
【Stable Diffusion】StabilityMatrixでSDXL版LoRAを作ってみるまで【Kohya_ss】

■記事の対象ユーザ
1.StabilityMatrixで環境を構築してAIイラストを作っている
2.SD1.5でLoRAを作ったことはあるが、SDXLでLoRAを作ったことがない
3.SDXL環境から入門したけど、とりあえず作ったLoRAが動くところまで体験したい

■ようするに?
・それなりにGPU性能が必要
・基本的な流れはSD1.5環境と同じ
・学習素材は1024x1024で集め直す必要がある
0.はじめに
※SDXLのLoRAの学習にはGPUのVRAMが8GB~12GB程度ないとそもそも作れないのでマシンスペックが足りない人は残念だけど回れ右なの。
StableDiffusionXL(以下SDXL)環境では、従来のStableDiffusion(以下SD1.5)環境用に作成されたLoRAは適用しても効果がないです。(以下参考1・2)
なので、ちょっと大変だけど新しく作り直す必要があるよ。


■今回の記事を読んで貰うにあたって
SD1.5環境の時と同じ手順だったりパラメータだったりするものは、過去に
・SD1.5環境でとりあえずLoRAを作ってみる記事
・SD1.5環境でLoRAを作る時のパラメータの検証する記事
でそれぞれ書いているから今回の記事では省略気味に進めさせて貰うよ。
