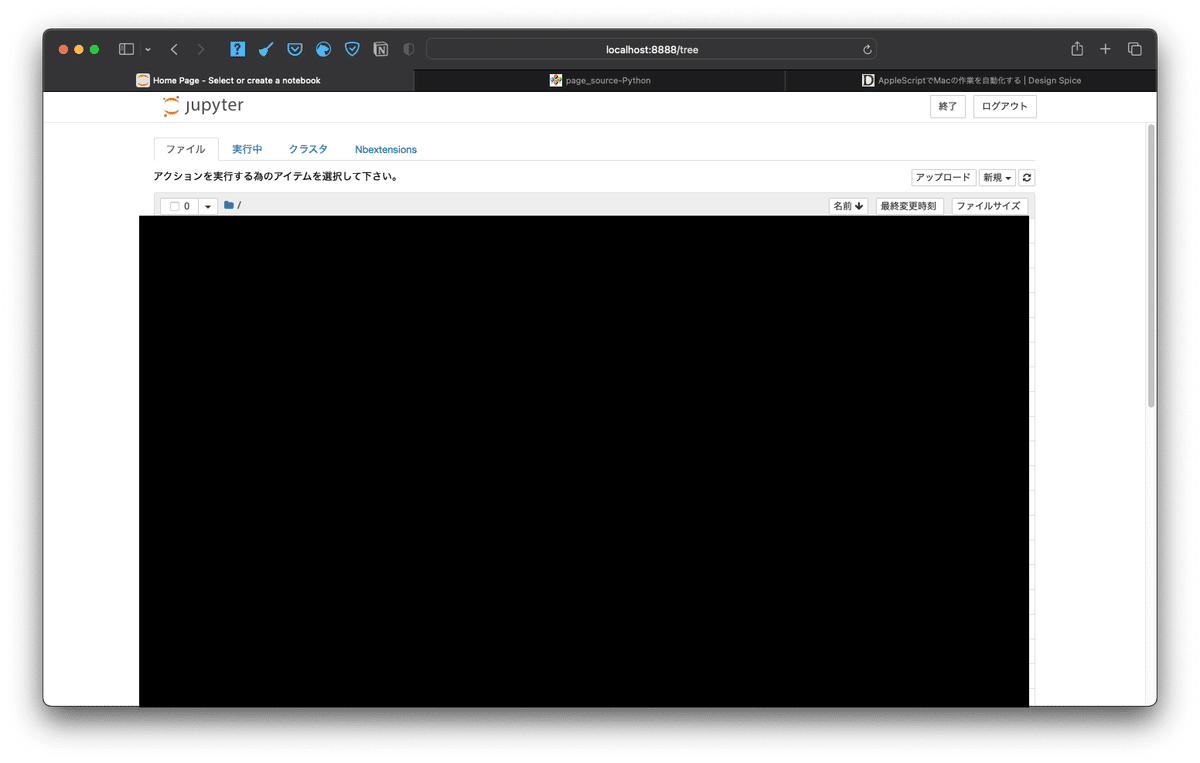
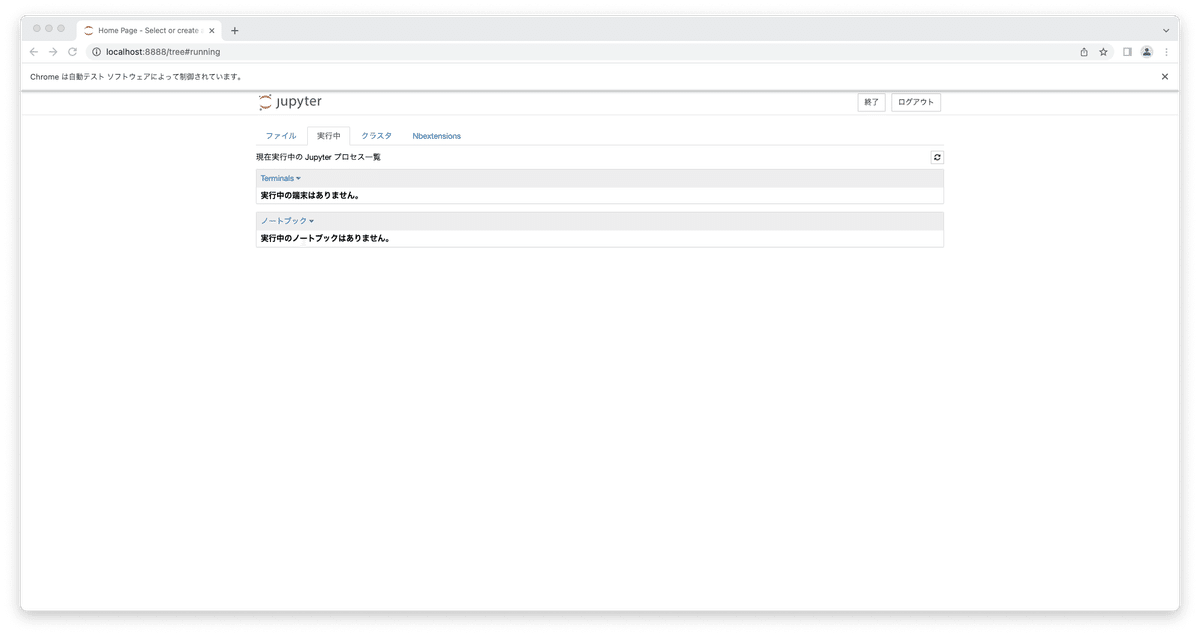
ひとまず、上の画像にあるように、 「ファイル」 の言葉を抜き出してみましょう!!さて、ファイルを抜き出すためには、
「ファイル」と書かれた要素の位置は何か?
