
AIを使って新しいダンス表現を引き出す [YCAM Dance Crew 2024]

今回の展示について
2024年6月29日(土)から11月10日(日)にかけて山口情報芸術センター(YCAM)で開催された「YCAM Dance Crew 2024」展において、QosmoがAIシステムとインタラクション技術に関するエンジニアリングを担当しました! こちらの作品はAI(StreamDiffusion, ChatGPTなど)の活用を通じて、ダンサーが新しい振り付けや動きを発見・習得する機会を提供することを目的とするインタラクティブなインスタレーションとなっています。つまり、ダンサーがいつもの動きや振り付けのパターンから抜け出し、AIとのやりとりを通じて自然に新しい動きや表現に挑戦できるようにすることを目指しています。 また、ダンサーだけでなく、子どもやダンス初心者など、幅広い人々が楽しく体を動かし、ダンスを身近に感じられるような仕組みにもなっています! また、こちらの作品は2024年11月9日から11日にて名古屋の光の広場にて開催された「YCAM Dance Crew in 光の広場」にも展示されました。
制作に至るまで
今回のプロジェクトでは、誰でももっと楽しくダンスができること、そしてAIを活用して、自分では思いつかなかった振り付けや動きを引き出すことの2つが大きなコンセプトになっていました。
ダンスにはさまざまな技やレベルがありますが、楽器と違って、特別な知識がなくても誰でもすぐに体を動かして自己表現できるのが魅力のひとつだと思います。年齢に関係なく、「どう踊るか?次はどんな動きをするか?」と考える創造性は、子どもから大人までみんなが持っているものですよね。このプロジェクトでも、「自分のいつもの動きを超えて、新しい動きをどう生み出せるか?」というテーマについて、制作メンバーでたくさん議論しました。技術的なハードルが高く、実装には至りませんでしたが、ダンスの最中にリアルタイムで動きを学習し、少し異なる動きを提案するというアイデアも出ました。AIを自分の動きを映し出す「鏡」のように使いながらも、自分の予測をちょっと外れるような意外性を持たせることで、新しい振り付けや動きを誘発できないか?そんなことを考えながら、このプロジェクトに取り組んでいました。
体験の流れ
体験の様子は、以下の動画でご覧いただけます。
この展示では、AI生成による2つのモード を体験できます。
1「Dance with AI」モード
参加者の姿がリアルタイムでモニターに映し出され、その上にAIが生成したエフェクトが重なることで、視覚的なインタラクション を楽しめます。
2「Dance as AIシルエット」モード
参加者の姿そのものが画像生成AIによって変換 され、プロンプトに沿った新しいビジュアルが生成されます。どのように映像を変換して欲しいかという命令である、プロンプト入力に関しては、声を使って入力する方法とテキストを入力する方法が存在します。また、「1からプロンプトを考えるのは難しい…」と感じる人のために、選択肢として提示される単語を組み合わせて、LLM(大規模言語モデル)が文章を作成する仕組み も用意しました。これにより、誰でも簡単にAIを活用した創作体験ができるようになっています。
体験者向けのお土産コンテンツも!
