
AIスタートアップのMoat(その1)、ブランド、ネットワーク効果、スイッチングコスト、データ戦略

Coreline Ventures(元DCM Ventures)の原です。5年前にこちらの記事でスタートアップのMoat(参入障壁)をできる限り網羅的に概要を説明しました。
2022年後半より、Gen AIが世界を席巻し、様々な働き方と既存のソフトウェアのあり方を変え、新たな機会と脅威を生んでいます。その中で、AIスタートアップにとって「どのMoatが最も大事で、どう築いていくべきなのか」、それぞれ10個のMoatに沿って、現状の論点と仮説を書いていきたいと思います。(この記事はAIを用いて書いておらず、人間が書いているので、誤字脱字にはご勘弁を。)
ただし、現在は2025年2月、まだAIスタートアップのMoatの築き方には未知の点も多く「仮説」としました。なのでこの仮説も継続してアップデートしていきたいと思っています。
現在Coreline Venturesでは日本の投資先の大半が教育、製造業、営業、物流、B2Cなどを対象にしたAIネイティブの会社になっており、これらの投資先と日常的に議論している内容が思考のベースになっています。(投資先の皆さんありがとうございます!)
僕の定義として、AIネイティブ企業とは基盤モデルのAPIが使用不可能になると事業継続不可能な会社です。一方その他AI利用企業(AI enabled企業)は、これまでのプロダクトの一機能としてAIを使っておりAPIが使用不可能になっても事業存続可能 (例えば機能として日報サマリ作成AI、営業SaaSの資料作成AI、ワークフローの音声入力など)です。
はじめに
過去の記事でMoatとして説明したものは、下記の10個です。AIスタートアップになっても大きくこのリストは変わらないものの、その重要性に変化があるかなと思いました。この記事ではそれぞれの意味は少し触れるにとどめますので、気になる方は元記事をご覧ください。
Moatの10項目
1. ブランド
2. ネットワーク効果
3. 囲い込み/スイッチングコスト
4. 第一想起 (top of mind)
5. 規模の経済/初期投資やCAPEXの大きさ
6. コスト優位性
7. 免許/許認可/特許/排他的な契約
8. ユーザーへのアクセス/ディストリビーションチャネル
9. 卓越したオペレーション(オペレーショナルエクセレンス)
10. テクノロジー優位性
また、今回のMoatの仮説は、アプリケーションレイヤーのスタートアップを想定して書きます。2025年2月時点で日本のAIスタートアップの大多数がアプリケーションレイヤーのスタートアップだと考えられますし、オープンウェイトモデルの登場により、基盤モデルの高品質化と低価格化が進み、アプリケーションレイヤーに大きなチャンスがあると感じているからです。
この記事では、各項目の、簡単な説明、AIスタートアップにとっての重要性、現状(このMoatをうまく使っているスタートアップの例)、論点、仮説、と分けてそれぞれ議論していきます。
1. ブランド (AIスタートアップへの重要性: 大)
ブランドとは、全く機能と価値が同じプロダクト/サービスであっても競合から高い価格を取ることを可能とする無形の競争力です。
現状
現在AIチャットアプリでも「聞いたことがある企業」が多くのユーザーを獲得しています。ChatGPT(アプリケーション)が、Claude(アプリ)やGrok(アプリ)やGemini(アプリ)より、多くのユーザーを獲得し、圧倒的に「高い」ものの課金にも成功しています。
一般ユーザーではChatGPTは知っているけれど、その他のモデル企業のアプリは知らない、という人がかなり多いです。これは、必ずしもそれぞれ使用しているモデルのGPTシリーズ、Claude3.5/3.7やGemini2.0やGrok2/3の性能の違いから来ているわけではなく、ユーザーへの認知やブランド力から来ていると考えられます。
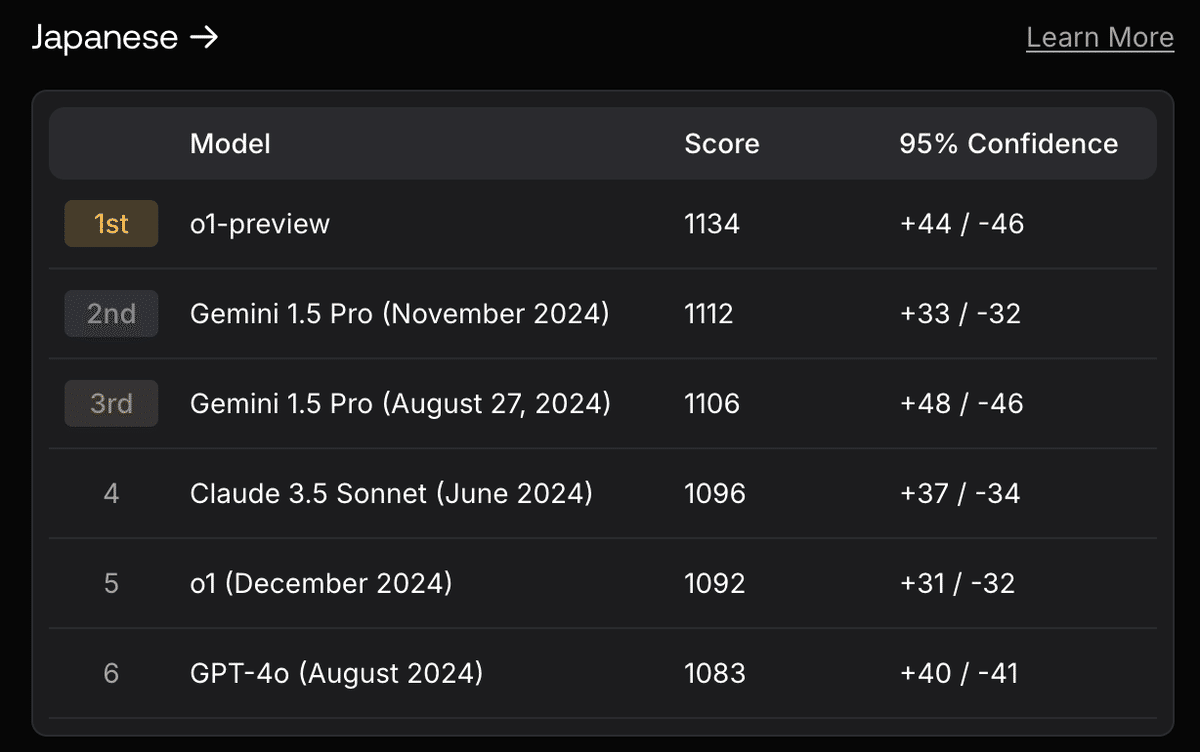
このように、ブランド力は、現在AI企業の競争力の源泉となっている強いMoatの一つです。
論点