もうちょっと詳細がしりたいぞーって時はこっちものぞいてみてね。
1.StabilityMatrixでKohya_ssを準備する
「StabilityMatrix」はStable Diffusion Web-UIやComfyUIなどの環境をボタンひとつでインストールできたり、ダウンロードしたモデルを1箇所で管理か出来たりする統合環境・・・。なんだけど、実はKohya_ssの様な学習用ツールもボタンひとつでインストール出来ちゃいます。
これまではKohya_ssを入れるのに黒い画面で色々選択肢を選ぶ必要があったけど、驚くほど簡単にインストールできるようになっているから、まだの方ここの手順で導入していってね!
ちなみに下の記事ではStableDiffusion Forgeを新規導入するところを紹介してるから良かったらどうぞ。
さて、ここからが本題。StabilityMatrixを起動したところから進めるね。
左のメニューの「Packages」を選ぶと下の方に「+パッケージの追加」ボタンがあるから押してみてね。
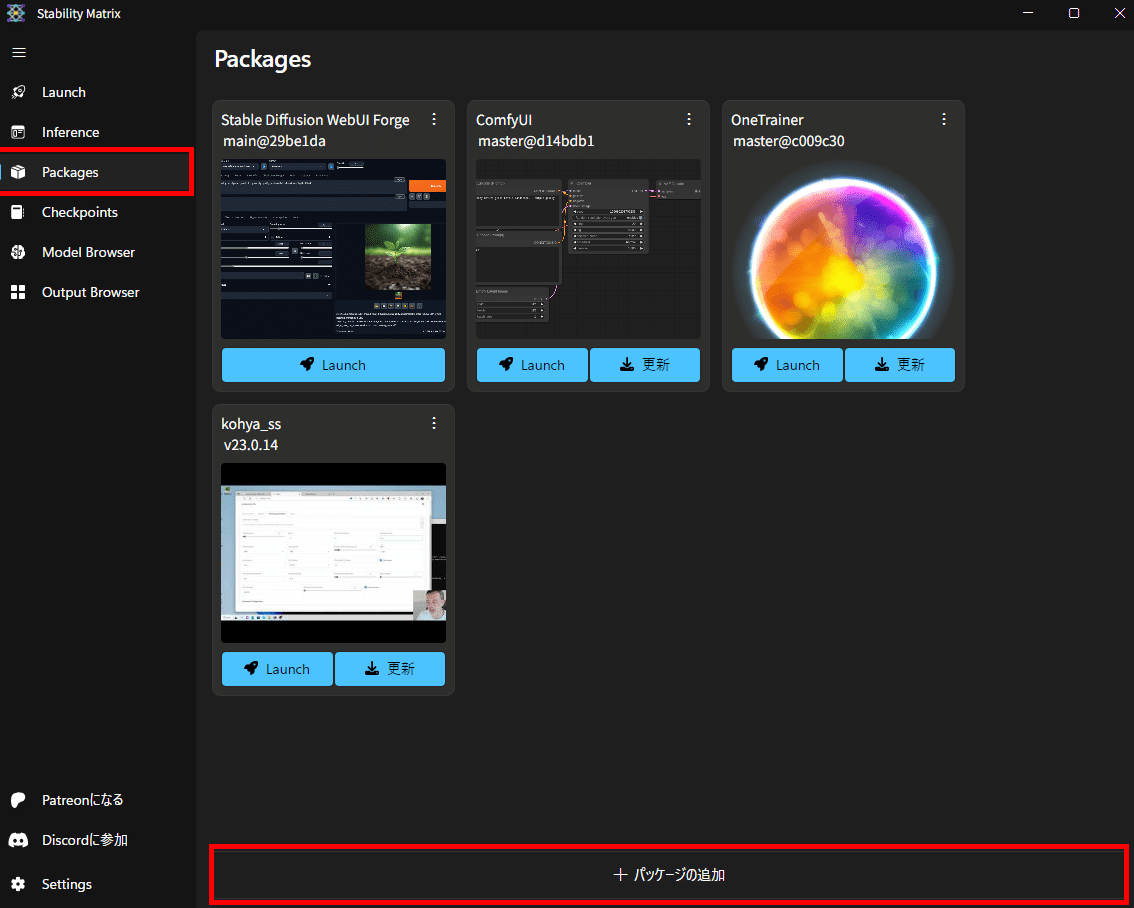
画面上部のタブの「Training」→中央の「kohya_ss」と選択
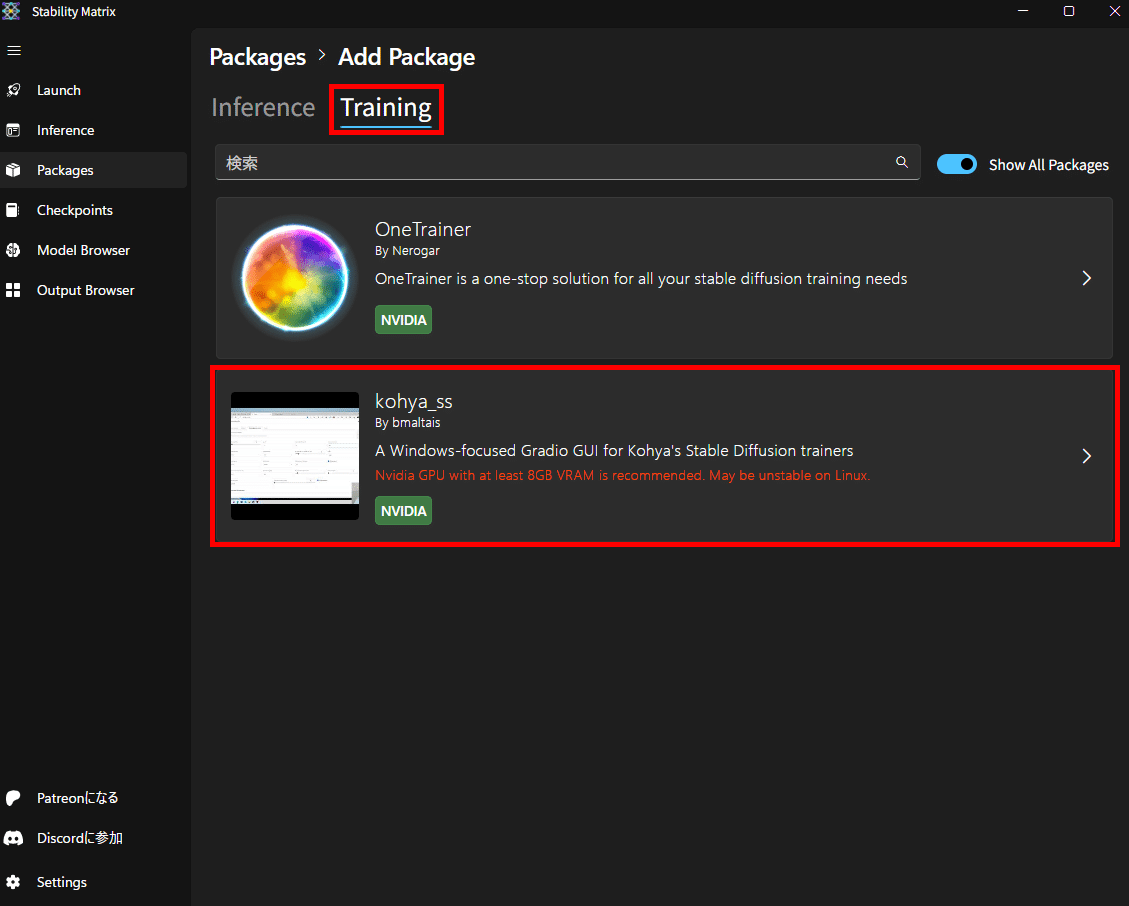
kohya_ssの詳細画面になったら「インストール」