さらに、本展示では体験者に向けた特別なコンテンツ も用意されています。 体験中にリアルタイムで生成された映像とは別に、録画された動画データを使用し、より高品質な変換処理を行った映像 を提供。体験後には、QRコードからダウンロード できる仕組みになっています。
テクノロジー
今回、メインツールとしてはTouchDesignerを使用し、画像生成モデルとしてはStreamDiffuisonを使用しました。Stream DiffusionはStable Diffusionのような拡散モデルをリアルタイム処理に適応させた技術になります。
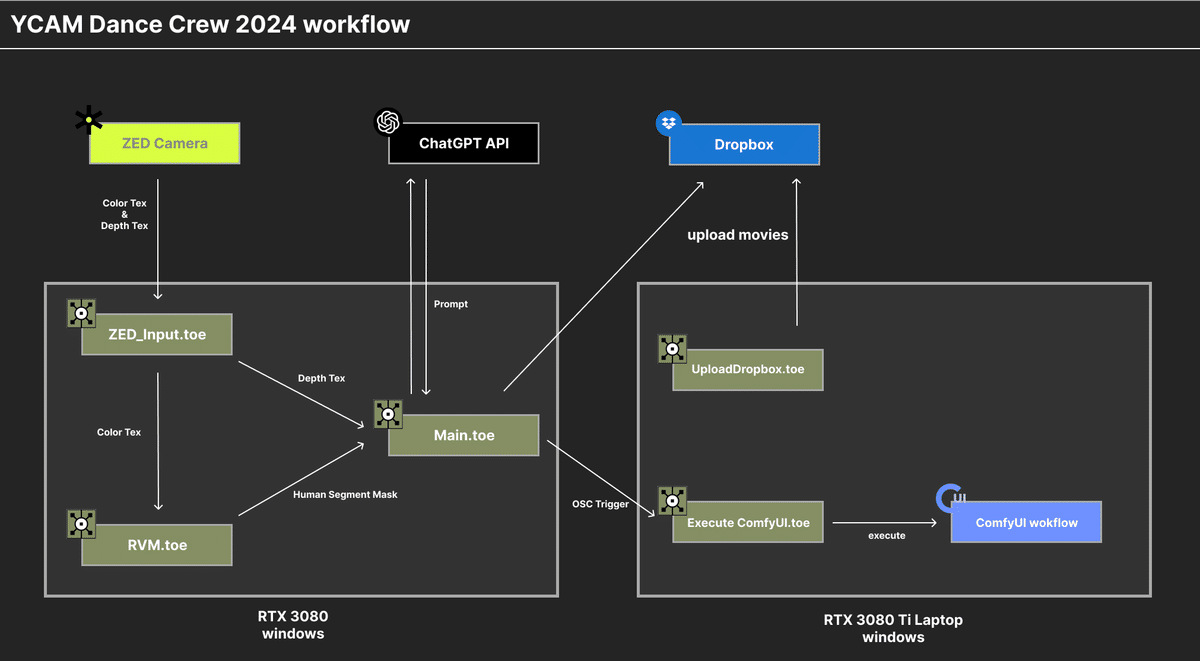
⚪︎ハードウェア
今回のシステムではPCが2台(RTX3080搭載デスクトップ・RTX3080ti搭載 ゲーミングノード)存在し、RTX3080のデスクトップではリアルタイムでの画像生成AIによる変換やユーザインタラクションに関する処理が行われ、ゲーミングノートはお土産コンテンツ用の高品質な動画生成を随時行うレンダリングサーバとして使用しました。
カメラに関しては、Stereolabs社のZED 2iを使用しました。TouchDesignerではZEDに対するノードがいくつか用意されており、RGB情報だけではなく簡単にBodyTrackingやDepth情報を取得することが可能です。
⚪︎TouchDesigner
TouchDesignerでは基本的に1つのプロジェクトファイルで実行されるシステムは1つのプロセスで実行されます。そのためカメラの取り回し、カメラからの画像に対する解析、画像生成などを同時に1つのプロジェクトファイルで行うとパフォーマンスが大きく落ちてしまうことがあるため、大きな処理ごとにプロジェクトファイルを分け上記の画像のような構成になりました。
エフェクト・画像生成動画生成においては、複数のエフェクトモードを用意しました。これらのエフェクトは、体験者が選択する曲や、曲の進行中にも変化するような仕組みになっています。
Noise + Feedback
入力としてRGB情報をそのままStream Diffusionに渡すのではなく、人物検出を行った後、ノイズを適用したテクスチャをStream Diffusionの入力として使用しています。
また、Stream Diffusionには入力画像の構造をどの程度参照するか(入力形状をどれだけ保持するか)を調整するためのパラメータが含まれています。このパラメータ設定により、適用するノイズのパターンやその細かさが最終的な出力のディテールに大きな影響を与える仕組みになっています。
本番環境ではおおよそ30fpsで動作しましたが、わずかにラグが感じられる場合がありました。この問題に対処するため、フィードバックエフェクトを導入し、視覚的なスムーズさを向上させることでラグの体感を軽減しました。
Prompt Mixing
このエフェクトは、2つのプロンプトの内容を補完する形で生成される仕組みになっています。例えば、マテリアルや質感の補完は通常のCGソフトでも可能ですが、ゼリーと岩のようにまったく異なる性質のコンテンツや、抽象的な概念をつなぎ合わせるような表現は、AIならではの独創的なアプローチです。
Optical Flow
動きの方向と大きさを解析する手法であるOptical Flowによって得られたマップをStream Diffusionの入力として使用しています。そして、一定の閾値を超える大きな動きの部分だけをStream Diffusionで変換対象とする仕組みを採用しています。この工夫により、体験者が自然とより大きな動きをするよう促し、よりダイナミックな体験を楽しめるようになっています。
Edge x Feedback
人に対するエッジ検出を行いそのエッジに対してフィードバック処理を行ったテクスチャをStreamDiffusionの入力として扱いました。こちらのエフェクトは主に体験者が自分の姿を見ながら踊れるDance with AIモード向けとして使用しました。