AI企業にとっての、「ブランド」とは何でしょうか。今後もそれは重要となり続けるでしょうか。また、その「ブランド」をいち早く築くためにはどうすべきでしょうか。
仮説: ブランド構築には"信頼"が最も大事
今後もAIチャットにおけるChatGPT同様、しばらくの間ブランドは重要であり続け、B2Bアプリケーションにおいては「より重要」になってくると考えております。特にそのブランド力は「信頼と安全性」から来ることになると思います。顧客企業が認める公式ツールとして認められるか、それを決めるのは「信頼」だと思っています。
理由としては、1. AIは効果が強いのに「人間にとってはブラックボックス性が強い」、2. AIは強力なのに「安全性が低いものになりうる」、の2つです。
人間は自分たちがその仕組みがわからない「ブラックボックス」で効果が強いものに対しては、より「信頼」を求める傾向にあるように見えます。
例えば、処方薬をもらうときにも、なぜか「圧倒的に安いのに」が、ジェネリック薬ではなく先発医薬品を求める方はまだいますし、金融商品でも手数料が高いけれどよく知っているファンド/企業を選ぶ方もいるかと思います。
次に、AIは「強力な反面、安全性が低いものになりうる」というツールだからです。
今後LLMエージェントは、顧客企業のデータベースを参照するだけでなく、更新を行うようになるかもしれません。数万件、数十万件のemailや電話を顧客にかけ始めます。もしそこで間違いがあればどうなるか。電話で間違った情報、顧客を怒らせる表現をしていたらどうなるか。
AIは数十万人分の人間の作業が行える強力さがあるからこそ、そこに安全性のリスクが出てきます。
そのような現在の環境下では、「信頼」がある企業の製品が選ばれており、このトレンドはしばらく続くと思います。
信頼の獲得方法
「効果は同じと聞いているけれど、こちらのほうが安心する」
AIでもジェネリック医薬品同様に、まだ中身やその成り立ちがわからないし、なんとなく聞いたことがあるツールを使うフェーズかもしれません。
ただし、将来的に、徐々にユーザーがAIツールに慣れてくるにつれ、価格が安いツールを選ぶようになるかもしれません。現にジェネリック普及率もこの15年で30%台から80%を超えるまでになりました。ただし、それは2-3年で起きるわけではなく、徐々に10年くらいをかけてゆっくりと起きてくるのではないかと思います。
一方でその中でも、スタートアップ企業としては、誰よりも早く「信頼」を勝ち取り「ブランド」を築きたい。でも、これはAI企業だけじゃなく、かつてのSaaS企業がクリアしてきた壁です。
これらは実際に僕らの投資先が使い、新しい企業ながらうまく業界最大手のお客を獲得していった例の一部です。
- 大手企業とディストリビューションのパートナーシップを組む
- とにかく安くロゴを獲得して、「使われている」実績を作る
- できる限り業界を絞り、業界内でのシェアを上げて、その業界で「使われている」実績を最大化する
- 最初は導入しやすい(つまりスイッチ/チャーンしやすい)ツールから入り、徐々に信頼を勝ち取ったうえで、顧客企業にとって、より「信頼」が大切な機能を売る
- 自分たちで、製品評価の指標を作り、業界にとっての「信頼」の基準を自ら作る
2. ネットワーク効果 (AIスタートアップへの重要性: 現状では小)
ネットワーク効果とは「新しいユーザーが一人増える度に、"既存"ユーザーにとってサービスの価値が上がる」効果のことで、これまでのインターネット時代のMeta(Facebook)、Tencent (Wechat)、LINEなど各国で大手テック企業を作ってきた、インターネット時代の最重要Moatです。
現状
インターネット時代のMoatの王者であるネットワーク効果ですが、現在ではネットワーク効果を活かしたAI企業は現れていません。
AIのB2CアプリケーションにおいてもB2Bツールにおいても、ユーザーとモデル/データベースとの間でのやり取りがあるだけで、ユーザー間でのコミュニケーションは発生していません。
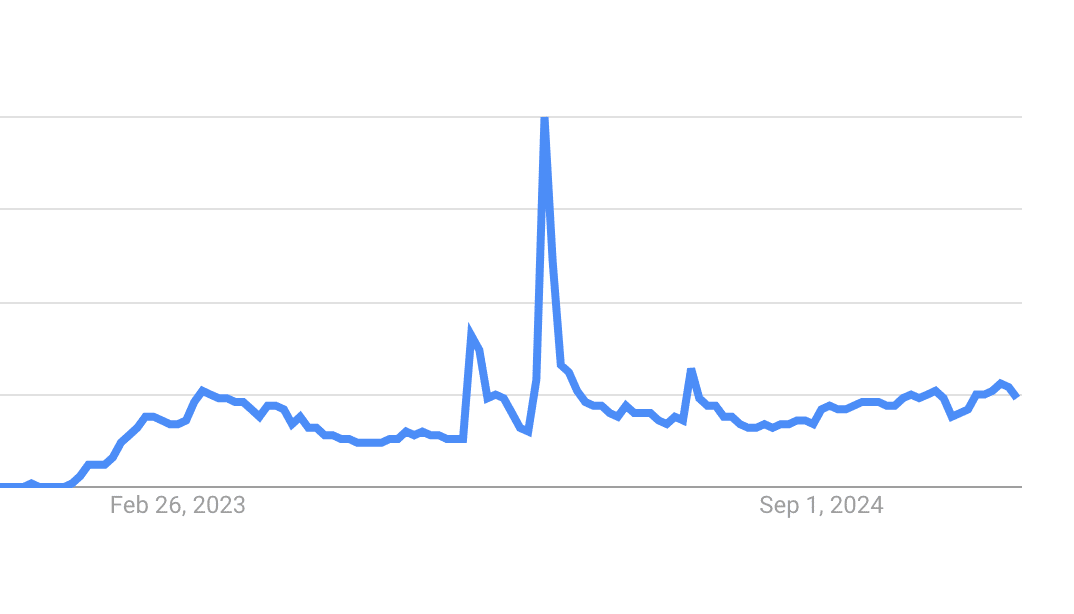
