
【StableDiffusion】ControlNet anytestを使ってポーズを維持したイラスト作成してみた【ControlNet】

■記事の対象ユーザ
・サムネイル画像を作るのにキャラのイラストを入れたい
・でも絵が描けない
・3Dモデルもいじれない
・生成AIでどうにかできない?
■ようするに?
サムネ画像にあるようなポーズのメイキングを紹介していきます。

はじめに
私はnoteの記事やYoutubeの動画などでサムネイルなどを作る時に
自キャラLoRAを使ってサムネ用イラストを作っているのですが、
ポーズに関してはワイルドカードを使って色々なポーズをランダム出させていい感じのポーズを引いたら補正をするような方法で用意していました。
これがあまり効率的ではなく、それなりに時間がかかっていました。
今回、新しく公開された月須和さんのControlNet「anytest」のパワーで
任意のポーズで画像を作る難易度がグッと下がったので、驚きついでにメイキングを紹介していきます。

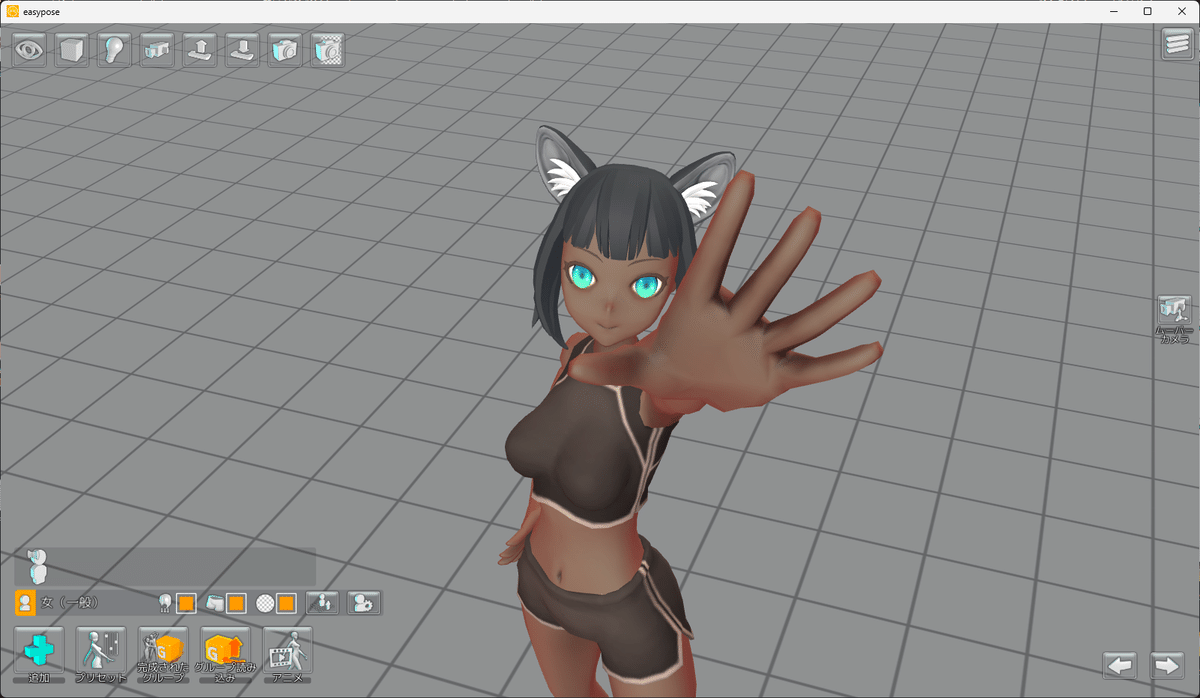
1.ポーズの撮影
今回の記事ではEasy Poseというポーズ作成ツールを使っていますが
他にも沢山方法があるので後述の付録1をみてみてね。
Easy PoseはSteamで購入できる有償のポーズ作成ツールです。
(先日セールで安かったのでつい買ってしまいました。)
ポーズのプリセットが豊富なこと、撮影用モデルの髪型や等身を多少変えられること、豊富な小道具(特に武器)を持たせられること、個人的にUIが使いやすいことなど色々あるので選定しているよ。

