
Python初心者 無料で学習を極める(9)

「機械学習のためのpython入門講座」SkillupAI様の8日目の講座から学んだことを記載していきます☆最終回です!
本記事は、「あ!どんなふうにあれ使うっけ?」っと言うときに参考にしてもらえると嬉しいです。一通りpythonに慣れてきたら、実際のプログラムを載せるなどして皆さんと一緒にレベルアップができればと思います!
それでは8日目行ってみましょう!
day8:機械学習モデルの構築と評価
scikit-learnについて
python用のオープンソース機械学習ライブラリ
ここ数年では、このライブラリにほとんどが入っている状態。うまく活用方法を学んでいきたいですね!一緒に頑張りましょう☆
機械学習の概要
教師なし学習 と 教師あり学習 に分ける事ができる
教師なし学習
データのみを与えて、データの中の傾向をコンピュータに発見させる
明確な答えが出力されない状態
例:同じ形の何か。 と言った感じで、何か が分からない状態での分析
例:主成分分析などが該当
教師あり学習
データとそれに対応する理想の出力(=教師)を与えて、コンピュータには理解させる
※アノテーション:教師データを作成する作業のこと
ステップ1:学習フェーズ
出力と入力の関係性の習得を実施し、モデルを作成する
ステップ2:運用フェーズ
入力(未知データ)に対して、モデルを活用し精度よく予測する
機械学習方法:決定木
条件分岐を学習する手法であり、
持っているデータに対してどの様な条件で どの様に分かれるのか。 を学習する方法
下図の様に、上の条件:色の観点、下の条件:大きさの観点
この様に設定する条件を選定することで、よい分割方法を得る事ができる

機械学習方法:アンサンブル学習
予測精度が比較的低い分類器(弱学習器)を複数作成し、予測結果を多数決で決める
特徴として、予測性能の高い分類器を作成できる可能性があり、特に過学習を防ぐのに有効
イメージ:相撲の試合で協議が発生した時に、複数人が集まって判断を下します。あの時の様に、複数人で判断を下す方が客観性が高い と言った観点を活用する
学習データの分割
学習データを分割する際には、学習用データと未知のデータに分ける必要があります。
その為、今回、タイタニック号の乗客に対して、「生存率」を予測する ことを目的としましょう。その場合、
学習データ:生死情報有、それ以外のデータ
未知データ:生死情報無、それ以外のデータ
という組合合わせになります。上記に記載した、教師信号あり学習の意味と一致しますね。
データ分割の関数:train_test_split( )
未知のデータを、テストデータから抽出することを意味する
# 訓練データとテストデータの分割を行うライブラリをimport
from sklearn.model_selection import train_test_split
#tr_train,tr_testに振り分けられるデータはランダムに決まる
# random_state = 1234 は振り分け方を固定するための値
# 他のデータ分割と同じにならない様に割り振りを考えること
tr_train,tr_test=train_test_split(train, test_size=0.3, random_state = 1234)
モデルの構築
①決定木モデル
作成、学習、予測、精度確認のプロセスを実施する。
# sklearnの決定木をimport
from sklearn import tree
# 決定木分類器による空の分類器を生成
model=tree.DecisionTreeClassifier()
# 訓練用の説明変数,目的変数を与えて学習させる
model.fit(tr_train_X,tr_train_Y)
# 生成されたモデルを用いて、テスト用の説明変数に対する予測値を入手
predict= model.predict(tr_test_X)
from sklearn import metrics
# 精度をmax 1.0で返すmatrics.accuracy_scoreを利用
# 引数にモデルにより予測された値と、実際の目的変数を与えることで正解率を計算
print('判別率:',metrics.accuracy_score(predict, tr_test_Y))
②アンサンブル学習モデル
先程の決定木の生成のコードと同じ内容を記載することで実現できます
# sklearnのアンサンブル学習系ライブラリから、ランダムフォレスト分類器をimport
from sklearn.ensemble import RandomForestClassifier
# 空のモデルを生成
# 決定木の数をn_estimatorsで指定
model=RandomForestClassifier(n_estimators=300)
# 訓練用の説明変数,応答変数を与えて学習させる
model.fit(tr_train_X,tr_train_Y)
# 生成されたモデルを用いて、テスト用の説明変数に対する予測値を入手
predict= model.predict(tr_test_X)
from sklearn import metrics
# 判別率を表示
# 予測結果と実際の目的変数を引数にすることで、判別率を計算
print('判別率:',metrics.accuracy_score(predict, tr_test_Y))
ここで、なんと!機械学習の結果値(生存率)が出てきましたね!
8日目にして、ここまで出来る事ができました~~。感動ですね☆

