Labviewで大容量CSVファイルから指定ラベル値のみを抽出 その2(フリー)

1.7GBのCSVファイルで試してみる
前回のLabview使った大容量CSVファイル操作の延長戦です。
実は新たにCSVファイルを強化して実験をしてみました。
とりあえず図1の1.7GBの核兵器作ってみました。もう開こうとする事が間違いかもしれませんが、お役所様にそんな事は通用しません。

とりあえずExcelで開いてみます。
大体2.5GBくらいRAMってますね~(図2)
ちなみにここから関数使って計算したりして、.xlsxで保存するともれなく終了しますので、覗くだけにしておきましょう。

で、前回のVIを走らせてみると、こうなる。
はい、止まりましたね~もうRAMれなくなってディスクにも手を出してしまいました。典型的な多重債務の一例ですね。


なんでこんなにRAMっちゃうの???
答えは"区切られたスプレッドシートを読み取る" VIにありました。
実はこれ、分解していくと大量の変数とトンネルが使われています。
これでは大量のコピー処理が発生して撃沈してしまいますよね。
こういった無駄なデータフローは削減しちゃいましょう。



"ファイルから行を読み取る"VIまで落とし込んでみる
さくっと書いちゃいましょう。

んで実行すると・・・
RAMりきれなくなるのは変わらないですが、ディスクへのコミットが少なくなり、常識的な時間で終了しました。
前回よりかは改善されましたが、これでもまだまだ多いですね。お役所様のお怒りは収まりません。



もっとVIを分解してみる
図12のVIはもう少しバラせそうなのでいっちゃいましょう。
非常に使いやすいVIですが、ミンチになって頂きます。

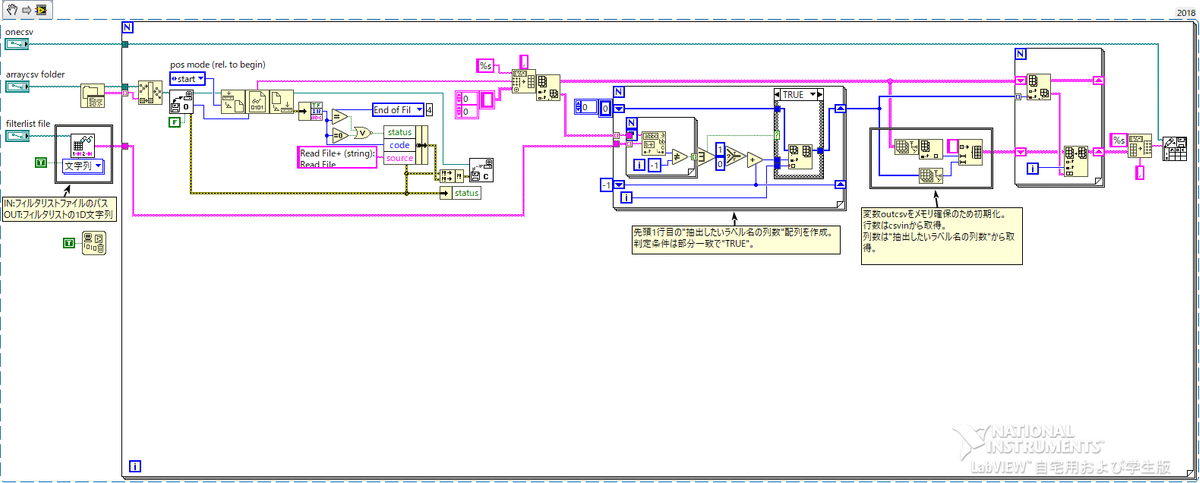
最終的に図13の通りになりました。
VIはこちら。(Labview2017用です)
これで、その1で処理したデータをぶちこんでみます。
ベンチマーク結果は下記の通りです。
※VI処理時間測定方法は NI公式HP のティックカウント関数を用いた方法です。計測結果の小数点以下第三位を繰り上げた結果を記載しています。
n1: 11.96sec
n2: 12.17sec
n3: 12.40sec
n4: 11.97sec
n5: 11.79sec
大体12秒あたりですね。その1と比較して-3秒達成です。
これ以上早くならないの???
私の弱い頭ではこれが限界でした。すいません。
もっと良いやり方あったら教えて頂きたいです。
データフローはかなり意識しており、メモリ空間での操作は必要最小限になるように作ったつもりです。
forループの並列処理も試しては見たのですが、シフトレジスタを使えないという制約をクリアするためにアルゴリズムを変えると、逆にメモリ区間での操作が増えてしまい、遅くなるという結果になりました・・・
最終段の、オリジナルcsv配列から指標配列で1D配列を抜き出した後に、トンネル(指標)で抽出後2Dを出力すると、行列が転置されてしまいます。
それを更に転置すると余計にメモリとCPUを食ってしまいます。(あまり美しくなかったので却下)
次回:メモリ削減バージョン
皆さんなら既にお気づきかもしれませんが、図13のVIは処理時間最速を目指して作っているので、PCのスペックの事は何も考えていません。
有り余るメモリがあって初めて実行できるので、一般useだとちょい厳しいか無理かもしれないので、配列処理をもうちょい工夫してメモリ使用1GBに抑えて作りたいと思います。その分処理時間は伸びますが、普及版という事で。