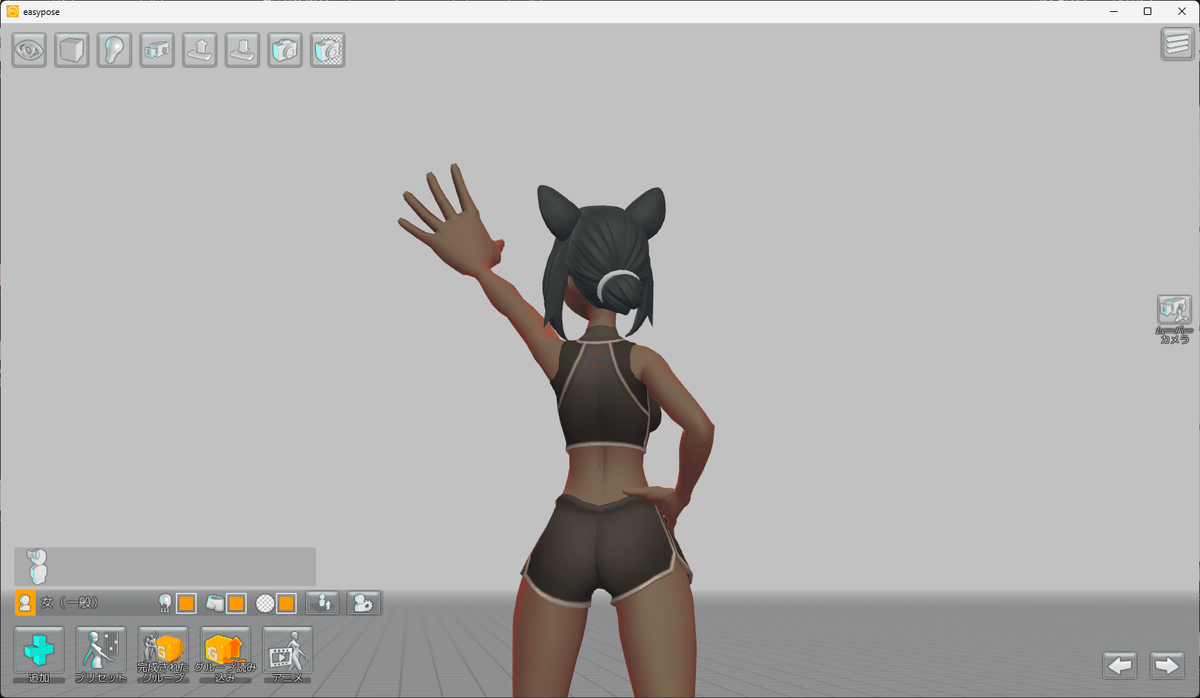
今回は嘘パース風に手を強調した、手を上に掲げるポーズを作成するよ。

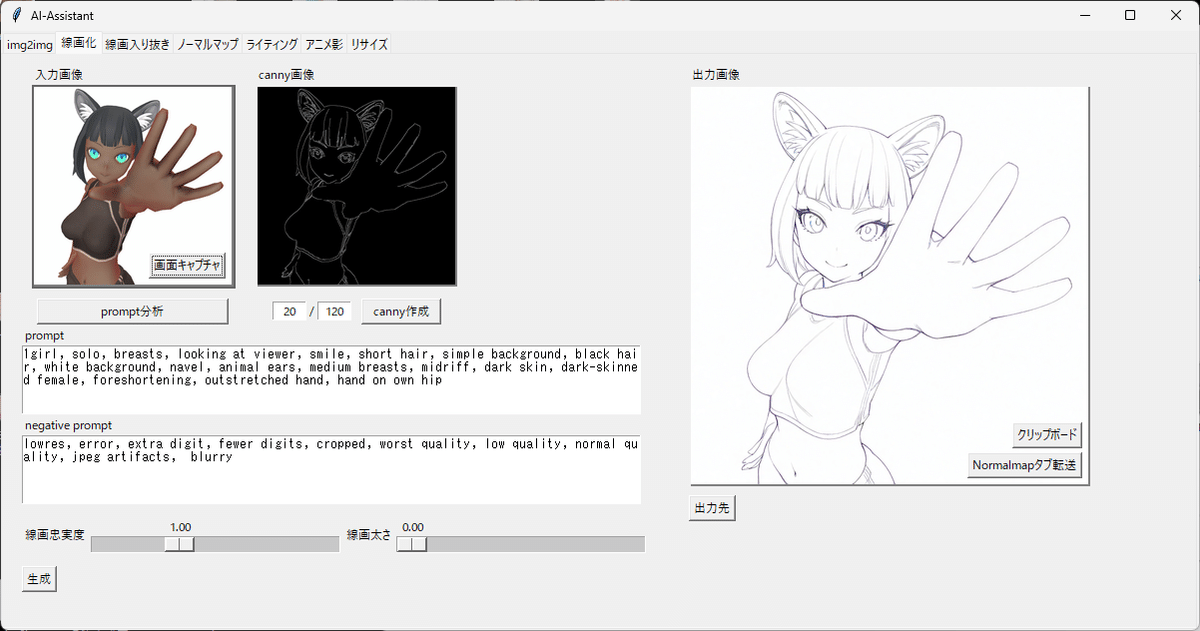
2.撮影したポーズの線画化
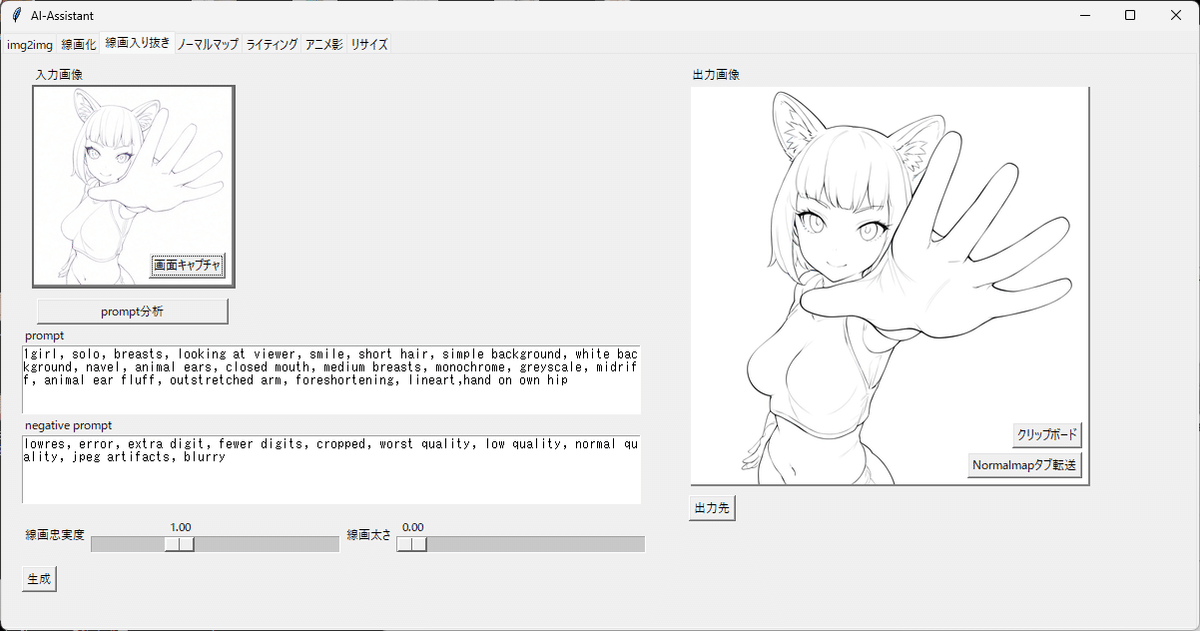
とりにくさん(@tori29umai)がAIを使ったお絵描きサポートを目的としたツールを公開されているんですが、この中の「線画化」と「線画入り抜き」機能でお手軽にいい感じの線画化することが出来るため使わせて貰っています。
EasyPoseで作成した画像を1024x1024pxでトリミングしたものを「線画化」タブに入れて「prompt分析」→「canny作成」→左下の「生成」ボタンとすると、右側に線画化した出力画像が出てきます。
右側の「出力先」ボタンで保存場所に飛べるのでそこから線画を回収するよ。

