【Python】Tensorflow入門

前書き
機械学習の記事を読んでいるとちらほらTensorflowだったりPyTorchというワードを見かけてふんわりと理解はしているものの実際に叩いたことはないな?と思ったので今回触れてみます。
公式クイックスタート
どんな時もとりあえず公式からです。
Colab上だとインストール済のようですが、個人の環境で実施する場合には事前に取得しておきましょう。
pip install tensorflowとても訳のわからないモノ
公式クイックスタートを見ていくとコードは書いてあるものの説明文が驚くほど少ない。とりあえず叩けば動くよ!というレベルの記載であったのでなんとか嚙み砕いてみる。
まずはインポートからテストデータの準備まで。
# インポート
import tensorflow as tf
# テスト用データ
mnist = tf.keras.datasets.mnist
# train:モデルのトレーニング用データ
# test:モデルのテスト用データ
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0tensorflowにはとりあえずで使ってみるために28×28サイズの画像データが用意されている。その画像データをtf.keras.datasets.mnistで取得し、モデルの訓練用データ(_trainと記載があるデータ)とモデルのテスト用データ(_testと記載があるデータ)に分ける。ここでx始まりの変数には28×28の画像データ、y始まりの変数には画像のラベル(要は画像のジャンル名)が格納されている。
ここでモデルに落とし込むには画像の正規化を行う必要があるため、255でそれぞれ割っている。なお、255は画像の最高輝度値に当たるため、255で割ることで画像は0~1の範囲に収まるデータとなる(これが正規化された状態)。
テストデータについてはコチラを参照
ちょっとイメージが付かなかったので私は以下のコードを実行してテストデータとなる画像を1枚出力してみました。
import tensorflow as tf
import matplotlib.pyplot as plt
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
plt.figure()
plt.imshow(x_train[0])
plt.colorbar()
plt.grid(False)
plt.show()
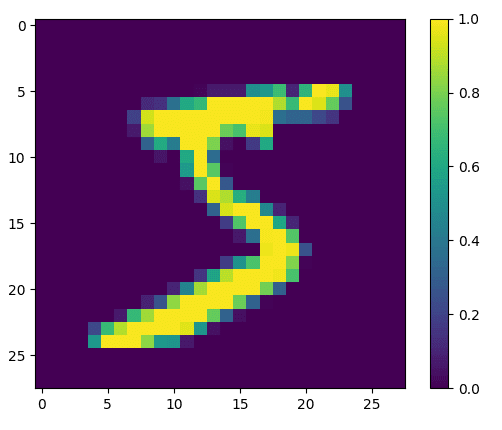
実行結果は以下となります。正規化後の値を出力しているので最大値が1.0かつ28×28サイズの画像データとなっていることが分かりました。
次にチュートリアルでは機械学習モデルとなるSequentialモデルを構築しています。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])サッパリですので1行ずつ見ていきます。
まず全体としてはSequentialモデルの中に複数レイヤーを持たせることでモデルとしての処理を行っているようです。
まず1つ目のフィルター、tf.keras.layers.Flattenは入力画像28×28サイズ(正確にはピクセル)を1ピクセル単位で分解して1次元配列に変換しています。28×28なので784ピクセルですね。
次に2つ目のフィルター、tf.keras.layers.Dense、私はココで詰まりました。ニューラルネットワークの知識が必要になるようで、前の層と次の層の全ユニットを結合させる全結合層を作るためのフィルタらしく、前後層と結合した結果、重要なデータには重みづけを行い、あまり重要じゃないデータは無視、といった処理をしているようです。そのうちニューラルネットワークについては学んでみます。
