
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models
マルチモーダルなニューラル言語モデルを用いた
視覚-意味的埋め込みの統合
著者 Ryan Kiros, et al.
Abstract
LSTMを文章をエンコードするために用いたところ, 物体検知なしでSotAに匹敵した。(データセット: Flickr8K, Flickr30K)
1.Introduction
画像認識/検知はブレークスルーが起きた ⇔キャプション生成はここから。
もし理想的なキャプションが生成されれば、(1)画像内容検索システムの可能性も向上し、(2)原理的には画像への質問にも答えられるだろう。
エンコーダーに対しては、画像-文章の分散表現の結合を学習させる。
画像とそのキャプションにランク付けするA pairwise ranking 損失関数
デコーダーには、SC-NLMを導入。文の構造と文の内容をほどいてくれる。
(disentangle と言う表現はどうやらパワーワードっぽい)
①エンコーダーは画像とキャプションにランク付けする。
②デコーダーはゼロから新しいキャプションを生成する。
画像-テキスト埋め込みモデル と マルチモーダルニューラル言語モデル を統合。
マルチモーダルベクトル空間の特性を分析。
言語規則性はマルチモーダル空間にも適用されることを示す.
PCA projections?🤔 = 主成分分析
pairwise ranking methodsに似てる。
1.1 Multimodal representation learning
画像-単語埋め込み結合の学習 / 画像と文章の共通空間への埋め込み
我々の提案するパイプラインは↑をもろに使ってる。
構造的な観点から言うと我々のEncoder-Decoderモデルは[20]に似てる.
ちなみに[20]は2段階埋め込みと意味解析のための生成手順を提案した。
1.2 Generating descriptions of images
Template-based methods 機械的
Composition-based methods 人間的
Neural network methods マルチモーダルニューラル言語モデルはこれ。
キャプション生成システムは評価の仕方で悩まされ続けてる。
BleuとかRogueみたいな機械的な評価は信用に足らんし人間の判断と一致しやん。画像とキャプションのランク付けの問題が代わりになるんちゃうか。
ランク付けの改善をキャプション生成にどうやって移行する?
→ Encoder-Decoder methodsなら自然にこの実験のフレームワークにフィットする!
1.3 Encoder-decoder methods for machine translation
rescoring?🤔
我々のゴールは画像を記述に翻訳すること。
2.An encoder-decoder model for ranking and generation
2.1 Long short-term memory RNNs
Xt: t番目の単語の単語表現行列
(It, Ft, Ct, Ot, Mt): 左から時刻tにおける 入力, 忘却, セル?🤔, 出力, 中間層
2.2 Multimodal distributed representations
D: 画像特徴ベクトルの次元数
K: 埋め込み空間の次元数
V: 語彙数
W_I∈ℝ^( K × D ):画像埋め込み行列
W_T∈ℝ^( K × V):単語埋め込み行列
キャプションS: S = {w1, ..., wN}
q∈ℝ^D
x∈W_I・q∈ℝ^K
スコアリング関数s(x, v) = x・ vと定義する。(コサイン類似度に類似)
pairwise ranking loss(↓) を最適化する:

α: マージン
2.3 Log-bilinear neural language models
単一の線形隠蔽層を持つフィードフォワード・ニューラルネットワークと見なすことができるモデル。
r:= sum(Ci * wi)[i = 1:n-1]
Ci はK×Kのコンテクストパラメーター行列?🤔
rは次の単語w_nの予測表現。
条件付き確率Pは

2.4 Multiplicative neural language models
マルチモーダルベクトル空間からベクトルu∈ℝ^Kが与えられたとする。(uはワードシーケンスS={w1, ..., wN}に関連している)
例) Sによって与えられた画像の埋め込み表現
Multiplicative neural language modelsは前の単語とuからコンテクストを与えられた新しい単語w_nの分布P(w_n=i|w_1:n-1, u)をモデル化する。
単語埋め込み行列はテンソルT∈ℝ^(V×K×G)に置き換えれる。
G: スライス数?🤔
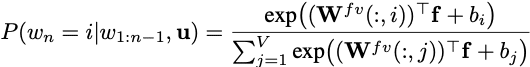
因数出力f = (Wfkˆr) • (Wfdu)がなんでこうなったんか分からん。
乗算バリアント?🤔と加算バリアント比較してみたら乗算バリアントの方が優れていた(特にデータセットが大きいとき)から、SC-NLMにも取り込んでみた。
2.5 Structure-content neural language models
T={t1, ..., tN}: 単語固有の構造変数
ti: 各単語wiに対応する品詞
他の確率を使用することも出来る?🤔
私たちのゴールは、uが与えられとき、分布P(w_n =i|w1:n−1,tn:n+k,u)
これまでの単語とこれからの単語の品詞からw_nを予測するのかな。
我々のモデルはMultiplicative neural language modelsとしてほぼ等価だが、属性ベクトルはuではなく, uとTの和...?
