ManiGAN:テキストガイド付き画像編集

Abstract
目的:テキストと関連しない内容を保存しつつ、所望の属性(例えば テクスチャ, 色, 背景)を記述したテキストと一致するように、画像の一部をsemanticallyに編集すること
データセット:CUBとCOCO
これを実現するために、我々は、text-image affine combination module(ACM)とdetail correction module(DCM)という2つの主要なコンポーネントを含む、新しいManiGANを提案します。
ACMは、与えられたテキストに関連する画像領域を選択し、その領域と対応するsemantic wordsを相関させて効果的な操作を行います。
これは一方で、元の画像の特徴をエンコードして、テキストと関連しない内容を再構成するのに役立ちます。
DCMは属性の不一致を修正し、合成画像の欠落した内容を補完します。
最後に、画像操作の結果を評価するための新しい指標を提案します。
(新たな属性の生成とテキストとは異なる内容の再構成の両方の観点から)
1.Introduction
画像操作は、ユーザーの好みに合わせて画像の一部を変更することを目的としており、video gamesやimage editing、computer-aided designなどの分野で期待されています。
1. これまでの研究はすべて特定の問題に焦点を当てたものであり、自然言語記述を用いたより一般的で使いやすい画像操作に焦点を当てた研究は少ない。[7, 24]
2. 現在の最先端のテキストガイド付き画像操作は、低画質の画像しか生成できず、満足のいくものとは程遠く、複雑なシーンを効果的に操作することさえできません。
テキストの記述に基づいた効果的な画像操作を実現するためには、テキストと画像のクロスモダリティ情報の両方を利用して、与えられたテキストにマッチした新しい属性を生成することが鍵となります。
テキスト情報と画像情報を融合させるために、
既存の手法(ヒューリスティック)[7, 24]:チャネル方向に沿って画像特徴量とグローバル文特徴量を直接連結
1. fine-grainedな単語に、修正されるべき対応する視覚属性を正確に相関させられません。
2. 画像中のテキストに関連する部分の望ましくない修正が生じます。
⇒1・2を解決するManiGANを提案します。
また、テキストと関連しない内容を再構築するために、元の画像表現をエンコードします。
2. Related Work
Text-to-image generation
テキストから画像の生成は、GAN[11]が現実的な画像の生成に成功したことで注目されています。
Reedら[28]は、conditional GANを用いて、与えられたテキスト記述からもっともらしい画像を生成することを提案しています。
Zhangら[40, 41]は複数のGANを積み上げて,粗いスケールから細かいスケールまでの高解像度画像を生成することを提案しました。
Xuら[39]やLiら[18]は、単語レベルでの微細な情報を探索するために注意メカニズムを実装しました。
photo-realisticな画像を生成することに焦点を当てており、与えられた画像の特定の視覚的属性を操作することには焦点を当てていない。
Conditional image synthesis [1, 2, 4, 9, 20, 23, 25, 33, 34, 43]
最近では、im2im translation[3, 14, 37]やunpaired translation[21, 32, 44]を実現する様々な方法が提案されています。
領域横断的なテキスト記述を用いた画像操作ではなく、同一領域の画像変換に主眼を置いたものです。
Text-guided image manipulation
Dongら[7]は、入力画像とテキスト記述のセマンティクスを分離するためのGANベースのEncoder-Decoderアーキテクチャを提案しています。
Namら[24]は同様のアーキテクチャに、生成器に特定の単語レベルの学習フィードバックを与えることができるテキスト適応型識別器を導入しました。
効果的ではないテキスト画像連結法と粗い文条件のために、性能が制限されています。