OpenAIが開発者とユーザーの間のネットワーク効果を狙い、GPT Storeというアプリストアのようなものを2023年秋に発表、2024年1月にローンチしましたが、その後は下記のように注目を集めていないようです。この状態ではいくらOpenAIと言えどネットワーク効果を作れているとは言えなそうです。
論点
果たして、ネットワーク効果はAI企業にとっては、関係のないMoatのままでしょうか。インターネット時代のMoatの王者、ネットワーク効果が再び重要性を増すとしたら、何がきっかけになるでしょうか
仮説: 現状はまだ誰も見つけられていない
ネットワーク効果が再び覇権を取るかはわかりませんし、今のところアプリケーションレイヤーにはその兆しもないようです。
もし今後ありえるとしたら、例えばAI/LLMエージェント間でのやり取りが発生するときはチャンスかもしれません。(AI/LLMエージェントについては次のスイッチングコストで触れます。)
例えば、こちらの例のように、例えばスマートホームを管理するエージェント"チーム"は、一つのエージェントではなく、温度湿度調整エージェント、調光エージェント、セキュリティエージェント、電力管理エージェント、エンターテイメントエージェント、これらをまとめるエージェント、と複数のエージェントからなるはず(Multi-agent system)で、そうすると同じユーザーの別機能のエージェント間でのネットワーク効果がでるかもしれません。 (エージェントが増えれば増えるほど他のエージェントの価値が増える。)
エージェントを介した、異なるユーザー間でのネットワーク効果もありえます。AさんがAIツール/エージェントを使っているとしてBさんのAIツール/エージェントが同じ企業のものであれば、より効果的に、早くインタラクションが取れるようになるかもしれません。
2/25に下記のようなAI同士が人間には認識できない"言語"で会話をするデモがTwitterでバズっていましたが、まさにこういうAIエージェント間で規格を合わせて、自然言語より早く効果的にやり取りするなんて未来がくるのかもと思いました。または、かつてのキャリア間のSMSのように、同じ会社のエージェント間なら安くできる(旅行予約とか)なんてことも出来てくるのかもしれません。
Today I was sent the following cool demo:
— Georgi Gerganov (@ggerganov) February 24, 2025
Two AI agents on a phone call realize they’re both AI and switch to a superior audio signal ggwave pic.twitter.com/TeewgxLEsP
エージェント間のネットワーク効果は、言語のやり取り以外でも起きえます。例えば、より多くのロボットが導入されたとき、同じ規格内であれば互いの物理的認識/信号を用いた認識ができる、などネットワーク効果が効いてくるシナリオも考えられます。(例: 同じメーカーのAIエージェントが自動運転モードであれば、加速/減速のタイミングを極限まで近づけて、超接近して運転できる)
ただ正直これらは確度が低い仮説で、2025年現在ではまだ期待しづらい状況にあります。(大体が想像したら面白い未来の話)
3. 囲い込み/スイッチングコスト (AIスタートアップへの重要性: 最重要)
スイッチングコストが高いとは、「様々なシステムと連携していたり、多くの関連アプリケーションを導入してしまっている結果、もう他のシステムに移行することができない」状態です。
現状
2022年以降、各モデル企業のAPIを元にサービスを展開しインターフェースを変えた”GPT wrapper”が無数に誕生しました。GPTのAPIを簡単に利用できるようにしたそれらのGPT wrapperのコンピタンスの実態はプロンプトエンジニアリングだったり、ちょっとしたインターフェースの使いやすさでした。
ところが、各モデル企業の進化のスピードは著しくモデルが良くなるたびに、それらの企業である必要性はなくなり売上が落ち込むケースも散見し始めました。GPT3を元にしてユニコーンに急成長したAIコピーライティングツールのJasperはGPTの改善により売上は停滞し、レイオフを行い、社内でのバリュエーションも下げたようです。