ということなのです。この要素の位置をあらわす一つが、
「CSSセレクタ」
です。では、
情報を抽出したい「CSSセレクタ」
を抽出するにはどうしたらよいのでしょうか?ブラウザによって、「CSSセレクタ」の抽出方法が変わりますが、ここでは、Safariの CSSセレクタの抽出方法について説明しましょう☺️
<Safariで「開発メニュー」の表示の仕方>
1.左上にあるメニューバーSafariをクリックし、環境設定を開く。(もしくは、⌘「コマンド」+,「コンマ」)
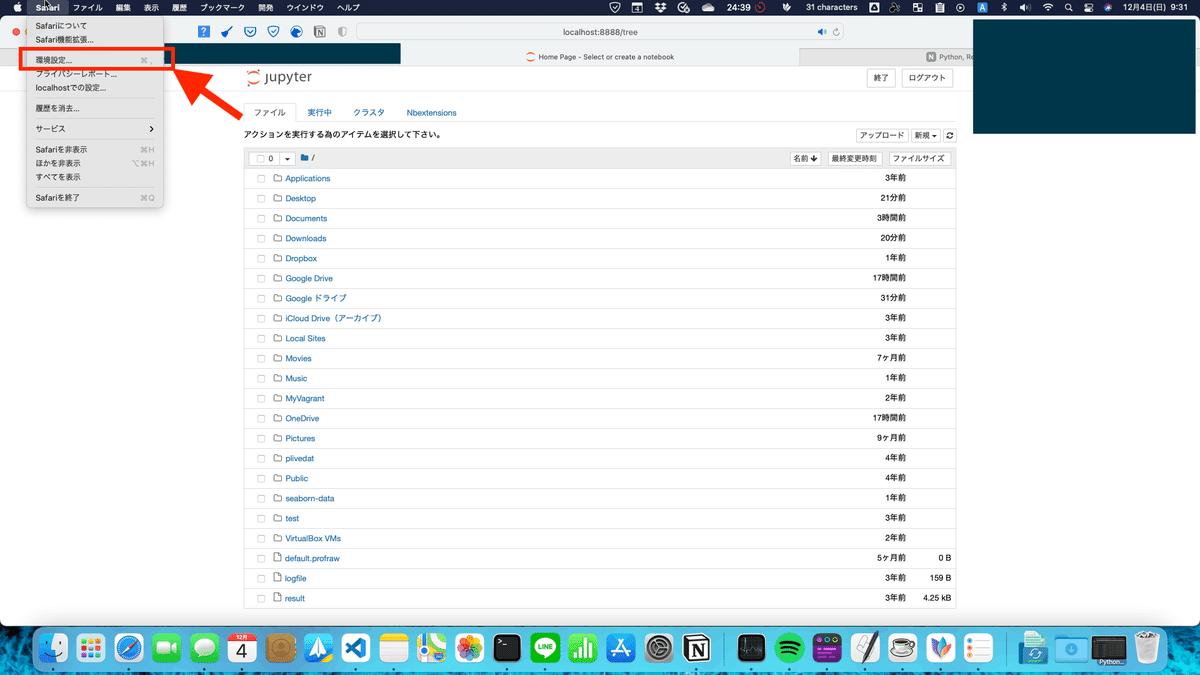
2.「詳細」タブをクリック。一番下の上級者の開発環境のチェックボックスをオンにする。
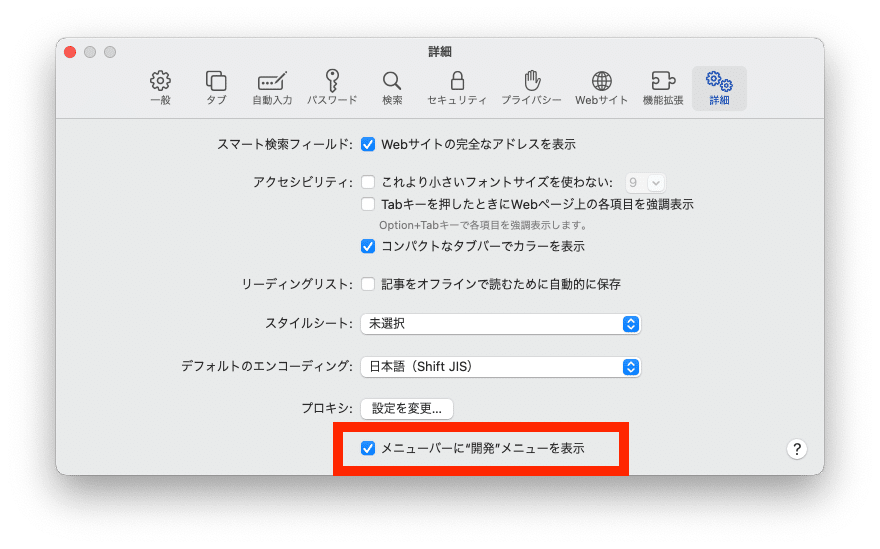
※Safariのメニューバーに 「開発」 と入っていれば、上の手順を行う必要はありません。
<Safari版のCSSセレクタの抽出方法>
1.Mac版のSafariを開き、サイトを開く。(ここではローカルにあるjupyterのサイトを開きました。)
2.「ファイル」と書かれた要素を右クリックし、要素の詳細を左クリック。
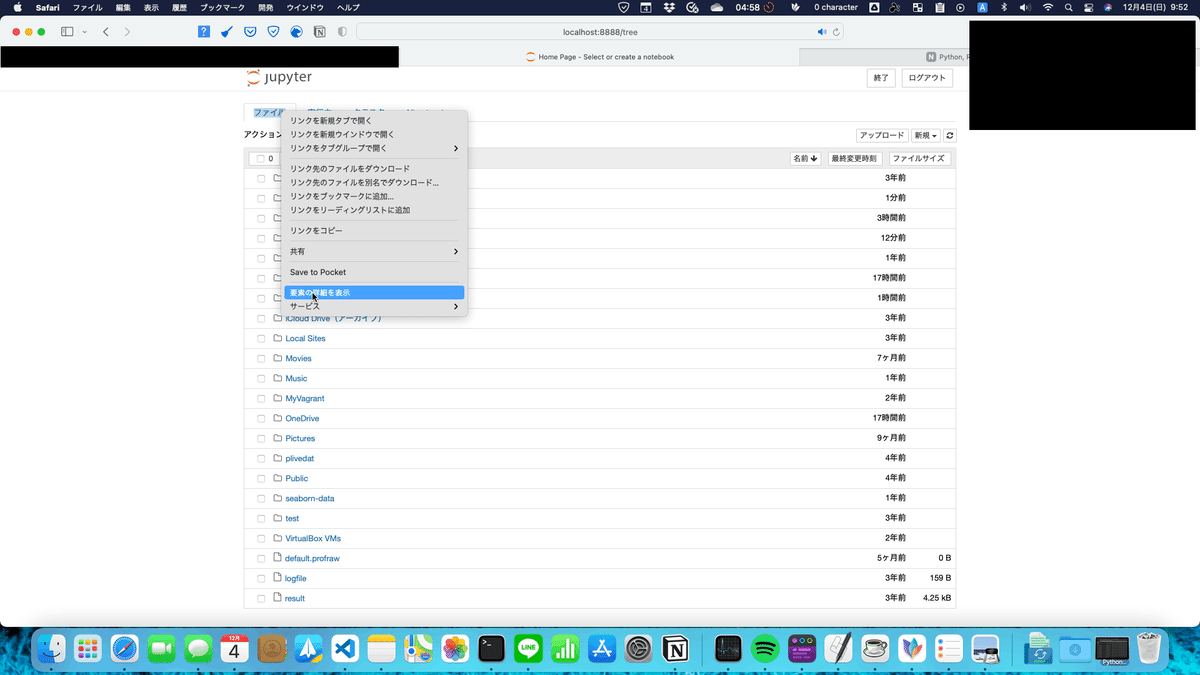
3.該当のソースコードが青く反転されるので、そのソースコードを右クリックして「コピー」→「セレクタのパス」に行って、左クリック。
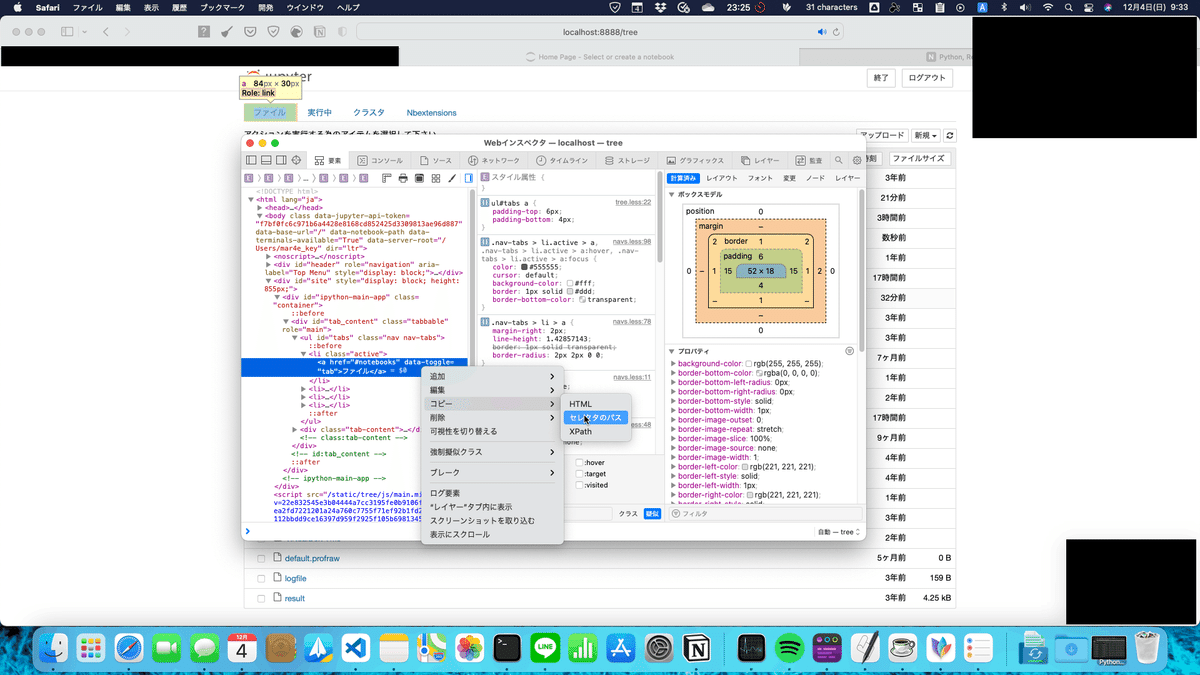
ソースコードは以下のようになります。
#必要なモジュール・・・1.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
#ChromeブラウザとSeleniumを連携する場合。・・・2.