次に3つ目のフィルター、tf.keras.layers.Dropout、これは過学習(訓練データについてはモデルが処理できてるけど、訓練しすぎて訓練データしかちゃんと処理できてないよね?の状態)を防ぐためにランダムでいくつかの値を無視(ドロップアウト)しようといったフィルタになっています。
最後の4つ目のフィルターは2つ目のフィルターと同じっぽいですね。最終的に10個のジャンルとして結合させる、という意味合いだと捉えています。
モデルの定義が終わったので次は実際にモデルの訓練を行います。
# 損失関数
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# モデルの訓練方法を定義する
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
# トレーニングデータを使ったモデルの訓練
model.fit(x_train, y_train, epochs=5)
# テストデータを使った評価
model.evaluate(x_test, y_test, verbose=2)損失関数、というのもニューラルネットワークを学ばないとピンとこない用語ですが、要はモデルが理想と実態がどれくらいかけ離れているかを評価する関数です。損失が小さい(0に近い)ほどモデルとしての完成度は高いです。
compile関数の部分でモデルをどのように訓練するかを指定し、optimizerには最適化の手法(学習量が多いので都度最適化が求められるので)、lossは先ほどの損失関数、metricsにはモデルのパフォーマンスを判断するのに使用する関数となっているようです。ここの定数については公式ドキュメントを参照ください。
訓練方法を定義した後は実際の訓練及び評価を行っています。一応補足として訓練時のepochsは1つのデータを何回繰り返して学習に用いるかの値となっており、評価時のverboseは評価の進行状況を表示するかどうかです。verbose=2は進行状況は非表示にして評価結果のみを表示するパラメータのようです(逆に見たい場合は1を指定してください)。
最後はモデルのレスポンスを確立値で出力できるようにトレーニング済のモデルをラップしてsoftmax関数に接続しています。
probability_model = tf.keras.Sequential([
model,
tf.keras.layers.Softmax()
])公式では最後にモデルを通して確立値を出力して終了。なんとなくイメージがついたようなついてないような。。。
公式画像分類ガイド
クイックスタートよりイメージが付きやすいガイドもちゃんと存在していましたので続けて紹介します。
使っているテストデータは異なりますが、モデルを訓練、評価して最後にラップする部分までは概ね一緒ですね。ラップ後はテストデータを用いて実際に入力画像からアウトプットである10分類に振り分け予想を行っています。
predictions = probability_model.predict(test_images)上記を実行することでpredictionsの中には予測結果となる「入力画像データ数×10分類」の配列が出来上がりました。
最終的にはガイドの通り、可視化関数の追加を行って出力して終わりですが、概ねmatplotlibの範疇なので割愛します。
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
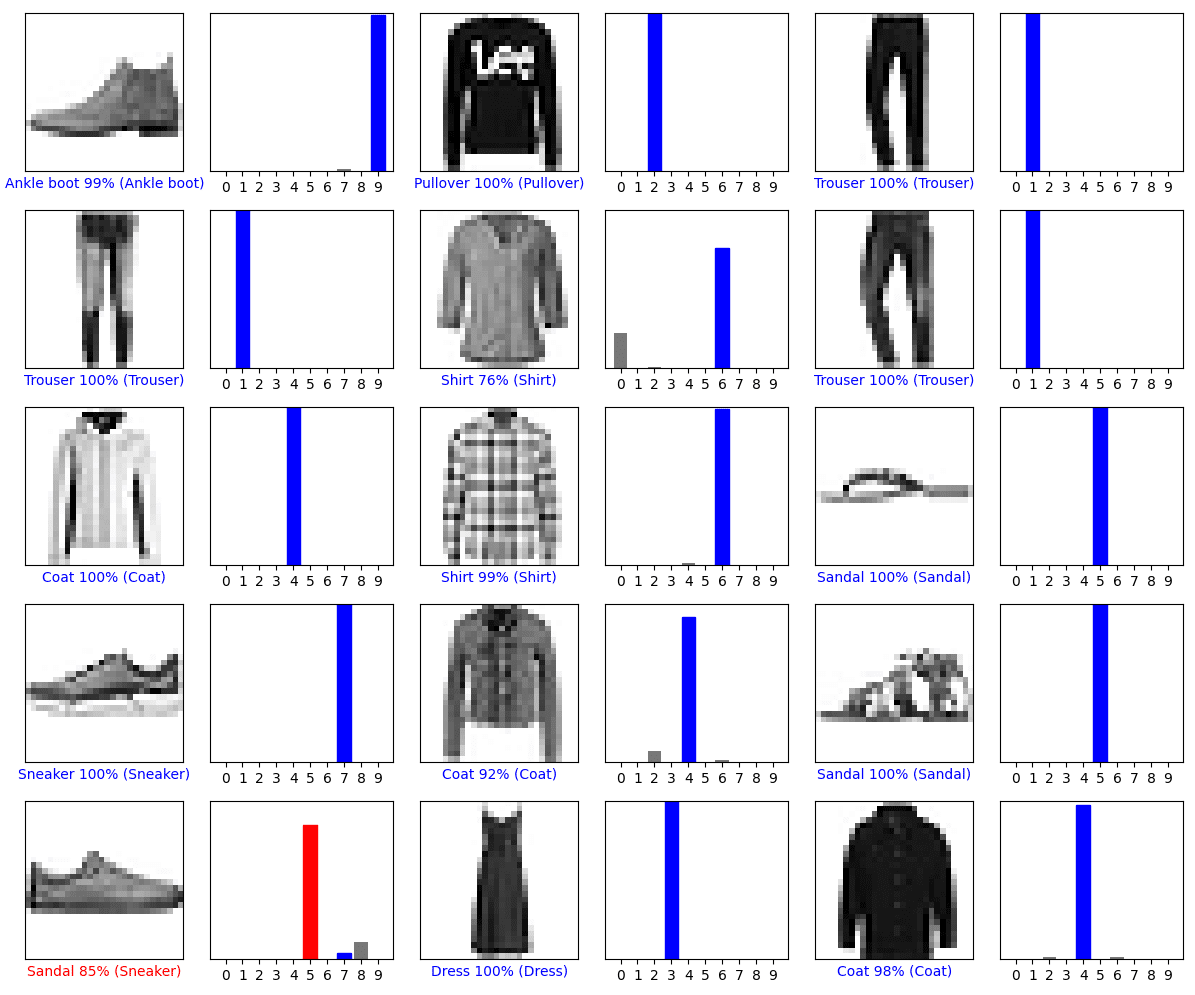
plt.show()出力された画像がこちら青色は正解のケース、赤色は不正解のケースです。
所感
今回入門レベルでTensorflowに触れてみましたがやはりニューラルネットの知識が必要そうですね。勉強します。
また、今回は28×28ピクセルの画像データを10分類に分けるというものでしたが、画像サイズが異なる場合や分類数がもっと多い場合、とんでもない量の画像データが必要になると思うので別の技術を組み合わせていくのだと思います。あるいは画像ではなくテキストを入力にするのか、など。今後も機会があれば触ってみたいと思います。