ただし、モデルの改善はむしろ、アプリケーションレイヤーにとってはいいニュースなはずです。さらにDeepSeek等の高性能のオープンウェイトのモデルの登場により、ユーザーへのスイッチングコストを高められているなら、よりよいモデル、より安いモデルに転換しつづけることができます。
Perplexityなどは、他社APIを使うという戦略を明言し、つい先日も素早くDeepSeek R1モデルを導入し、既存ユーザーを保ちながら、このモデルの高品質化、低コスト化の恩恵を受けようとしています。
OpenAIのSam Altmanも"Build a company that benefits from the model getting better and better."「モデルがどんどん進化すればするほど利益を得られる会社を作ったほうがいい」と言い、逆に言うと、今のモデルが出来ないことの小さな改善では次のモデルで駆逐されると言っています。
現状、スイッチングコストが高いと明言できるAIスタートアップはとても少ないです。
でも、GPT Wrapperであることは全く悪いことではありません。
ただし、どんどん次のモデルが良くなり、だからこそその次のモデルを使った新規参入者に負けず、更にはChatGPTなどモデル企業の直接のアプリケーションに負けないため、スイッチングコストを高めることがとても大事なのだと思います。
論点
GPT wrapperで終わらず、新しく更に優れたモデルが出たとしても、顧客が製品を使い続けるためには何が必要か
仮説: ワークフロー、AI/LLMエージェント(による行動範囲の拡大)、他社が持たないデータの獲得
ワークフロー
ワークフローはとてもよく言われるAI企業にとってのスイッチングコストの高め方です。現状多くのAIツールはその単独ツール内で作業が完結してしまい(e.g., 検索、書き起こし、要約)、他のいいツールが出たらスイッチしやすいものが多いです。
なぜワークフローに入り込むと高まるのか。以前のMoatの記事でスイッチングコストを高める項目を書きましたが、ワークフローに入り込むことで「製品の習熟度」が高まりと「他システムとの連携」が発生するからです。
ワークフローに入ると組織的にその製品を使うよう指示され、それに慣れ、変えるとなると社員の方からは嫌がられるでしょう(製品の習熟度)。社員の方が慣れれば慣れるほど、辞めづらくなる。
また、ワークフローに入ると、恐らくその作業の前後のシステムとの連携が発生する(e.g., CS関連のAIとCSツールとの連携、営業AIとCRMとの連携)。
ワークフローに導入されるのが難しいのはこのせいで、逆に導入がされづらいということは、スイッチングコストも高いということです。
AI/LLMエージェント
LLMエージェント/AIエージェントは、ワークフローとは更に異なり、更にAIが、"動的に"、"自律的に"、一定程度"汎用的に"機能します。下記の定義がわかりやすいと思います。
ワークフロー: LLM とツールが事前定義されたコードパスを通じて調整されるシステム
エージェント: LLM が自身のプロセスとツールの使用を"動的"に決定し、タスクの達成方法を制御するシステム
LLMエージェントは、Reasoning (推論) とActing(行動)を組み合わせ (ReAct)、さらに、ウェブなど外部環境にアクセスしながら、様々なツールを使い始めます。その結果、ワークフロー上での定義より更に汎用的に、定義されていないプロセスを、動的に自律的に行っていきます。
このように、LLMエージェントは、とても強力な一方で、ワークフローよりも汎用的で何でも自律的にできるため、その分導入企業にとってはリスクが大きいです。(プロセスが定義されているワークフローは、そこから外れることがない)
リスクが大きいということは、導入ハードルは高く、システム監査プロセスも当然長くなり、つまり一旦入ったなら、他の企業のエージェントに置き換えるスイッチングコストがとても高いことを意味します。