s=Service(executable_path=ChromeDriverManager().install())
driver=webdriver.Chrome(service=s)
driver.implicitly_wait(30)
driver.get('<http://localhost:8888/?token=***>')#jupyter NoteBookが起動しているのが条件ですが、アスタリスク(*)はjupyter notebook listでパスがわかります。
#テキストを取得・・・3.
getnewsURLs_selector='#tabs > li.active > a'
TheName=driver.find_element(By.CSS_SELECTOR,getnewsURLs_selector).text
driver.close()#終わったら、ちゃんとcloseメソッドを使う!
#結果を表示。・・・4.
print(TheName)
⚠注意!!
ここでは、jupyternotebookを使って自分のパソコンの上で動いているjupyternotebookでスクレイピングしています。まずスクレイピングを本格的に行う前に、あらかじめブラウザでページを保存しておいて、ローカル環境から始められることをおすすめします!!
※ここではjupyter、Seleniumのインストールのやり方は省きます。Seleniumのバージョンは4です。Selenium3以前とプログラミングの組み方が若干違いますので、ご注意ください!!なお、ブラウザのエンジンは、Google Chromeを使っています!!
①まずは、下準備から始めていきましょう。まずは、必要なモジュールですが、
#必要なモジュール・・・1.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
となります。今回使用するモジュールから
from 〜 import ー
構文となっており、fromのモジュールから
一部のモジュール・クラス・メソッドなどを使いますよ〜〜
と宣言している構文となっています。
import構文について、詳しく知りたい方は、以下のNoteの「import構文を使ってモジュールからクラスだけを呼び出すには…?」を見てみてください↓
では、一つずつ解説していきます。webdriverモジュールですが、こちらは、スクレイピングするにあたって、一番基本となるモジュールを入れています。
次にChromeDriverManagerのモジュールですが、ですが、こちらは、
Seleniumを動かすChromeのバージョンを自動的に合わせてくれるモジュール
となります。いわゆる 「入れたら便利」 というツールです。ブラウザのバージョンが変わっちゃうと、動かなくなっちゃうので、入れることによって、
「自動的にバージョンのアップデート」
をしてくれます。
install()メソッドで、
ブラウザをスクレイピングさせるエンジンのパス
を返してくれますので、
入れておいてソンはないでしょう!!(Seleniumライブラリ単体では、動きません。ちゃんと事前にChrome専用のSelenium用のドライバーも追加でインストールしておく必要があります。)
また、Serviceクラスですが、
ブラウザをスクレイピングさせる本体のパスを設定
などを設定するクラスとなっています。こちらは、Seleniumがバージョン4以降に必要となるクラスともなりますので、前持ってインポートしておいてください!!