この線画でも十分なんだけど、「線画入り抜き」機能を使うと、線の強弱をいい感じに調整してくれるようになっているので、取り出した線画を
「線画入り抜き」タブの入力画像にインプット→「prompt分析」→「生成」
で同じように生成していきます。

3.線画の加工とイラスト変換
いよいよ線画をイラストに変換するんだけど、プロンプトで指定した服を着せたり、EasyPoseのモデルの髪型も調整したいのでもうひと手間加えます。
変換に使うanytestは線画が無い部分をプロンプトに合わせていい感じに補正してくれるので、PhotoShopの消しゴムを使って以下の加工をしておくよ。
・髪型をキャラに寄せるため前髪の毛先を消しておく
・元モデルの服に寄らないように服のラインを消しておく
・おへそも体のラインが出やすくなるので消しておく

入力画像の準備が出来たので、WebUIを開いてプロンプトを入れておくよ。
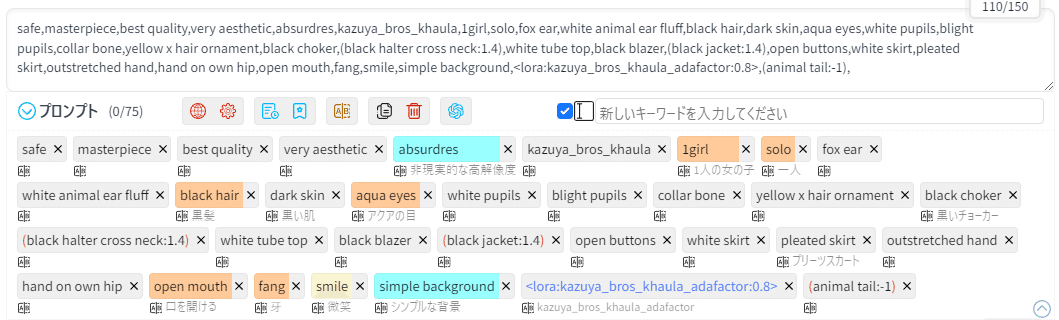
沢山書いてあるけど
・safe~absurdiresまではAnimagineXL3.1の推奨プロンプト
・kazuya_bros_khaulaは自キャラLoRAのトリガーワード
・fox ear~pleated skirtはキャラの外見と衣装のプロンプト
・outstretched hand~smileは今回のポーズと表情のプロンプト
なので、今回関係するのは実質は最後の1行くらいです