AI/LLMエージェントは、うちの業界はまだ早いかも、という思うかもしれません。ただし、AI/LLMエージェントはワークフローの延長 (より自律的、より汎用的、より動的)で、人間とワークフローの間くらいの存在。
ワークフローが入るなら、人間がやっているなら、AI/LLMエージェントに入る余地はありそうだと思います。
AI/LLMエージェントによるデータベース更新など行動範囲の拡大
さらに、昨今言われているAI/LLMエージェントの大きなトピックは、AI/LLMエージェントの"行動範囲"が拡大するということです。たとえば、「人間の従業員同様、AI/LLMエージェントがデータベースを"参照"するだけでなく、"更新"を行うようになる」ということです。
現在データベースの更新や重要なアクションに関しては、いくらAIツールを使っている会社でも最後は人間の承認を必要しているケースが多いと思います。(e.g., 顧客とのmtgとのサマリーはAIが作るが、CRMにいれるのは人間。 営業メールの下書きはAIが作るが、営業メールの送信。契約締結や送金手続きは人間。など)
でも将来はDBのアップデート、契約締結、送金、それらの重要タスクもAIエージェントが行う時代が来ると思われています。現時点で想像すると安全性で強烈な不安があります。ただ、Sam Altmanも「人間が地球上で最も賢い存在ではなくなるという転換期を迎えている」と発言している通り、人間がデータベースを更新するよりAIが更新したほうが正確な日が来るかもしれません。
そのハードルを超えるための仮説としては、二重三重の別のAIエージェントによるチェック、細やかなAIへの権限設定、インシデント発生時の即時対応、重複レコード/外れ値/不完全データのチェック/検証などが求められてくるのではと思います。(これは現状のわかりやすい仮説の一部ですが、投資先と議論する度に様々なアイデアが出てくる = 未知の領域です)
すでに長くなっていますが、まだ半分くらいです。
AI企業向けにオフィスアワー(壁打ち会)をやっていますので、AIスタートアップとしてどうMoatを築いていくべきか、僕と議論したい起業家の方はこちらのリンクからどうぞ!
最も重要なスイッチングコスト: AIスタートアップのデータ戦略
そして他社が入手しづらいデータの獲得、こそ最も重要なスイッチングコストの源泉というのが現状の仮説の一つです。ですので、この記事では多くをこのデータ戦略に割こうと思います。
これまでもデータがMoatになるかという議論は多くありました。僕は5年前にはデータは多いだけでは意味がないと考えていました。現在も基盤モデルのコモディティ化が続く中では、基盤モデルにおいてはデータ量は差別化にならないと思っています。
ただし、アプリケーションレイヤーにおいては、獲得するデータの種類を厳選し、データ獲得のROIの最適化を行えば十分Moatになると今は考えています。
データの分類とそれぞれのMoatの築きやすさ
簡単にデータを下記のように分類します。
1. ウェブ上や業界共通データベースで獲得可能なパブリックなデータ
2. すでにデジタル化されている各企業の中に閉じたプライベートなデータで、構造化がすでに行われているデータ
3. すでにデジタル化されている各企業の中に閉じたプライベートなデータだが、構造化が行われておらず加工が必要なデータ
4. 合成データ (Synthetic data)
5. これまでデジタル化されてこなかった情報 (紙で管理されている情報。アナログなのでデータではなく情報と表現することにします)
それぞれ、その獲得のしやすがが大きく異なります。獲得しづらければ獲得しづらいほど、それが参入障壁になります。
1のパブリックデータは誰でも取得可能。つまり、それによってMoatを作ることはかなり難しいかと思います。
2のプライベートだけど構造化されているデータ。これも顧客に供給してもらう難易度はあるものの、一旦ベンダーに供給されたならおそらく他のベンダーにも供給されるため、なかなかある会社のプライベートなデータにアクセスできたからと言って、なかなか競合優位性とは言えないかもしれません。