また、Byモジュールですが、こちらは、
CSSセレクタ
ID
クラス
XPath
などでどの要素かを特定し、
クリック
キーボードの入力
情報の抽出
するための前段階のモノとなっています。
それでは、インポートの文のコードが書けたら中身を書きましょう。
②それではSeleniumモジュールの設定を記述したクラスとなります。
#ChromeブラウザとSeleniumを連携する場合。・・・2.
s=Service(executable_path=ChromeDriverManager().install())
driver=webdriver.Chrome(service=s)
driver.implicitly_wait(30)
driver.get('<http://localhost:8888/?token=***>')#jupyter NoteBookが起動しているのが条件ですが、アスタリスク(*)はjupyter notebook listでパスがわかります。
基本的な流れは、
ServiceクラスでChromeをスクレイピングさせるエンジンのフルパスをexecutable_pathのパラメータに設定。
webdriver.Chromeのコンストラクタの引数のうち、serviceパラメータに1.で設定したServiceクラスを入れると、webdriver.Chromeのインスタンスオブジェクトが返ってくるので、driverの変数に格納しておく。(これで、情報の抽出やクリック、サイトの移動の操作などが可能になります。)
driver(webdriver.Chromeのインスタンスオブジェクトが格納されている変数)のget関数で、スクレイピングしたいサイトを設定する。
という流れになります。なお、
driver.implicitly_wait(30)
の意味は、各要素を見つけるまで、何か操作を実行するのを
「30秒待機する」
という意味になります。Webページの読み込みは
③それではテキストを取得します。
#テキストを取得・・・3.
getnewsURLs_selector='#tabs > li.active > a'
TheName=driver.find_element(By.CSS_SELECTOR,getnewsURLs_selector).text
driver.close()#終わったら、ちゃんとcloseメソッドを使う!!with構文を作るのもいいかもしれない🤔
#結果を表示。・・・4.
print(TheName)
上のコードではCSSセレクタでHTMLの要素を説明しています。CSSセレクタはホームページのデザインのときに使えるのだと思われがちなのですが、実はスクレイピングでも使えます!!
基本的な流れといたしますと、
①変数getnewsURLs_selectorに情報を抽出したいCSSセレクタの情報を格納。②find_element関数で情報の抽出し、textメソッドでテキストを取得します。
※ByパラメータにBy.CSS_SELECTORを指定し、(CSSセレクタで情報抽出しますという意味)1.で設定したCSS_SELECTORを2番目の引数に入れます。
③TheNameと呼ばれる変数にテキストを格納。
④driver.close()→使用した後は、これを忘れずに!!
では、CSSセレクタを抽出するにはどうしたらいいの!?
となるかもしれません。そして最後に、4.のprint関数で
「TheNameの変数の中身を表示する」
というわけです。それでは、ソースコードを実行していきましょう!!
ちゃんと、「ファイル」と表示されましたね!!
Seleniumでクリック操作してみよう!!
Seleniumでは、クリック操作が可能だと言われています。果たして本当でしょうか🤔????
百聞は一見にしかず
ということで、実際にコードを要素を見つけてやってみましょう。次はjupyterNotebookの「実行中」のタブをクリックすることにします。クリックのさせ方は簡単!!
では、実際にSeleniumで起動されたブラウザを見ていきましょう!!
使用したコードは以下の通りとなります。
#必要なモジュール・・・1.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWait#←BeautifulSoupを使う上で、ここが重要!!
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import requests
import datetime
beginTime=datetime.datetime.now()
s=Service(executable_path=ChromeDriverManager().install())
driver=webdriver.Chrome(service=s)
driver.implicitly_wait(30)
driver.get('<http://localhost:8888/?token=ff01ef46e5127bbcc33e1fb1b2cc4e0bfcf8fdccebebbaf0>')#←jupyter notebook listでのURLをコピペ
#クリック
getnewsURLs_selector='#tabs > li:nth-child(2) > a'
driver.find_element(By.CSS_SELECTOR,getnewsURLs_selector).click()#←重要!!
endTime=datetime.datetime.now()
driver.close()
#結果を表示。
print(f'処理時間:{(endTime-beginTime).total_seconds()}秒')#・・・4.−1。ちなみに、total_seconds()で秒数を出している。
要するに、クリックさせたい要素のところをターゲットで絞って、click()メソッドを使うだけでOKです!!
#クリック
getnewsURLs_selector='#tabs > li:nth-child(2) > a'
driver.find_element(By.CSS_SELECTOR,getnewsURLs_selector).click()#←要素を特定して、クリックメソッドを使うこれだけ!!
クリックしたあとをブレイクポイントに指定し、デバッグモードで起動して、実際に実行してみましょう!!