ControlNetを使わずに出力するとこんな感じの画像が出来るよ



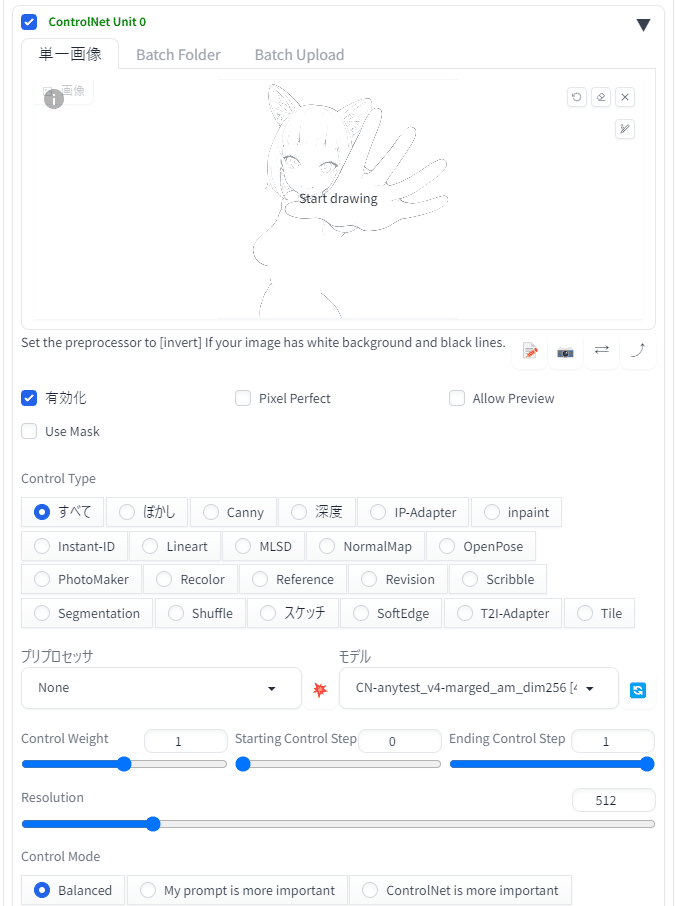
入力画像を指定して、anytest_v4のanimagine用のdim256版を選択。
それ以外はデフォルトのパラメータのままにして画像を生成するよ。

4.服やポーズを調整する
この時点でも既にいい感じなんだけど、
・線画から消した影響で腰に当ててた腕が表現できていない
・ジャケットをもっとフワッと着せたい
・手とか表情は変えたくない
ということで、調整していくよ。
PhotoShopの50%グレーのブラシで出力画像の修正したい部分を塗りつぶしていきます。左側は手を腰に当ててほしいのでそれっぽく塗りつぶし、
右側はジャケットが広がってほしい辺りまで塗りつぶします。

塗りつぶし画像ができたら、再びWebUIに戻り
入力画像に指定して、anytest_v4のマージモデルを選択。
anytestはバージョンによって効果の強弱が変わるので、いくつか試して
いい感じの変換になるものを選んでいるよ。
詳しくは後述の付録2をご覧ください。
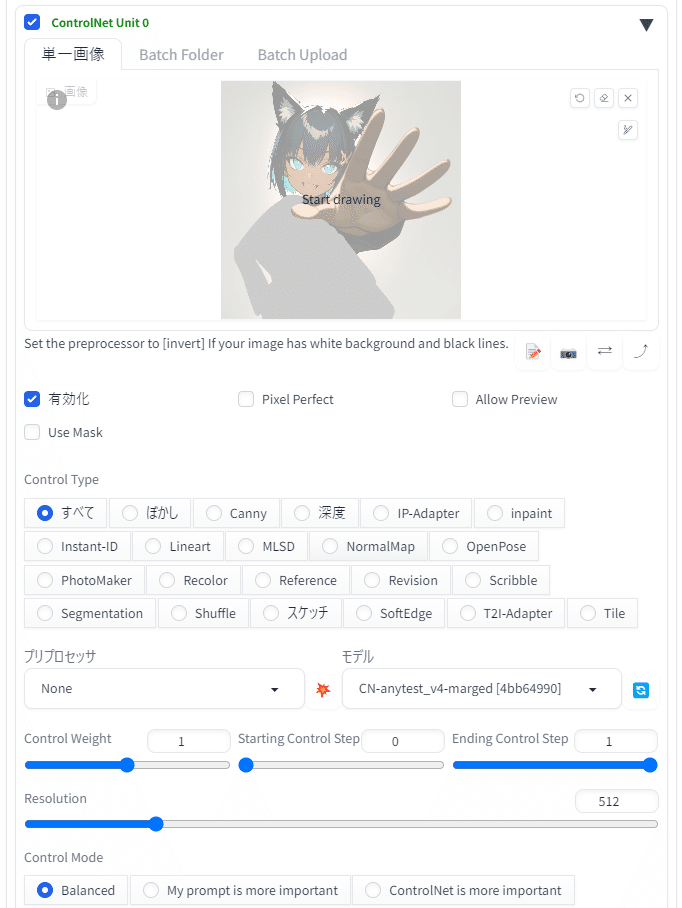
この時、最初の変換でつけ忘れてた「aqua_nail」とFlatLoRAをプロンプトに足してます。
完成した画像がこちら、塗りつぶしたの意図通り腰に腕を当てれてますし
ジャケットもいい感じにフワっと着れています。


おわりに
以上、出したいポーズをツールで作って、AI-Assitantやanytestの力を借りて
いい感じのサムネ用画像を作るメイキングでした。
今回は(嘘パースがあるとはいえ)比較的簡単なポーズだったので、anytest無しでも作れますが、言語化が出来ない複雑なポーズについてはこのanytestが効果を発揮できると思いますので、是非お試しください。
最後に手順に沿って生成した画像を並べてみるよ。
1枚目:EasyPoseの出力
2枚目:AI-Assistantで線画化したもの
3枚目:ペイントツールで不要な部分を消したもの
4枚目:3枚目からanytestでイラスト変換したもの
5枚目:修正したい部分をグレーで塗ったものの
6枚目:5枚目からanytestで書き換えたもの
7枚目:背景を切り抜いたもの