ただし、政府や機密性が極めて高い領域であれば、その機密性の高さから一社にだけ供給され、それがMoatになることがあるかもしれません。(PalantirはこれがMoatになっているはず)
3のプライベートだけど構造化されていないデータ、これは地味ですがとても効果的です。企業には大量のデータがあり、"幸いなことに"かなりクリーニングが必要だったり構造化が必要です。これは手間になり、つまりそれが参入障壁になります。元データが汚ければ汚いほど、面倒であれば面倒であるほど、一旦それをクレンジングできたなら参入障壁になると思っていいです。そしてこの作業はお金も取れます。ROI高く、勝手に参入障壁を築けるかもしれません。(そしてそれがさらにAIで簡単に行えるようになっています)
4の合成データは、パブリックなトレーニングデータが枯渇しつつある中で注目を集めてきました。USを始めかなり多くの合成データ提供企業が出てきていますが、日本ではまだあまり合成データを作成するプレイヤーが少ないように思えます。日本でもこのようなプレイヤーが出てくるのかどうか、注目です。
5の紙の情報のデジタル上へのデータ化は、日本ではスイッチングコストの源泉にできるチャンスが一番多いと思っています。
日本の企業は社歴が長く、また重要な取引の情報が紙で保存されたまま(逆に言うときちんと保管されている)の会社が多いです。
これをデジタル化することができたら、競合のAI企業にはアクセスできず、かつ価値も大きなデータのMoatになります。
CADDiはまさに紙の図面をデジタル化することで、強力な事業を築いてきました。下記の引用はCEOの加藤さんのnoteからです。
実際には過去の図面データというのはほとんど有効に利用されていない、という現実があります。つまり、「資産」だと思っている図面データのほとんどはアクセスされず、将来価値を生み出さないため、「資産」になっていないわけです。そもそも紙の図面もまだまだ大量にあります。それを保管するための物理的な保管庫を持っている会社も多々あります。そのため、まずは図面データをあらゆるタイミングであらゆる角度・部門・人からアクセスできるようにすることで、資産に変えることからスタートしました。そのためには、AIを用いて、図面に書かれているテキストデータの認識や意味の識別が必要です。
このような紙の情報をデジタルのデータに転換することで、経営資産となるのは製造業だけではないと思っています。
ただ何でもデジタル化すればいいわけではなく、どのデータにフォーカスすべきか、いくつか論点を書いていきたいと思います。
↓この加藤さんのnoteはデータを使った事業を行う日本のスタートアップ必読です。
意味あるデータと意味ないデータ
まず、何でもかんでもデータがあればいい、デジタル化すればいいというわけではありません。
データがどれほど豊富であっても、その利用が現実的なユースケースに結びつかなければ意味がありません。ただデータのQCDを高めるだけではなく、常にユースケースを意識しながらQCDの最適なレベルを判断していく必要があります。
データには本当に多種、多様なのものがあり、とりあえずデータを集めるのではなく、「何を改善/自動化したくて、そのためにはどのデータとどのデータを組み合わせて分析すれば解けるか」と、逆算してデータを取得しないといけません。それが意味のあるデータです。
これらのデータをいかに取得し、解析し、組み合わせるかが重要です。このコンビネーションは、データの種類が増えると指数関数的に増えていきます。例えば、CADデータとセンサーデータを組み合わせて設計と製造条件の相関を解析したり、ログデータと画像データを用いて品質管理と生産効率を同時に強化したりすることが可能
データで「見える化」は聞こえはいいものの、それが何らかの経営の改善にも自動化にもつながらないものも多いのが実態です。とりあえず見える化してダッシュボードで表示というのは「意味のあるデータ活用」とは言えない」かもしれません。
逓減していくデータの価値、上がり続けるデータのコスト
データは集めれば集めるほど、追加で得るデータの価値は逓減していきます。すでに類似のデータが大量に解析されているためです。