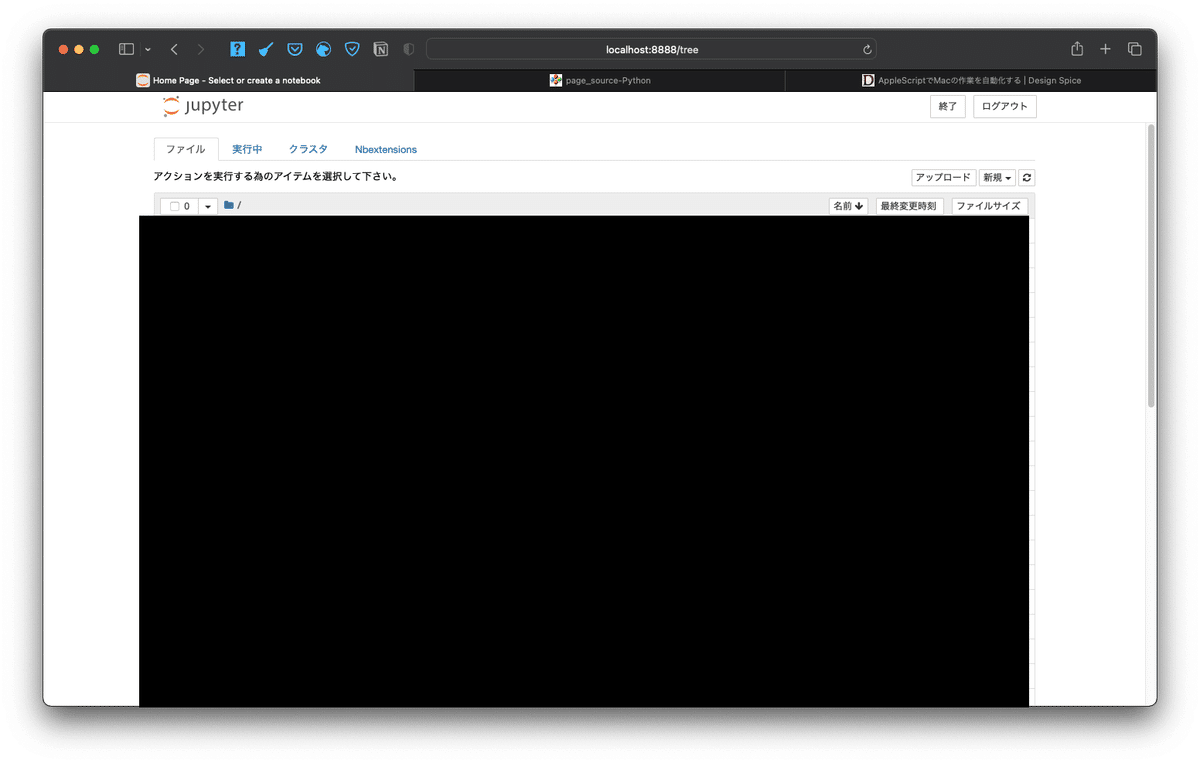
このように、Seleniumでは、クリックしたい要素をクリックできるのが、
Requests×BeautifulSoupの最大の違い
であると言えるでしょう!!
Seleniumのデメリット
ただ、Seleniumは、高機能とは言っても、Seleniumには欠点はあります。それは、
「時間がかかりすぎる」
ことです。クリックの操作が必要ないのに、Seleniumを使ってしまうと、時間がかかってしまうことがたたありますし、相手側のサーバーの状態によっては失敗することも出てきます。では、先程のコードの場合、何分かかっているのかを検証してみましょう。やり方はカンタン!!
「はじまり」と「おわり」時間を取得(1.−1を参考。)
「おわり」-「はじまり」の時間を引く=処理時間(4.−1を参考。)
total_seconds()を使い、実際の秒数を出す。
という流れでコードを書いていけばよいのです。それでは、下のコードを参考に実際にやってみましょう!!
#必要なモジュール・・・1.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import datetime
beginTime=datetime.datetime.now()#・・・1.−1
#ChromeブラウザとSeleniumを連携する場合。・・・2.
s=Service(executable_path=ChromeDriverManager().install())
driver=webdriver.Chrome(service=s)
driver.implicitly_wait(30)
driver.get('<http://localhost:8888/?token=***>')#←jupyter notebook listでのURLをコピペ
#テキストを取得・・・3.
getnewsURLs_selector='#tabs > li.active > a'
TheName=driver.find_element(By.CSS_SELECTOR,getnewsURLs_selector).text
driver.close()#終わったら、ちゃんとcloseメソッドを使う!!
endTime=datetime.datetime.now()
#結果を表示。・・・4.
print(TheName,f'処理時間:{(endTime-beginTime).total_seconds()}秒')#・・・4.−1。ちなみに、total_seconds()で秒数を出している。

結果をみると、
なんと、10秒くらい
かかっていますね🤔💦Chromeのブラウザを立ち上げてから、処理を行うので、時間がかかることがわかります。Seleniumだけでも終わることができますが、特定のページで複数の要素を検索したいとなると、Seleniumだけでは失敗する可能性も無きにしもあらずです🤔
そういうときは、
「HTML」 にしてBeautifulSoupにわたすことで、完全ではありませんが、
「失敗のリスクを下げる」
ことも可能です。そこで、BeautifulSoupの出番がやってくるわけです。
BeautifulSoupは情報抽出の猛者
BeautifulSoupは単体では、HTMLをダウンロードできないので、
HTMLの解析をすることができません。
次に説明するrequestsや、seleniumを使って、前もってHTMLを読み込んでおく必要があります。 では、情報の抽出の部分だけ、
BeautifulSoupにやっていただきましょ〜🤗
ということで、先程のSeleniumでのコードをもうちょっと足していきましょう。②が足した部分です。それでは、②のコードについて解説していきます。
#必要なモジュール・・・1.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWait#←BeautifulSoupを使う上で、ここが重要!!