付録1:ポーズ撮影用のツールについて
本記事ではEasyPoseを使っていますが、ポーズ撮影には様々な方法があるので、ここでは私の知っている範囲でご紹介しておきます。

VRoid Studio
Blenderが使えなくてもゲームのキャラメイクの感覚でVRMが作成できるツール。作成したモデルを出力して後述のFumiFumiとかで使える他、VRoid Studio自体にもポーズのプリセットや撮影機能があります。
デフォルトのポーズプリセットは数が少なく物足りないんだけど、
Booth等でポーズ集を提供してくれている方もいるので拡張が可能よ。
FumiFumi
スマートフォンでVRMファイルのポーズを変更して撮影できるツール。
本来はスマホで撮った写真とVRMキャラでお出かけ写真とかとるツールっぽいのですが、VRMさえスマホに入れておけば出先でポーズが作れます。
ポーズプリセットがわりと豊富なのも嬉しいところ。
ただ、スマホ版しかないので自宅では流石にPCのツールの方が早いです。
こちらも追加ポーズが提供されてるのを見かけるね!

Design Doll
デッサン用の人形を作り、ポーズを作ることのできるPCツール。
無料体験版でもツール自体は使えるのですが、有償版で使えるようになる
投稿型のポーズサイト「ドールのアトリエ」からのポーズ読み込み機能が強いです。

POSE MANIACS + CLIP STUDIO
豊富な筋肉ポーズが掲載されているPOSE MANIACSは
お絵描きツールのCLIP STUDIOのデッサン人形と連携することができるため
好みのポーズをしたデッサン人形を撮影するという方法があります。
Webcam Motion Capture
チマチマツールを使うのは性に合わねぇ!!という方はモーションキャプチャという手もあります。Webcam Motion CaptureはWebカメラだけで全身モーションキャプチャができるため、自分が好きなポーズをしているところを録画しておいて画像を切り出せば肉体言語で解決ができます。
ただし、自分の身体で出来ないポーズは無理なので(ベキベキッ!!ギャー!!
blender
blenderと和解せよ
手書き
そもそも自分の思い描いたポーズを直接線画に落とし込めるのであれば
ツールは必要ないのです。