ITヘルプデスクへの問い合わせでも、カスタマーサポートでも、大体の問い合わせが頻度上位の問い合わせに固まり、 追加で何年分データを学習させたとしても、新しいデータはほとんどないかもしれません。したがって、データを獲得すればするほど、追加で獲得するデータの価値は逓減していきます。(下の図はカスタマーサービスのチャットボットへの送信内容の例)
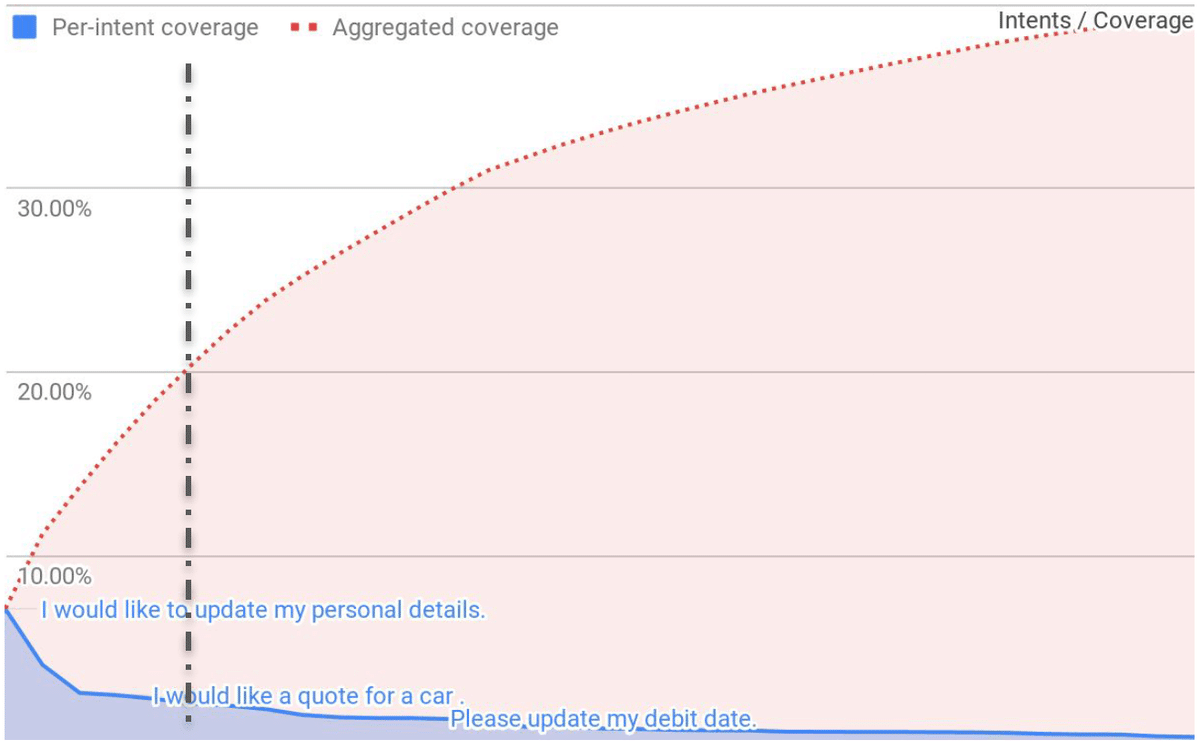
一方で、重箱の隅をつつくようなケースのデータは量も少なく出現確率も高くなく、そのデータに行き着くまでの必要なデータ数は上がります。追加で獲得するデータの中に、似たようなデータが増えていき、データ獲得のコストが高まって行きます。
データの網羅性がどれだけ大事になるか。ロングテールのデータの価値はどの程度あるか。すべてをモデルで解決せず人間の処理で行うことはできるか。この見極めが特に大事になるかと思います。
逓減するデータ獲得のROIの最大化
特化したデータによるスイッチングコストの最大化は可能だと思います。
ただし、すべてのデータを獲得することは不可能ないしは、ものすごく非効率的。したがって、資金、リソースが限られるAIスタートアップとしては、すべてのデータをいくらかけても獲得する、というよりは、そのROIを最大化するという思考が大切になります。
これ以降はそのROI最大化のための論点をいくつかまとめます。
精度の閾値、精度の飽和点
まず大切になるのは、どの程度のデータ量と精度があるとAIモデルが「最低限使える」ようになるか、という精度の閾値(threshold)。
また、どの程度のデータ量と精度を超えたら、そこからもたらされるAIの精度の違いが顧客の価値にほとんど影響を与えなくなるかという、精度の飽和点(saturation point)です。
AIモデルには、このレベルの精度ではないと全く使い物ならないという閾値が分野によって異なると思います。人の命を預かっているような領域、間違ったら後戻りできない領域 (ヘルスケア、金融、交通)などは、相当な精度がなければなりません。一方で、間違ってもやり直しが効く、間違ったリスクが少ない(描画)などは、多少精度が低くても使えるものになります。
また、同様にAIモデルの精度には、ある程度を超えたら顧客への価値がおなじになるもの。例えば、精度が90%にいってしまえば後は1%, 2%改善してもあまり顧客の満足度は変わらない領域と、精度が98%と99%、もっと言うと99.99%と99.999%で大きな差を生む領域(大規模なもの)もあります。そして精度は上がれば上がるほど、それ以上に改善することの難しさが増します。
そのようなモデルの精度の閾値 (ここまで行けば使える)、精度の飽和点(ここから先は同じ)を理解して、それに応じてデータを獲得しないといけません。
データの鮮度(動的なデータか静的なデータか)
過去のデータがどの程度モデル上で意味を持つか。持つとしたらどれくらい前のデータであれば関連度が高いか、これもデータ獲得では重要な観点です。
例えば何年も業務プロセスが変わらない業界では、10年前のデータも今の業務プロセスには意味があるかもしれません。ただ、B2Cなど動きが早い業界において、10年前のユーザーデータはほとんど意味がないかもしれない。
事業を行う業界にとって、何年前のデータからが意味のあるデータで、どれだけ最新のデータを取り続ける必要があるか。これも大事な観点です。
データが静的で古いデータでも問題がなく最新のデータの価値が低いなら、一度築いたデータの優位性は保ちやすい、一方でデータが動的で最新のデータでないと価値が少ないならデータを持つ企業の優位性は崩れやすい。
つまり、動的なデータが多い業界なら新規参入によるデータ獲得もチャンスがあるかもしれません。一方で、古いデータに価値があるなら、もしそのデータをすでに大量獲得している企業があるなら、なかなか新規参入者のデータ獲得によるキャッチアップは難しいということを意味します。
必要となるデータの品質
次に、プロダクトの価値のために、どれだけの品質のデータが必要になるかも大事な観点です。加工がどの程度必要になるか、品質管理がどの程度必要になるか。データ品質はデータ獲得のコストの重要なパラメーターです。