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import datetime
beginTime=datetime.datetime.now()
s=Service(executable_path=ChromeDriverManager().install())
driver=webdriver.Chrome(service=s)
driver.implicitly_wait(30)
driver.get('<http://localhost:8888/?token=***>')#←jupyter notebook listでのURLをコピペ
#見つけたい要素があると確認した上で、HTMLに落とし、BeautifulSoupに落とし込む🤔
getnewsURLs_selector='#tabs > li.active > a'
element=WebDriverWait(driver,60).until(EC.presence_of_element_located((By.CSS_SELECTOR,getnewsURLs_selector)))#←①指定の要素が来るまで待機。
htmlData=driver.page_source#←②HTMLに落とし込む。
driver.close()
soup=BeautifulSoup(htmlData,'html.parser')#←③BeautifulSoupにHTMLを読み込ませる。ここではhtml.parserはおまじないと思っておきましょう☺️
TheName=soup.select_one(getnewsURLs_selector).text #これで
endTime=datetime.datetime.now()
#結果を表示。
print(TheName,f'処理時間:{(endTime-beginTime).total_seconds()}秒')#・・・4.−1。ちなみに、total_seconds()で秒数を出している。
まず、Seleniumのモジュールを使って得たHTMLのコードを落としていくには、
①まず、WebDriverWaitクラスを使って、指定の要素が来るまで待つように指示。
※WebDriverWaitは簡単に言うと、指定の要素が出てくるまでに待機する役割を果たします。
②page_sourceメソッドを使って、HTMLに落とし込む。
というふうにコードを書いていきます。次に
③bs4モジュール(通称BeautifulSoupモジュール)のBeautifulSoupを使って、HTMLの解析の準備ができるようにしていきます。
これでBeautifulSoupでのHTML解析が可能になりました。
さて、②の
「page_source」メソッド
についてですが、間違っても、
「page_source()」
にしないように気をつけてくださいね。(ココテストに出るかも…🤔)
それでは、気を取り直して実行してみましょう。

そうすると、さきほどのSeleniumでの要素の抽出と同じことができたことがわかります。
あれっ!?変わらないよ。
と思われたのかもしれません。ですが、要素の抽出が多ければ、時間の計測は少し変わっていたように感じます。では、RequestsとBeautifulSoupの連携プレイでは時間はSeleniumとどれだけの違いがあるのでしょうか?引き続き検証していきます!!
では、Requestsはどんなときに使ったらいいの🥺
みなさん、こう思われたことはないでしょうか?
じゃぁ、Requestsはどんなときに使ったらいいの!!?💢
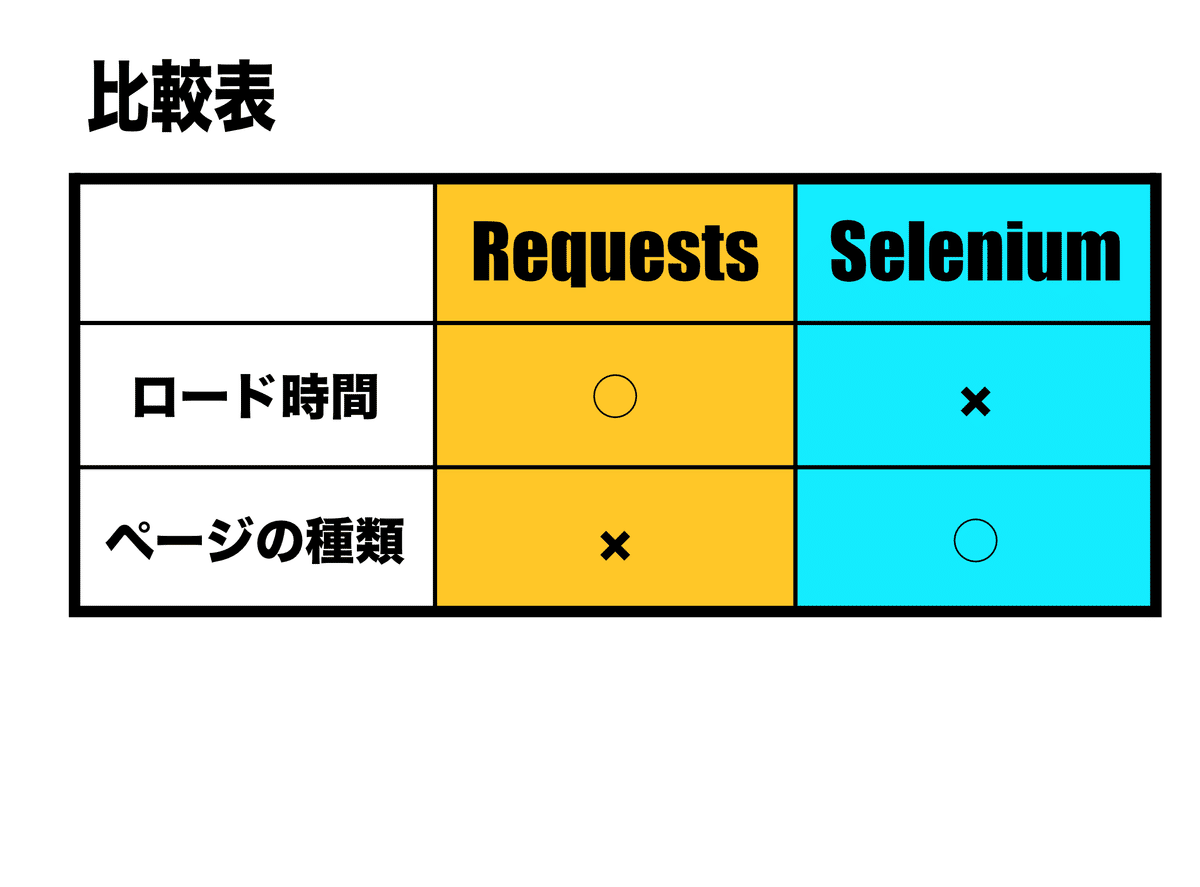