付録2:ControlNet「anytest」について

私のLoRA記事でも何度か紹介している、月須和さん(@nana_tsukisuwa)
が公開されているControlNetです。
ひとくちにどんなControlNetか説明するのが難しいんだけど、
私が観測した範囲では次の様な機能を持っています。
1.入力画像のスタイル変換ができる
入力画像を与えたプロンプトでスタイル変換することができます。
LoRAを組み合わせるとより強く効果が出せます。
anytest+LoRAによるスタイル変換いろいろ pic.twitter.com/HlnDfpSqAh
— 月須和・那々 (@nana_tsukisuwa) May 30, 2024
2.線画に対して色を塗れる
線画をインプット画像に与えるとプロンプトに応じて着色ができます。
(以下のツイートはv1の説明ですがv3/v4も同様の効果があります。)
あとはまぁ、逆に線画から色付けたりとか色々……
— 月須和・那々 (@nana_tsukisuwa) May 8, 2024
多分、設定調整して制御ガバらせるとanystyleぽい使い方もできるかもしれない pic.twitter.com/7HqBuFu5Y9
3.線画の一部を与えると余白部分をいい感じに生成してくれる
今回の記事で消しゴムで線画を消していた部分がこれに当たるよ。
消すだけじゃなくて当然加筆して調整することもできるよ。
anytest_v3、こういう使い方も出来るよ
— 月須和・那々 (@nana_tsukisuwa) June 1, 2024
まず適当な線画の手と顔以外を適当に白で塗りつぶして、anytest_v3に突っ込む
そして適当にソレっぽいプロンプトは入れてこうじゃ pic.twitter.com/f30JxkdWb2
4.塗りつぶした箇所を加筆・修正できる
今回の記事でジャケット部分の修正をしていた部分がこれに当たるよ。
線画だけじゃなくてイラストにも効果があります。
線画指定とシルエット指定の組合せ
— 月須和・那々 (@nana_tsukisuwa) June 1, 2024
線画の上から適当に太いせん描いて、プロンプトにchainとか入れただけ
当然、他のモノでも出来るよ……ロープとか触手とかさ pic.twitter.com/uXuTnIq0Q3
イラスト+シルエットも可
— 月須和・那々 (@nana_tsukisuwa) June 1, 2024
イラストの上から適当にグレーのシルエット描いて、プロンプトにScarfとか入れるとこうなる
コレならインペイントと違って、形状の指定がしやすいかもね pic.twitter.com/CyoMUXg93c
5.塗りつぶしで構図を作ると構図指定で画像を生成できる
雑な線画の下書きで画像生成できるScribbleと似た効果も持っているよ。
元画像ベースではなく、1から作る時に重宝するね。
anytest、scribbleみたいにクッソ雑なシルエットからの構図指定も出来る…… pic.twitter.com/9eWxhEfcim
— 月須和・那々 (@nana_tsukisuwa) May 30, 2024
6.低画質画像の補正
ノイズやぼかしの入った画像を与えた時にそれを除去する効果もあるよ。
anytest_v4に色々と低質な画像入力してみた、その1 pic.twitter.com/JUwjY7uFfh
— 月須和・那々 (@nana_tsukisuwa) June 3, 2024
7.【応用】線画ラフから背景を作成する
AIずきんの野火城さん(@nobisiro_2023)が検証されたものを引用させていただきます。塗りつぶしではなくScribbleと同じ使い方をしても効果を発揮。
(野火城さんもまとめ記事書かれるそうなので後日リンク張ります)
月須和さんのCN-anytest_v4-marged、背景もいけます。 数値適当にやってもこのマウス線画ラフ絵からこれができてしまう。 ScribbleとしてもLineartとしてもinpaintとしても使えそう pic.twitter.com/ANU0VmFlcD
— 野火 城@AI漫画 (@nobisiro_2023) June 4, 2024
8.【応用】白黒漫画の着色
こちらも野火城さん(@nobisiro_2023)の検証内容の引用となります。
恐ろしいのは1枚のイラストじゃなくてコマ割りされてるものが
ちゃんと処理できているところ・・・。
(野火城さんもまとめ記事書かれるそうなので後日リンク張ります)
↑大事なことなので
うおお~すごい、コントロールネットanytest_v3に白黒漫画そのまま入れてAI色塗りいけた!!
— 野火 城@AI漫画 (@nobisiro_2023) June 6, 2024
webにアップするくらいの解像度なら、色の一貫性や大きな破綻だけ手修正すれば使えそう。
どちらかと言えばV3は線画に忠実、V4はラフを清書するのにいいですね。https://t.co/xvHKgEGG1W pic.twitter.com/LKAnzpQTlC
9.【応用】入力画像の複雑なポーズを維持できる
EasySdxlWebUiを公開されているZuntanさん(@Zuntan03)の検証の引用となります。今回の私の記事のポーズはanytestなしでも再現できますが、
この例の通り自然言語で説明できない難しいポーズも出来ちゃうようです。
ControlNet の anytest_v4 で高難度ポーズ再現 その2
— Zuntan (@Zuntan03) June 6, 2024
LoRA なしで日本の文化を伝えるキン肉バスターです。
Forge Couple では難しいカラミもどんとこいです。
キャラ書き分けは以前のきららジャンプや百合太極図と同じく(img2imgでない)txt2img の CN inpaint & anytesthttps://t.co/H85hND61nj pic.twitter.com/gCoQDt83ty
10.【実験】後付けでモノを持たせる
ここからは私(@dodo_ria)の検証内容の引用となります。