インストールボタンを押すとこんな感じの画面が出て、あとは勝手にインストールを完了させてくれるよ。
インストールが完了したら「Packages」の一覧に表示されるから「Launch」ボタンを押してね。

「Launch」画面に切り替わって、Kohya_ssの準備が出来たら
画面下に緑色の「Web UIを開く」ボタンが現れるのでクリックで起動。
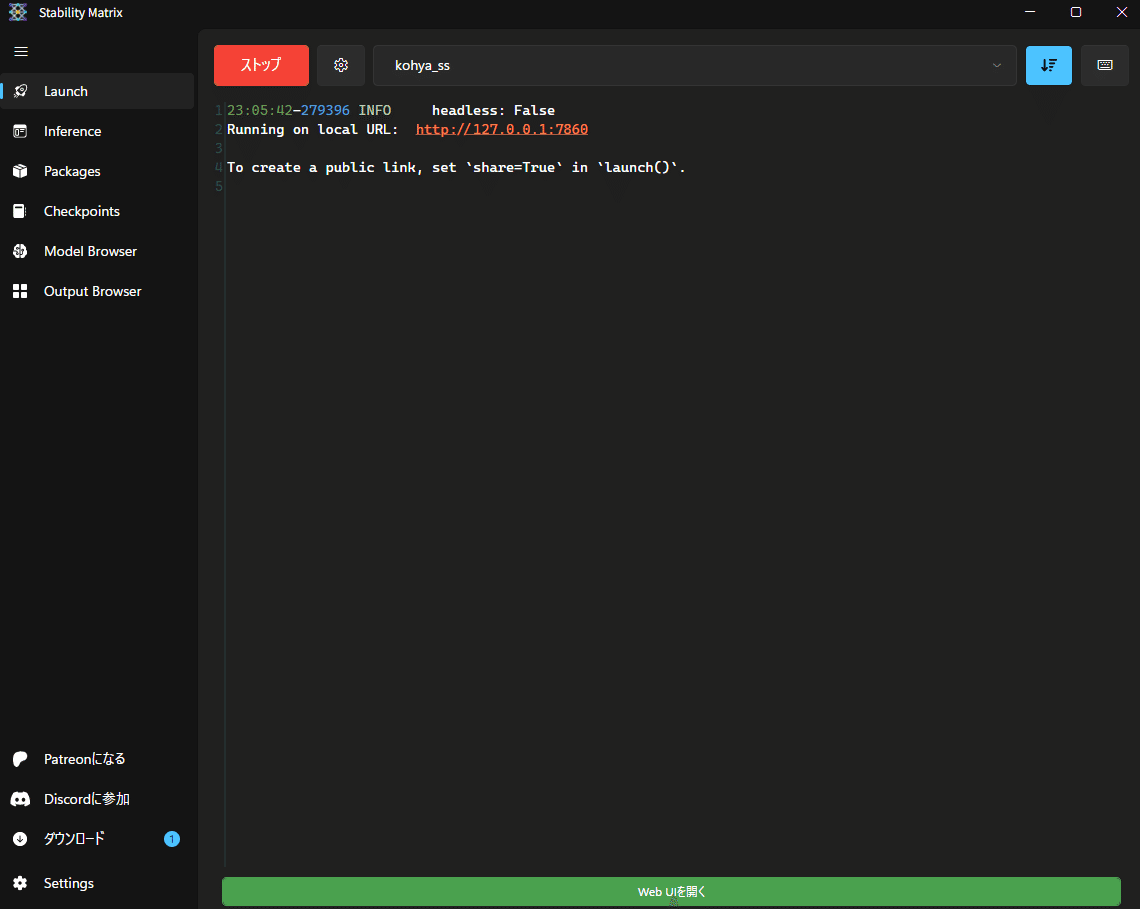
見覚えのある画面が立ち上がってきたよ。簡単ッ!簡単ッ!!
(初めての人はこんな感じの画面が出たらOKだよ)
■トラブルシューティング