Affine transformation
アフィン変換は、追加情報を組み込むために、または正規化によって生じる情報損失を回避するために、条件付き正規化技術[6, 8, 12, 22, 25, 27]として広く実装されてきました[8, 12, 22]。
⇔私達のアフィン結合モジュールは、すべての正規化層ではなく、特定の位置にのみ配置されています。
3. Generative Adversarial Networks for Image Manipulation
目的:I と S'が与えられた場合、Iの内のテキストと関連のない内容を保持したまま、
semanticallyにS'と一致するI'を生成すること
I:入力画像
S':ユーザから与えられたテキスト記述
I':manipulated image
これを実現するために、以下の2つの新しい構成要素を提案します。
(1) text-image affine combination module(ACM)
(2) detail correction module (DCM)
3.1 Architecture

基本的なフレームワークとして multi-stage ControlGAN [18]アーキテクチャを採用
Image Encoder:Inception-v3 [31]
ACMは、事前学習されたRNN[24]からエンコードされたテキスト表現 hと、各ステージの最後にあるupsampling blockの前の局所的な画像特徴量 vを融合させるために利用されます。
各ステージで、テキスト特徴量は、隠れ特徴 hを生成するために、いくつかの畳み込み層で洗練されます。
ACMは、さらにhをvと組み合わせて、与えられたテキストに対応する画像領域を選択し、それらの領域をテキスト情報と相関させて正確な操作を行います。
また、元の画像表現をエンコードして安定した再構成を実現します。
ACMから出力された特徴量は、対応するGeneratorに供給され、$I'$を生成するとともに、upsamplingされ、より高解像度の画像操作のための次のステージへの入力となります。
第1ステージ以外のGeneratorでは、Batch Normalizationをインスタンス正規化[35]に置き換えます。
フレームワーク全体では、S'に一致する新しい視覚属性を高解像度で高品質に徐々に生成し、さらにIの内のテキストと関連のない内容をより細かいスケールで再構成します。
DCMは属性の不一致を修正し、合成画像の欠落した内容を補完します。
3.2 Text-Image Affine Combination Module
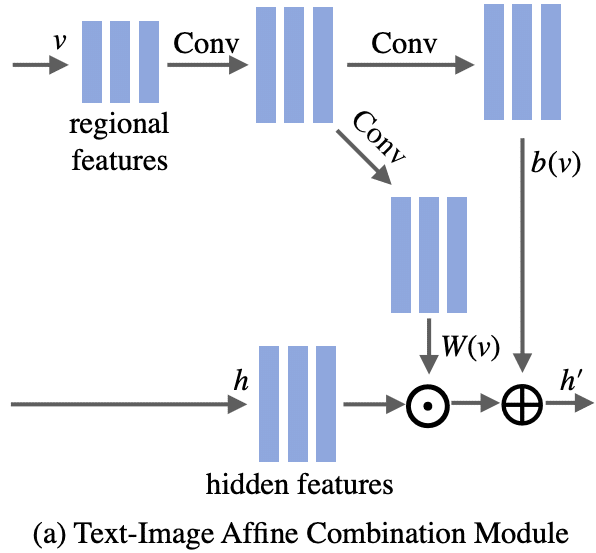
入力は2つ:
1. h ∈ ℝ^{C×H×D} (Cはチャネル数, H, Dは特徴マップの高さと幅)
2. v ∈ ℝ^{256 × 17 × 17}
vをupsampling → 2つの畳み込み層で処理 → hと同じ次元数のW(v)とb(v)を生成します。
最後に、2つのモダリティ表現を融合して、h'∈ℝ^{C × H × D}を生成します。
h' = h \odot W(v) + b(v)
\odot:アダマール積
Wとbを用いて、画像特徴量vをスケーリング値とバイアス値に変換する関数を表現しています。

W(v)とb(v)は、上図に示すように、入力画像を意味論的に意味ある特徴量にエンコードします。
乗算操作は、テキスト表現 hが画像特徴マップを再び重み付けすることを可能にします。
これは、モデルが与えられたテキストに一致する所望の属性を正確に識別するのを助けるためのregional selection purposeとして機能し、その間に、属性とsemantic wordsとの間の相関関係が、効果的な操作のために構築されます。
b(v):画像情報をエンコードし、モデルがテキストと関連のない内容を再構成するのを助けます。
上記は、正規化による潜在的な情報損失を補償するために正規化層に条件付きアフィン変換を適用する以前のアプローチ[6, 8, 12, 25]や、スタイル画像からスタイル情報を取り込むためのアプローチ[8, 12]とは対照的です。
なぜACMは連結(concatnate)するよりもうまく機能するのか?