学習されたルックアップテーブル?🤔
T(i) ≒ C(i)
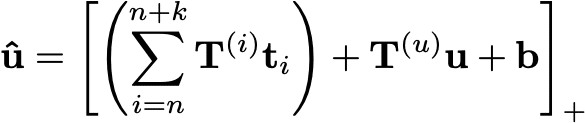
G = K = 300, F = 100
SC-NLMは画像キャプションの大コレクション(Flickr30K)で訓練されている.
条件ベクトルuは対応する画像の埋め込みにも使えるだろう。
けど我々はLSTMで計算したキャプションSの埋め込みベクトルに条件を与えるために使う。
SC-NLMはテキストのみでも訓練出来る。→画像のないキャプションでも可
画像埋め込みからSC-NLMに条件付けすることも出来る。
これは学習のために画像-キャプションのペアを必要とする条件付き言語モデルと比較すれば、めっちゃ利点。
3. Experiments
3.1 Image-sentence ranking
[15]がやったやり方と同じやり方で実験するで。
Toronto ConvNet と 19層の OxfordNet の2つを使うよ。
検証画像: 1,000枚
テスト画像: 1,000枚
訓練画像: 残り全部
評価: Recall@K (検索結果の上位K個の中で正しいキャプションがランク付けされた画像の平均数 (文章の場合は逆)(逆?🤔)
DeViCE
SDT-RNN
DeFrag a bag of dependency parses
m-RNN パープレキシティ?🤔 対数尤度関数を最適化
3.1.1 Results
我々のモデルの性能はm-RNNと同等。
いくつかの指標では既存の結果を上回るor等しい が他の指標ではm-RNNが我々のモデルを上回っている。
m-RNNは画像と文章の埋め込みを学習せず、検索手段としてのパープレキシティに依存している。
1つの行列の積で済むから、パープレキシティベースの検索方法に対して著しい速度の利点がある。
埋め込み手法は大きいデータセットでスケーリングするのに向いてる。
我々の手法とm-RNNは物体検出を取り入れれば既存のモデルを超越する。
これはエンコードや学習するのにLSTMのセルが効果的であることを強調する。
物体検出をフレームワークに統合すればほぼ確実にパフォーマンスを向上させられる。
OxfordNetの評価タスクでSotA獲得。
3.2 Multimodal linguistic regularities
v: 文章ベクトル
q: クエリ画像
wn: ネガティブな単語
wp: ポジティブな単語
を使って画像x*を探す(↓):
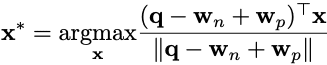
N枚の画像の平均との距離を基に再ソートすれば良き。
文章はもはや単語の総和だけにあらず。
線形エンコーダーは検索においてはLSTMエンコーダーより悪いパフォーマンスを示した。
学習済みのマルチモーダルベクトル空間は文章と画像のランク付けには向いてないのかも。
3.3 Image caption generation
SBUの画像からキャプション生成しました。
よりパーソナライズされている?🤔
the original caption と the nearest neighbour sentence はどうちゃうの?
どっちも生成した文章ではなさそうやけど。
4. Discussion
どんなときも小領域だけが文章と関わってる。