私が試した時は起動時に上記の様なライブラリ不足のエラーが出たけど
Stability Matrixをバージョンアップして再起動したら普通に起動したよ。
おま環かも知れないけどメモを残しておくね
2.学習用の画像を準備する
この項ではLoRA学習に用いる画像を準備していくよ。
基本的なやり方はSD1.5環境と変わらないんだけど、SDXLは解像度1024x1024pxで学習されているモデルだから、LoRA学習用の画像も1024x1024px以上で用意する必要があるよ。
画像を集める
今回はSD1.5の時に作ったウチの子LoRAを作るために1024x1024pxの画像を45枚集めてみたよ。どんな画像が何枚くらい必要なのかは諸説あるので、学習させたい要素(キャラなのか、服なのか、画風なのか)に応じてある程度の枚数を集めようね。

過去にSD1.5環境でLoRAを作ってて、その時用意した512x512pxのデータセットを流用したいって人は、アップスケーラーを使って素材を拡大すれば(ベストではないかもしれないけど)使えるので1つの手ではあるよ。
ちなみに私は以下のアップスケーラー(Ultimate SD Upscale)を使って何枚か拡大対応しました。
画像を保存する
LoRA学習、というかKohya_ssでLoRAを作る時には画像を保存するディレクトリ構成にも気を付ける必要があるので、この項のルールは守るようにしてね。
ルール1:ファイル名は数字連番
保存する画像ファイルは数字の連番で保存する必要があるよ。
沢山画像がある場合はツールとかを使って一括リネームすると楽だよ。

ルール2:格納するフォルダの頭には数字(繰り返し数)
Kohya_ssは画像の学習を繰り返す回数を(何故か)画像が格納されたフォルダのフォルダ名から取ってくるよ。
「10_SDXL_Khaula」 → 繰り返し10回
「20_SDXL_Khaula」 → 繰り返し20回
ここの繰り返し数をいくつにするかは後述のSTEP数との相談になるけど、
フォルダ名をいじる必要があるってことだけ覚えて先に進んでね。
ルール3:指定するのは親フォルダ
後の説明でも出てくるけど、学習用画像のフォルダを指定する時は
「画像の入っているフォルダ」の「親フォルダ」を指定することになるので
「D:\10_SDXL_Khaula\0001.png」
みたいな構成は親フォルダ無くてNGなので
「D:\親フォルダ\10_SDXL_Khaula\0001.png」
みたいな構成にしておくといいよ
3.画像にタグ付けする&学習するタグの整理
LoRAの学習を行うにあたって、学習用画像にタグをつけて、画像からどんな要素を学習するかを設定してやる必要があるんだけど・・・。
ここに関してはSD1.5環境と何も変わっていないから以下の記事の「用意した画像にタグ付け」の項と「要るタグ、要らないタグの選別」の項を参照して欲しいの。
大事なところなんだけど、結構がボリュームがあるから・・・ごめんね!
一応、大まかな手順だけ書いておくと、
1.WebUIの拡張機能「Tagger」で画像に自動でタグ付け
2.WebUIの拡張機能「Dataset Tag Editor」で学習したいタグを整理
という2つの作業を行う必要があるよ。
4.Kohya_ssの設定を行う
LoRA学習の本丸だよ。
前回記事を書いた時よりバージョンが変わってUIの配置も変わっているから
今回もスクリーンショット多めで解説していくね。
※ちなみに今回のバージョンは「Kohya_ss GUI v23.0.14」