AR
これまでのエフェクトとは少し異なるアプローチとして、ARエフェクトも実装しました。今回使用したZEDカメラは深度情報を取得できるため、その特性を活かし、TouchDesigner内にZEDカメラを模倣した仮想カメラを配置しました。この仮想カメラを使用して、AR用のジオメトリをレンダリングし、生成された結果をStream Diffusionの入力として利用しています。
プロンプト生成
プロンプトの生成に関しては声による音声入力、キーボードによる直接入力、1からプロンプトを考えるのは難しいと感じる参加者のために、選択肢として提示される単語を組み合わせ、LLMによって文章を生成するモードを実装しました。この仕組みにより、誰でも簡単にプロンプトを作成でき、AIを活用した創作体験へのハードルを下げることに目指しました。さらに、提案される単語の中には、一見全く関係のないものが含まれる場合もあり、あえてそれらの単語を選択することで、通常では思いつかないような意外性のある文章が生成される点も面白いポイントとなっています。


⚪︎ComfyUI
ComfyUIは、Stable Diffusionなどの画像生成AIを操作するためのノードベースのGUIツールです。今回は動画生成のために、AnimateDiff LCMを使用しました。メインのStreamDiffusionではリアルタイム生成が可能ですが、品質が若干低下する場合があります。一方で、このワークフローでは生成に時間をかけることで、より高品質な動画を生成することができます。生成された動画はお土産コンテンツとして、QRコードを通じて後日ダウンロードできる仕様になっています。体験中に録画された生のダンス動画はComfyUIサーバーへ送信され、AIによって領域ごとに処理されます。具体的には、人物、背景、上半分、下半分といった領域に分割され、それぞれに異なるスタイルが適用されます。このスタイル指定にはテキストプロンプトを使用せず、代わりにip-adapterという技術を活用しています。これにより、指定したスタイル画像を入力として、各領域に応じた動画生成を行います。


さいごに
この展示では、AIを活用することで、思いがけない発見や新しい体験が生まれる仕組み を取り入れました。予想外のプロンプトから生まれる意外な変換結果に驚いたり、その結果が従来のダンスの枠を超えて新しい動きを引き出したりする可能性もあります。自分では思いつかなかったアイデアが形になることで、新しい視点が得られたり、創造性が刺激されたりする楽しさ を感じられる内容になっています。 また、開発中に実際に体験してみて気づいたこと もありました。たとえば、「岩」や「鉄」などの硬い素材がプロンプトとして入力され、それに合わせて自分の身体が硬い質感に変換されると、自然とカクカクした動きをしたくなりますし、逆に「糸」や「ジェル」など柔らかい素材に変換されると、うねるような動きをしたくなりました。このように、AIによって見た目が変換され、それを自分で認識し、その結果を受けて動きを変える、そしてまたAIがその新しい動きを変換する、そんなループが生まれるのが、とても新鮮で面白い体験でした。 さらに、変換結果に合った動きをするのはもちろん、あえて全く違う動きをしてみるなどのルールを取り入れると、瞬間ごとに新しい動きの連鎖が生まれるかもしれませんね。 今回の展示では、リアルタイム性を確保するために品質とのトレードオフや、使用できるAIモデルの制限 もありました。今後は、こうした部分をさらに改善し、次の機会により良い体験を提供できるようにしていきたいと思います。

クレジット
ヘッダー写真撮影:田邊アツシ
ヘッダー写真提供:山口情報芸術センター[YCAM]
Photo by Atsushi Tanabe
Courtesy of Yamaguchi Center for Arts and Media [YCAM]