
機械学習のリーケージについて考える

こんにちは、西岡 (@ken_nishi) です
今回は、機械学習だけでなくデータを扱うときに大きな問題一つとなっているリーケージについてお話します。
リーケージに関しては、「Leakage in data mining: Formulation, detection, and avoidance」(Kaufman, Shachar, et al., " ACM Transactions on Knowledge Discovery from Data (TKDD) 6.4 (2012): 1-21.)の内容を元に、過去にリーケージが発生した事例とリーケージの対策を紹介します。
高い精度の機械学習のモデルが作成できたと思ったら、リーケージが発生していて、実データに対して全く使えないモデルだったということがないようにしっかりとリーケージを理解していきましょう。
予測精度の高いモデルを疑うところから始める

リーケージの話に入る前に、機械学習を実施するときの重要な経験則の一つを紹介します。
それは、「予測精度の高いモデルは、意図せず使えないモデルを作成している可能性がある」ということです。
予測精度が高いモデルに関しては、過去にも記事を書いているのでそちらも参照してください。
学習時には高性能だったが、リーケージやオーバーフィッティングなどが起きており、現実的には使えないモデルを意図せず作ってしまうことはよくある話です。
もちろん、事前にそのようなモデルを作ることを避けるに越したことはないです。
しかし、完璧に使えないモデルとなることを防止することは、現実的に難しいので、使えないモデルを作ってしまったときにいち早く気づき対処できるようにすることが大事です。
本当に難しいリーケージ防止

リーケージとは、本来得られるはずのないデータをモデルの学習時に使用してしまうことを言います。リーケージが発生することを「リークする」とも言います。
例えるなら、学校で受ける期末テストのときに、カンニングをしていい点数を取るようなイメージです。カンニングでは、本来自分が持つ実力をかさ増しして見せることができます。
機械学習のモデルが持つ本来の性能をかさ増ししても意味がないので、自分はそんなことをしないと思う人も多いと思います。
もちろん、その通りで、"わざと"モデルの性能を不正に高める人は少ないと思います。
問題なのは、"意図せず"モデルの性能を不正に高くしてしまっていることが多々あるということです。
ここで、 Leakage in data mining: Formulation, detection, and avoidance で紹介されているリーケージの事例5つを紹介します。
1. KDD Cup 2007: Netflixの映画評価履歴データを用いた予測
KDD Cupは有名な機械学習のでコンペです。
2007年のコンペでは1998~2005年のデータを用いて「2006年の映画に対して各ユーザーが評価をするかどうかを予測」と「2006年の映画に集まるレビューの数を予測」の2つのタスクが出されていました。2つのタスクではそれぞれ違う映画のデータになっていました。
しかし、2つめのタスクの優勝者のモデルは、1つめのタスクのテストデータ、つまり2006年のデータをモデルを作成したものでした。
含まれる映画が異なっていても、2つのタスクには依存関係があったということです。
そもそも2006年のデータを予測するのに、2006年のデータを利用することは、実際のサービスでは使えない非現実的な予測となってしまいます。
2. KDD Cup 2008: 胸部X線データから乳がん検出
このコンペで出されたデータでは、本来は無関係であるはずの乳がんと患者IDに相関が見つかりました。
患者IDが検査機関や機器によって作成されていることが原因でした。
乳がんであるかどうかが、患者IDという形に変換されてリーケージとなった例です。
3. INFORMS Data Mining Challenge 2008: 診療履歴を用いた肺炎の診断
このコンペでも、肺炎であるかどうかの目的変数が特徴量として含まれてしまっていました。
リーケージが発見されてから、それらの特徴量を取り除いたのですが、欠損値となった部分が推測可能になっており、完全にリーケージを取り除くことはできなかったようです。
リーケージを欠損値にすること自体が意味を持ってしまうことがあるということです。
4. INFORMS Data Mining Challenge 2010: 株価変動予測
このコンペでは、銘柄を非公開にしたり、テストデータに予測可能な変数を入れないなど、過去のコンペで起こったリーケージの事例に当てはまらない最低限の対策はしていました。
しかし、yahooやgoogleの株価情報データを元に銘柄をある程度特定できてしまい、約30チームがAUC 0.9以上を達成してしまいました。
5. IJCNN 2011 Social Network Challenge: ソーシャルネットワーク上の繋がりを予測
匿名化された約700万のエッジを持つグラフ構造から、ネットワークをよく表現する残りの9000のエッジを特定するタスクです。
これも匿名化されていた元のデータがFlickrであることが特定され、6割以上のエッジが予測されてしまいました。
どの例も、現実の世界のサービスで使用するときに、全く使えないモデルが作成されています。
有名なコンペですらこの状況です。リーケージを防ぐことがいかに難しいことがわかるかと思います。
理想的なリーケージ対策