と。簡単に言うと、Javascriptが使われてないページをダウンロードするモジュールです。Requestsは、Javascriptが使われているページはダウンロードできませんが、動作はSeleniumよりも軽いメリットがあります。
RequestsとSeleniumの使い分けを表にまとめて見ました。
じゃぁ、Javascriptを使って読み込む必要があるのかってどうやって判断するの?どうやったら、わかるの?
ということですが、
まずは、Chromeなどのブラウザで、HTMLのページだけ保存する機能があるので、そこから、
Seleniumを使うか、Requestsを使うか判断
すれば良いでしょう。もし、HTMLのページで保存し、実際にブラウザで中身を見て、
ほしい情報が入っていなければ、Seleniumを使う
ようにしましょう。それでは、前置きはこれまでぐらいにして、実際にコードを打ち込んでみます!!
くどいようですが、コードをひたすら打ち込むのも練習の一つです!!コピペ(コピー&ペースト)で済ますのではなく、実際にコードの模写を行ってみましょう!!
from bs4 import BeautifulSoup
import requests
import datetime
beginTime=datetime.datetime.now()
getnewsURLs_selector='#tabs > li:nth-child(1) > a'
URL='<http://localhost:8888/?token=***>'
response=requests.get(URL)
soup=BeautifulSoup(response.text,'html.parser')
tabName=soup.select_one(getnewsURLs_selector).get_text()
#結果を表示
print(tabName)
endTime=datetime.datetime.now()
print(f'処理時間:{(endTime-beginTime).total_seconds()}秒')
簡単に説明しますと、Seleniumを介さず、
Requests
↓
BeautifulSoup
に変えたことで、コードが今までよりもスッキリしました。
まず、requests.get関数でHTMLコードを取得。responseと名付けた変数にインプット。
textプロパティを使うと、HTMLコードが出てくるので、その引数を使って、BeautifulSoupにインプット。
BeautifulSoupを使って「ファイル」のタブのテキスト内容を読み込む。
という流れでコードを組んでみました。
すると、

なんと、処理にかかった時間が
0.18秒!!
さきほど、Seleniumと比べて、驚異の処理速度ですね😳それもそのはず🤔
Javascriptでのページの内容変更は
「一切起こっていません」
ので、すばやくダウンロードできるというわけです。(PCの環境やネットの環境によって、処理の時間が前後します。)
余談:使い分けってお互いの負荷を考える思いやり?
Noteを執筆してみて思ったのですが、極力BeautifulSoupとRequestsで済ませられる工夫をすることで、実際のロード時間を
「短縮」
することができるんじゃないのかと思いました!!あと、Scrapyってツールもあるみたいですね🤔う〜ん、Seleniumと対決させてみたい〜💪🔥
いかがでしたでしょうか?
僕も最初は、
BeautifulSoup
Requests
Selenium
の使い分けに関しては曖昧なままずっといっていました。ですが、調べるたびに、
3つを区別して使った方がよいと感じるように、そして、将来のための備忘録
として、このNoteを書きました。では、また次のNoteにてお会いしましょう!!
P.S.
scrapyのライブラリも個人的には気になってます😳