4の塗りつぶし箇所の加筆を使って後から盾だったりモン〇ターボールだったりを持たせてみた例。
anytest_v3うっそでしょ😇
— カズヤ弟 (@dodo_ria) June 1, 2024
1枚目:元絵
2枚目:PhotoShopで50%グレーで塗り
3枚目:プロンプトに「wood shield」のみ記載
形状指定で武具が持てる!!!
これにイオさんが検証してた手の部分の描画補正とか
とりにくさんもやってた手の部分だけ消してガチャとかで何でも持てるようになるよね?? pic.twitter.com/45lWYQL7H8
( д ) ゜゜ pic.twitter.com/UN7y0qktlF
— カズヤ弟 (@dodo_ria) June 1, 2024
月須和さんのany_test_v4のちょこちょこ弄ってるんですが、おっしゃる通り入力画像の維持が少し弱い代わりにプロンプトが通りやすくなってますね。
— カズヤ弟 (@dodo_ria) June 3, 2024
細かい話だと、土曜の検証でやってたモンスターボール持たせるやつがv3だと中々上手く出せてなかったんですけど、v4だと一発でしたね。 pic.twitter.com/D7wvrEaEtA
11.【実験】後から服を着せ替える
3の線画の余白部分の生成を使って着せ替えをしてみた例。
腕部分の様に、服を着た時に身体のラインが変わらない部分は消さなくても対応してくれます。
昨日のつづき
— カズヤ弟 (@dodo_ria) June 2, 2024
1枚目:元絵
2枚目:とりにくさんツールで線画化
3枚目:Photoshopで必要な部分以外消しゴム
4枚目:any_test_v3でナイトヴァイオレンちゃんの服装指定
かがくのちからってすげー!!😇 pic.twitter.com/HCRHTm6HMO
逆に服装に関するプロンプトを無しにして、ip-adapterやreferenceで
別の衣装を指定した場合がこちら、雰囲気は出してくれるけど流石に厳密には真似てくれないことは分かりました。ip-adapter/referenceの限界・・・!
any_test_v3とip-adapter+referenceで着せ替えテスト
— カズヤ弟 (@dodo_ria) June 2, 2024
服装に関するプロンプトがなくてもある程度は頑張ってくれる。ただip-adapterで画風に影響が出てるのが少しきになります。 pic.twitter.com/Ukc5LvxYRq
複雑な装飾はip-adapterとreferenceだけじゃ歯が立たないですね・・・😇
— カズヤ弟 (@dodo_ria) June 2, 2024
(プロンプトに「dress」と「bare sholder」入れて補正してもこの程度)
Era3DとかRodin駆使してなんちゃって3Dモデル作って
そのモデルを参照させて出した画像を集めてそれで衣装LoRAを・・・だめだ遠すぎるぅ pic.twitter.com/iyzsUddnU7
12.【実験】イラスト変換+服の着せ替え
1のスタイル変換を使ってポーズ作成ツールからイラスト変換し
その後、4の塗りつぶし箇所の修正を使って着せ替え。
ポーズの作成には少し手間取りましたが、塗りつぶし→変換はほぼ数分の話・・・。
野火城さんがツイートされてるポーズを見て試しにEasyPoseでやってみた。
— カズヤ弟 (@dodo_ria) June 4, 2024
1枚目:EasyPose
2枚目:そのままanytest_v4で変換
3枚目:下半身を塗りつぶして「green hakama」で変換
4枚目:上半身を塗りつぶして「black kimono」で変換
v3以上にプロンプトが効いて雑な変換ができる・・・ pic.twitter.com/xStvY4D3ld
13.【実験】Rodinで生成した複雑な衣装の3Dモデルを変換
こちらは失敗例、静止画から3Dを作れるRodinに複雑な衣装を食わせた結果をanytestで復元できないかを検証したものですが、流石に3D化の時点で荒くなりすぎているため無理でした。
ポリゴン数を多くできる有料版を使うとか、出来たモデルを手元のBlenderで高画質でレンダリングするとかすれば改善するかも・・・?
複雑な衣装の一枚絵を、3D化を経由し、anytest/anystyleで別角度画像を作れないか試してみましたが、流石にRodin無料分のポン出しでは中々難しいですね。
— カズヤ弟 (@dodo_ria) June 3, 2024
1枚目:元画像
2枚目:Rodinで3D化して別角度で撮影
3枚目:anytestでモデル変換+referenceとip-adapter重ね掛け
Blenderが使えれば・・・ pic.twitter.com/7bTjYDI4FF
ダウンロード元とファイルについて
月須和さんのHuggingFaceからダウンロードできます。
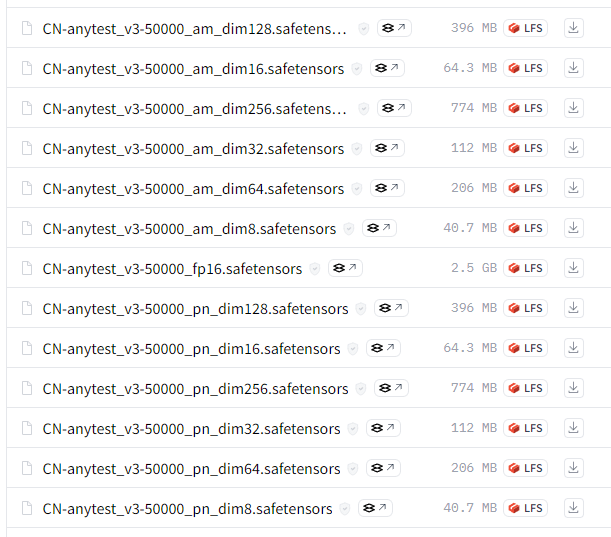

ファイル名に「_am_」と入ってる方は「AnimagineXL」向け
おなじく「_pn_」と入ってる方は「PonyDiffusion」向け
となっているよ。
「dim」については後述しているからそちらを参照にしてね
まずは次の2つのベース使ってみて、他は後からでもいいと思います。
anytest_v3:CN-anytest_v3-50000_fp16.safetensors
anytest_v4:CN-anytest_v4-marged.safetensors
【検証】anytest_v3とv4の効果の違いについて
下記の引用ツイートのとおり、v3は入力画像に対して忠実。
v4はv3に比べるとプロンプトやLoRAに対して忠実。というのが
ざっくりした違いです。
またv4だからv3よりすごいぞー!かっこいいぞー!って訳ではないので
用途に応じて使い分けるようなことが大事。
anytest_v4、入力に対する正確さよりスタイル変換と入力画像の幅広さを重視した
— 月須和・那々 (@nana_tsukisuwa) June 3, 2024
基本v3と同じような使い方が出来るけど、v3に比べると割とガバい、scribble寄りのCNかな
まぁそのガバさ故に、入力がノイズまみれだろうがモザイクかかっていようがぼやけてようが出力が壊れないっていう
anytestのv4を学習開始……多分v3より正確さは下がると思う
— 月須和・那々 (@nana_tsukisuwa) May 27, 2024
そもanytestは色々テスト用のCNなので、新しい方が性能がいいってわけでもないし
記事で使った画像でControlNetのモデルと設定だけを変えた時
どんな感じになったかを参考に掲載しておくね。
anytest_v3 は CN-anytest_v3-50000_fp16
anytest_v4 は CN-anytest_v4-marged
をそれぞれ適用してるよ