Leakage in data mining: Formulation, detection, and avoidance では、リーケージを発生させないデータセットの作り方として以下の2つの条件を提案しています。
① 説明変数は、目的変数より前に観測される
② 学習用の目的変数は、テスト用の目的変数よりも前に観測される
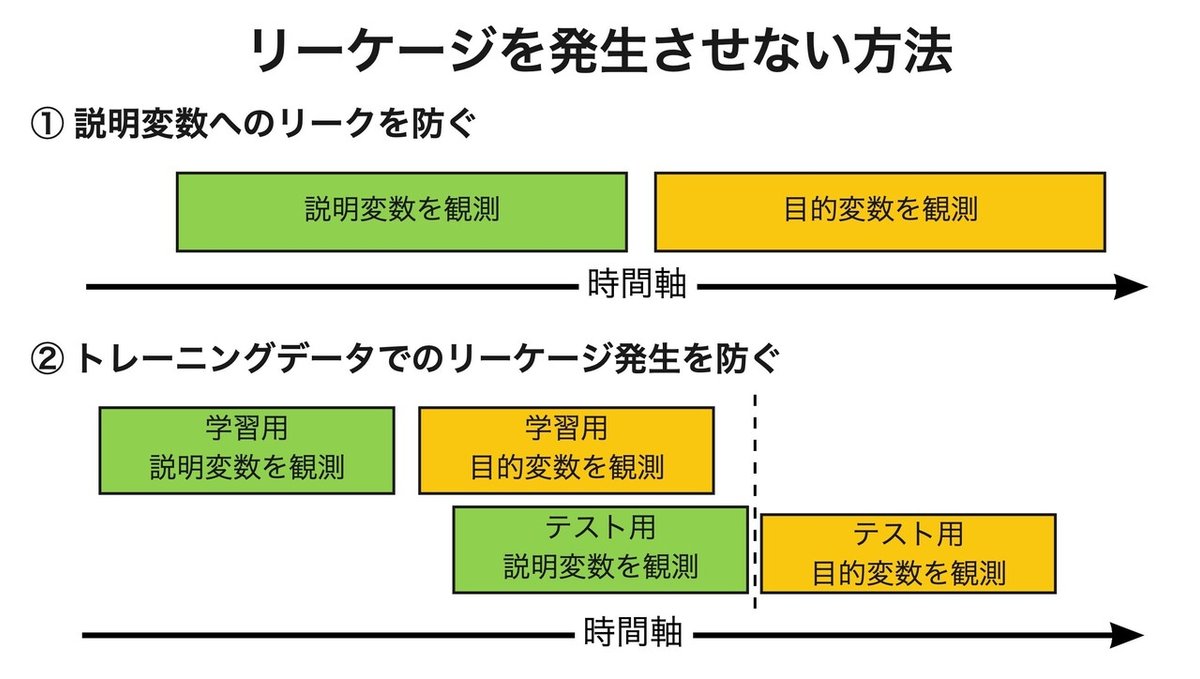
このように時系列情報を利用してデータを適切に分割することで、リーケージが発生しないようにできます。
時系列情報によるデータ分割をするために、どのデータがいつ生成されたかを記録しておく必要があるということです。
現実的なリーケージ対策

論文で提案されている時系列情報によりデータを仕分けができれば、理論上リーケージ対策はできそうです。
しかし、実際の全てのデータに生成される時刻を付与することは現実的ではないです。
そこで、論文でも述べられていることですが、時系列情報が使えないときに重要となるのが、「探索的データ解析 (EDA: Exploratory Data Analysis)」となってきます。
機械学習のアルゴリズムばかりに意識が奪われて、探索的データ解析を後回しにする人をよく見ます。
しかし、探索的データ解析をせず、データを理解しない状態で機械学習に取り掛かると、多くの場合、間違った結論を導き出してしまいます。
機械学習においても、まずは探索的データ解析で「データを知ること」が重要であると断言できます。
そして、探索的データ解析にて驚くような発見があったとき、それがリーケージとなりうるのではないかを慎重に検討しなければなりません。
もちろん、驚く発見が本当に新しい知見となるときもあります。
そのような発見ができることも探索的データ解析の醍醐味なので、楽しんで探索的データ解析をやっていきましょう。
学習データもテストデータも過去のもの

機械学習で扱うデータについて意識しておきたいこととしては、一般に、機械学習に使う「学習データ」も「テストデータ」も過去のものであるということです。言い換えると、すでに確定した情報を使っているということです。
本当であれば、予測モデルが確定した時点の情報でモデルを作成し、新しいデータに対して予測を実施し、アルゴリズムを検証するのが理想です。
しかし、良い予測モデルを決めるには、アルゴリズムの比較やパラメータの調整など数多くの実験をする必要があります。
そのため、実際に運用しているサービスなどでそのような実験をすることが難しいので、すでに存在するデータ、つまり確定した情報を使ってモデルの最適化をするのが一般的です。
確定した情報を使っているから、そのデータ内で予測モデルを構築するときに、どこまでの情報を使って、どこから隠すべきかの区別がしにくくなっているということです。
最後に
リーケージは一筋縄では解決できないものです。
学習データもテストデータも全てが過去のデータであることを理解し、機械学習で使うデータに触れてることが、リーケージを防ぐための第一歩だと思います。
そして、過去のデータで最適化するだけでなく、未来のデータで継続的な検証を繰り返すことが、本当の意味での機械学習の活用に繋げるために重要です。