モデルの検証
予測したが、実はまだまだこれからが楽しい所です!
①分類性能を精密に評価すること
②性能を上げること
を目的にアクションを行っていきます。
①に対しては、「他のデータはどうか」、②に対しては、「調整を行うことで良くならないか」など を考えることができます。
①モデルの検証:データの分割の工夫
データ分割を複数実施し、どこの部分にテストデータに用いることで、精度が上がるのか。と言った考えができます。
※会社の分析メンバーはこの方法を実施していませんでした。その理由を確認すると、「一連の流れの急なポイントのみを抽出した場合、時間軸での変動の傾向に対して説明ができない(説明性が低い)。その為、変なところのみを抽出としたことはしない方がいいかなー」との事でした。扱うデータによって注意が必要ですね。
①-1:ホールドアウト検証
・今まで勉強をしていた分割方法
・過学習(一部のデータに対してのみ成績が良い)を検知できない
①ー2:k-分割交差検証
・すべての訓練データにテストを受けさせる
・過学習を検知できる
# KFold交差検証のライブラリ、交差検証のスコアを求めるライブラリ、および交差検証による予測に関するライブラリをimport
from sklearn.model_selection import KFold, cross_val_score
# 分割数n_splits, ランダム性の固定を行うrandom_state, データのシャッフルを行うかを指定するshuffleを引数に与える
kf=KFold(n_splits=5, random_state=30, shuffle=True)
# 説明変数として、trainのコラムが1以降のものを設定
x=train[train.columns[1:]]
# 目的変数として、trainの"Survived"を設定
y=train["Survived"]
# クロスバリデーションで得られるスコアを代入
# 予測に使うモデル、説明変数、目的変数、および作成したKFoldのパラメータを引数に与える
cv_result = cross_val_score(model, x, y, cv = kf)
print("cv: {}".format(cv_result))
# 分割数の分だけ精度が得られるので、平均値をとれば全体の精度が確認可能
print("平均精度:{}".format(cv_result.mean()))
②モデルの検証:ハイパーパラメータチューニング
ハイパーパラメータは、モデルが持つパラメータの事です。
チューニング=最適化 を意味します。
チューニング手法:
②ー1:グリッドサーチ
それ以外:ランダムサーチ、ベイズ最適化 など
※注意!複数のパラメータの調整は時間とマシンパワーが必要となる
②ー1:グリットリサーチ
範囲を決めてパラメータを網羅的に探索する手法
from sklearn.model_selection import GridSearchCV
# サーチしたいハイパーパラメータ、および探る範囲の指定
# 今回は、予測子の数を100~1000まで、100刻みで探る
param={'n_estimators':range(100,1000,100)}
# 分類器はランダムフォレストを指定
# cvに与えた数値分だけ、交差検証を行う
GS_rf=GridSearchCV(estimator=RandomForestClassifier(random_state=0),param_grid=param,verbose=True,cv=5)
GS_rf.fit(x,y)
print("ベストスコア:{}".format(GS_rf.best_score_))
print("最適なパラメータ:{}".format(GS_rf.best_estimator_))
ここで得られたパラメータに合わせて、分類結果を提出する形式に変更します。
# グリッドサーチで得られたベストなモデルを用いて分類を行う
model = GS_rf.best_estimator_
# 学習
model.fit(train[train.columns[1:]] ,train[train.columns[0]])
# テストデータに対する予測
test_prediction = model.predict(test)
これで、グリットリサーチで見つけられたパラメータの最適な分割タイミングを用いてテストデータを評価できたことになります。
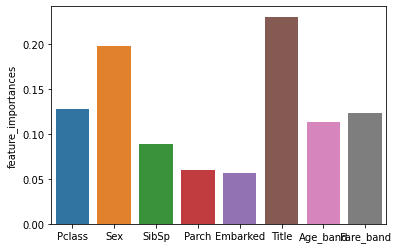
予測にあたり各項目の効果確認
ここまでの間で、学習を行うことができ、改善する事もできました。しかし、分析屋としては、説明を行う必要があります。
そこで、説明変数に対する貢献度合いを下記の内容で確認します。
# 分類に用いた説明変数について、それぞれが分類に貢献した度合いをfeature_importances_で取得できる
feature_importances= pd.DataFrame({"feature_importances":model.feature_importances_})
sns.barplot(tr_train_X.columns, feature_importances["feature_importances"])
plt.show()
ここで、下記の結果を得る事ができ、作成した「Title」の効果が高い事が分かりました。
以上です!!!!!!!!!
初歩的なステップから、最後は機械学習の一部を学ぶことができましたね!
お疲れ様でしたーーーー。
すごい内容が濃ゆかった為、一つの記事にまとめておきますね。
ありがとうございました~~
いいなと思ったら応援しよう!