【検証】dim毎の効果の違いについて
dimは値が大きいほどプロンプトの影響が大きくなるような動きをします。
同じ入力画像に対してdimを変えた時にどうなるかを見てみるね。
v3もv4も理屈は同じなのでv4のdim64~256の3種類での変化を確認するよ。
dim64:CN-anytest_v4-marged_am_dim64
dim128:CN-anytest_v4-marged_am_dim128
dim256:CN-anytest_v4-marged_am_dim256




dimの大きさはv3/v4の違いみたいに線画の忠実度にはそこまで影響しないみたいで、消しゴム後の補正の様に何もない部分をプロンプトで埋める部分に作用しているように感じます。dim256だと「腰に手を当てる」ってプロンプトが反映されてますよね。

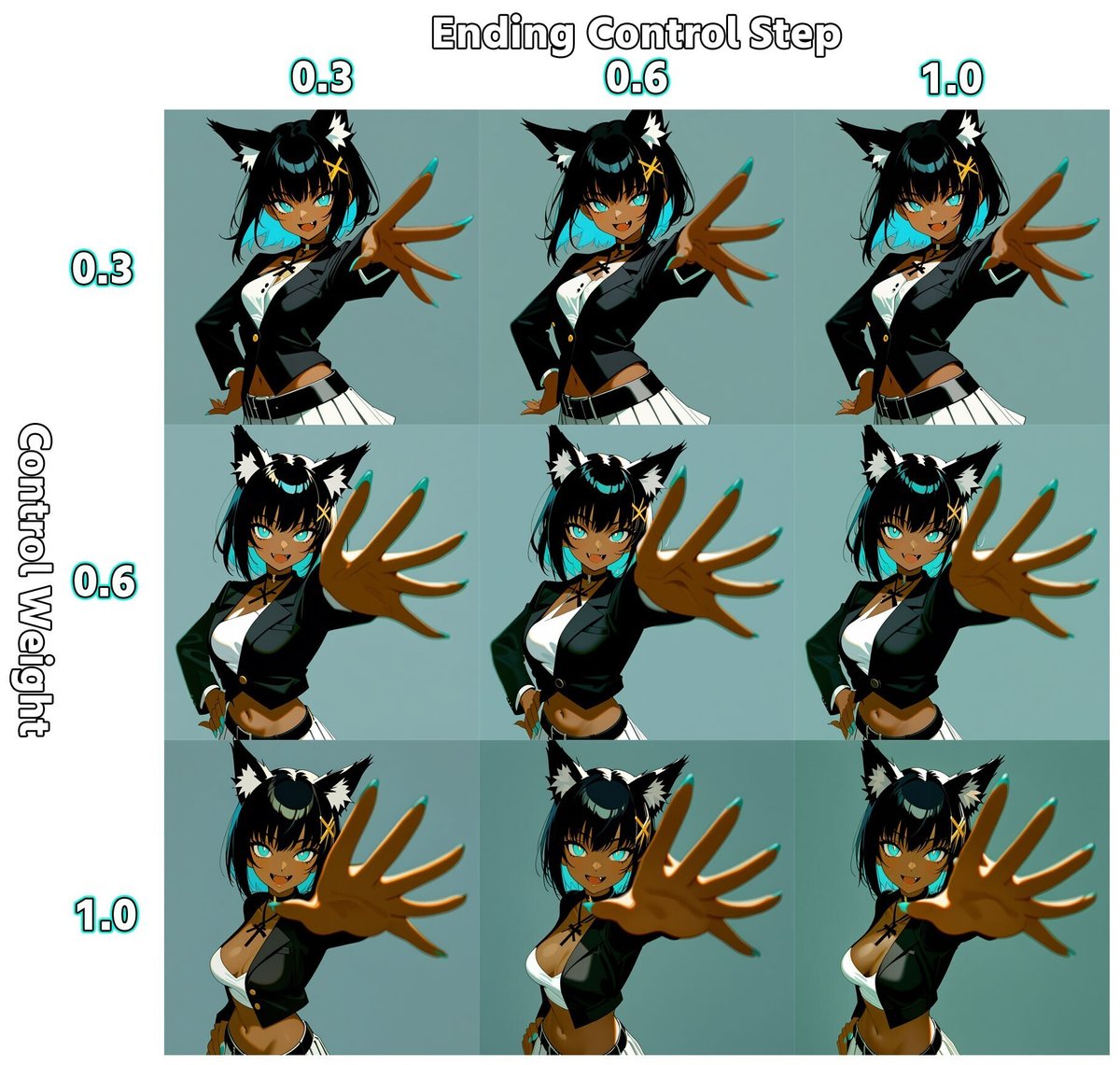
【検証】WeightとEndingStepについて
ControlNetはどの程度強く適用するかのWeight指定と、
何ステップまでControlNetを適用するかのStep指定ができます。
StableDiffusionの画像生成においては割と最初の方のステップで構図やポーズは固まってくるので、anytestの構図のについても実際はEndingStep=0.3とかでも十分反映されます。一方でWeightを弱めると構図を決める最初の部分もあまり適用されなくなるので画像の引用力が下がります。
EasyPoseの画像を入力にしてanytest_v4を適用した時に、
それぞれの値を変更してみた表を作ったので参考にどうぞ。

以上。長すぎる付録(本編)でした。