チャネル方向に沿ってテキストと画像を連結
既存のモデル:修正が必要な領域や再構成が必要な領域を明示的に区別することができない。
新しい属性の生成と元の内容の再構成のバランスをとることが難しい。
→バランスが崩れると、テキストと関連のない内容の変更が発生してしまいます。
3.2 Detail Correction Module

入力は3つ:
1. 最後の隠れ特徴量 h_{last} ∈ ℝ^{C'×H'×D'}
2. 事前学習されたRNN(AttnGAN)[39]によってエンコードされた単語特徴量(word features)
各単語は特徴ベクトルに関連付けられている。
3. Iから抽出された視覚特徴量v' ∈ ℝ^{128 × 128 × 128}
これは、事前学習されたVGG-16 [30] からの relu2_2 層の表現
まず、単語レベルの微細な表現をh_{last}に組み込むために、前作[18]で紹介した空間的注意(spatial attention)とチャンネル的注意(channel-wise attention)を採用しました。
→空間的注意特徴量s∈ℝ^{C'×H'×D'}、チャンネル的注意特徴量c∈ℝ^{C'×H'×D'}を生成します。
→→これらをさらにh_{last}と連結して中間特徴量aを生成します。
aは、与えられたテキストに関連する視覚属性の改良に役立ち、内容をより正確&効果的に修正します。
{v~}':浅い表現v'をaと同じサイズになるようにupsampling
次に、ACMを介して{v~}'とaを融合 → {a~} を生成。
最後に、2つのresidual blocksを用いて{a~} を洗練させ(refine)、I'を生成する。
なぜDCMは機能するのか?
単語レベルの空間的注意 / チャンネル的注意は、中間特徴量マップと単語レベルの情報を密接に相関させ、細かな属性の修正を強化する。
他方、浅いニューラルネットワーク層を採用し、より詳細な色、質感、エッジ情報を含む視覚表現を導出することで、欠落していた詳細の構築に貢献。
**説明になってなくない?**
3.4 Training
[18] を見て。違うところだけ書きます。
Generator の目的関数
基本は[18]と一緒。さらに、正則化項を足す。
この項は、$I'$が入力画像と同じである場合に大きなペナルティを生じさせる。
L_{reg} = 1 - || I' - I || / CHW
I:真の画像分布からサンプリングされた実画像
I':修正結果
正則化項は、多様性を確保し、ネットワークが identity mapping を学習しないようにするために使用される。
identity mapping:恒等写像; 変化なしの出力ってことかな?
Discriminator の目的関数
[18]と全く一緒。DCMは[18]でも既に使われていた? → そんなことは無かった。
> Bowen Li (2019); Controllable Text-to-Image Generation
本論文では、高品質な画像を効果的に合成し、自然言語の記述に従って画像生成の一部を制御することが可能な、新規な制御可能なControlGANを提案する。
これを実現するために、我々は、異なる視覚属性を分離し、最も関連性の高い単語に対応するサブ領域の生成と編集にモデルを集中させることができるようにする、単語レベルの空間的・チャネル的attention-drivenなGeneratorを導入する。
また、単語と画像領域を相関させることで、より詳細な監視フィードバックを提供する単語レベルDiscriminatorを提案し、他のコンテンツの生成に影響を与えることなく、特定の視覚属性を編集できるGeneratorの学習を容易にしている。
さらに、perceptual lossを採用することで、画像生成におけるランダムさを減らし、テキストが指す特定の属性だけを編集するようGeneratorを促す。
学習
文章Sとそれに対応するground-truth画像Iをペアに持つ[18]とは異なり、COCOやCUBのような既存のデータセットは、我々のモデルを学習するためのペア学習データ(I, S') → I'_{gt}は提供されていない。
S':新しい属性を記述したテキスト
I'_{gt}:対応するground-truth 画像
Iと基底真実画像が同じで、修正文 S' が入力に存在しない場合、モデルはどのようにしてIを修正することを学習するのだろうか?
理論的には、最適解は、ネットワークが入力画像から出力への恒等写像になることである。
私たちのモデルは、[18]と同様に、テキスト記述からの画像生成(S → I)とテキストと関連のない内容の再構成(I → I)を共同で解かなければならない。
ACMで編集すべき領域と保存すべき領域を分離できるようになった。
また、与えられたテキストに意味的にマッチする新たな内容を生成するために、対になったデータSとIは明示的な教師(supervision)として利用できる。
さらに、モデルが恒等写像になることを防ぎ、与えられたテキストに関連する領域において、モデルが良好な写像(S → I)を学習することを促進するために、以下のような学習スキームを提案する。
1. 正則化項L_{reg}の導入
2. 与えられたテキスト記述に合わせた新しい視覚属性の生成と、元の画像に存在するテキスト関連コンテンツの再構成との間で、モデルが最良のトレードオフを達成すれば、Early stopping
停止基準は、モデルをホールドアウト検証で評価し、我々が提案する評価指標で測定した結果により決められる。
この記事が気に入ったらサポートをしてみませんか?