先程のデータの鮮度と品質についての加藤さんのnoteをここでも引用
データの鮮度や正確性など、品質に関わる部分で必要十分なコントロールが必要です。それは、製造業のプロセスにおいて、データの鮮度や正確性が低下すると、最終製品の品質にも影響を与えうります。例えば、古いデータを基に盲目的に判断をしてしまうと、その情報の品質が悪いが故に製造ラインの停止や不良品の発生につながることがあるわけです。そのため、データをただ保持・解析するだけではなく、その価値をタイミング・ユースケースに応じて適時判断していかなければいけません
データの全体量とコストカーブ。データの価値のカーブ
そして、以上のようなものを考えながら、データの獲得コストはどのように増加していくか。データの価値はどのように逓減していくかを考える必要があります。
データのコストカーブは、データの全体像と量がどの程度か、どういう風なデータの獲得方法があるかが重要になります。
データの価値に関しては、データを何に活用するか、活用するための精度の閾値/飽和点が重要な論点になります。
正確にわかることは不可能だと思いますが、それぞれの業界では違うデータコストカーブと価値のカーブを描きます。それを考えながら最適なROIを考えていかないといけないかと思います。
ドメイン知識
まとめると以下のような論点を整理しながら、最適なデータ獲得戦略を考えていくべきかと思います。
- どのデータが、取りたいアクションに対して意味のあるデータか
- どこまでデータを取れば、AIモデルとして使用可能になるか
- どこまでデータを取ると、それ以上の価値が変わらなくなるか
- どれだけ新しいデータを獲得するべきか
- どれだけの品質のデータが必要になるか
- どの程度のデータの加工が必要になるか
- データ全体量はどの程度か
- データ獲得方法にはどのようなものがあるか
以上の論点から、最適なデータ獲得戦略を考えていくためには、その業界の深い深いドメイン知識が必要になります。
その業界、領域のデータの全体像と獲得方法を熟知し、データの活用方法と精度について熟知し、データの品質や加工方法について熟知している。
ただ闇雲にデータを集めて「見える化」するのではなく、意味のあるデータと意味のないデータを見極め、どう組み合わせば使えるようになるか計画できている。
これこそが↓で加藤さんも言う通り、AIスタートアップのデータ戦略には重要になるのではないかと思います。
更に、実際に開発を進めるにあたり、特に我々のようなVertical Softwareのプレイヤーでは、社内でのドメインの専門性が非常に重要になります。テクノロジーの力はものすごく重要です。一方で、いくらテクノロジーが強くてもそれだけでは成立しえない、逆に言えばピュアなソフトウェアプレイヤーがこの領域で活躍するのは困難です。その中で、キャディはソフトウェアプレイヤーの中では世界で類を見ないレベルでドメインナレッジが高いと自負しています。
データ戦略まとめ
AIスタートアップの現時点での最重要Moatであるスイッチングコストですが、データ獲得が入口、そのプロセスのAIエージェント、そしてそのアウトプットを組み込む出口のワークフロー、どれもとても大事です。
資金のない日本のスタートアップとしては、“データもフォーカス”した方がいいでしょう。幅広くすると汎用型の新型のモデルに駆逐される可能性が高いです。狭く、獲得が難しく、精度の価値が最も高データにフォーカスし、ROIを最大化する。AI戦略 = “どのデータをどう学習し、どう使い、どう再度ためて学習につなげるか”と言っていいくらい重要なのがデータです。
まだまだ黎明期の2025年2月26日の今日現在Grok 3, Claude 3.7など続々と登場しており、まだまだ性能の向上は続き、2年後にこの記事を読んだらきっと笑えるくらい違う世界になってるかもしれません。
というわけで、長くなったので、AIスタートアップのMoatの続編、第一想起などは別記事にします。(来週再来週くらいに出します)
AI企業向けにオフィスアワー(壁打ち会)をやっていますので、ご興味ある方はどうぞ!僕のTwitterアカウントはこちらです。