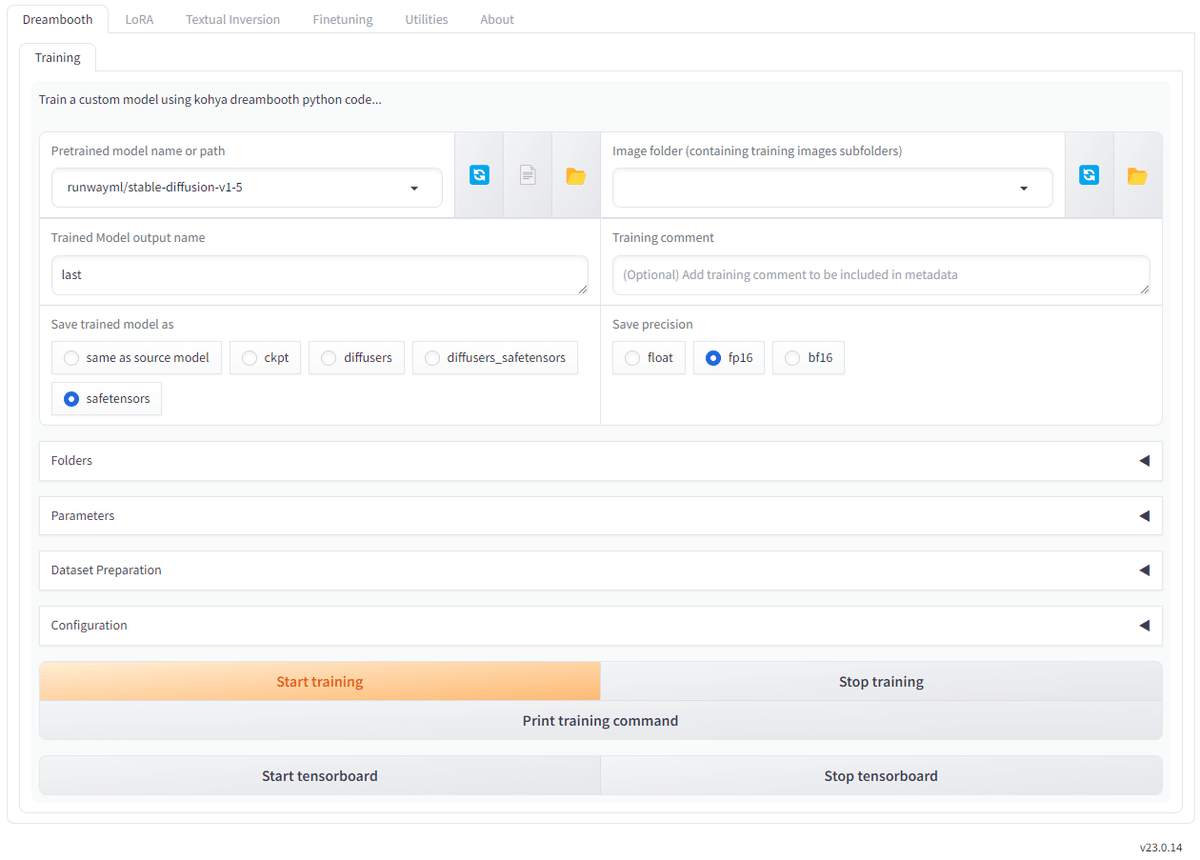
① Source model → ベースとなるモデルや学習データの場所を指定
② Folders → 出力先の指定
③ Parameters → 学習用パラメータの指定
④ Dataset Preparation → データ準備、今回は触らない
⑤ Configuration → 設定の保存/読込
4-1.Source model

①ベースとなるモデルの選択
SD1.5環境ではベースとなるモデルとして「AnyLoRA」がオススメされていたけど、SDXL環境では実際にLoRAを適用したいモデルをベースにすると良いらしいよ。今回は「Animagine XL 3.1」のsafetensorsを選択するよ
②学習画像の入っているフォルダの選択
2~3の手順で用意した、中に画像とタグ付けしたテキストファイルの入っているフォルダの「親フォルダ」を選択してね?
「親フォルダ」→「10_子フォルダ」→「学習画像」
例:
親フォルダ:D:\親フォルダ
子フォルダ:D:\親フォルダ\10_Khaula_SDXL
学習画像:D:\親フォルダ\10_Khaula_SDXL\0001.jpg③SDXLのチェック
SDXLのLoRAを作る時はSDXLにチェックを入れる必要があるよ。
④保存するLoRAの名前
完成したLoRAの名前。適当に命名しようね。
メキシコに吹く熱風という意味で、サンタナとかどうかな?
4-2.Folders

①LoRAの出力先
完成したLoRAの出力先、適当な位置を設定してね
4-3.Parameters
ここが一番大変なんだけど今回はデフォルトで用意されているプリセットをベースに必要な部分だけ変更するよ。
各パラメータの意味の解説とか、細かいチューニングはそれだけでいくつも記事が書けるレベルなので今回もとりあえず"動かしてみる"に絞って話を進めるね。

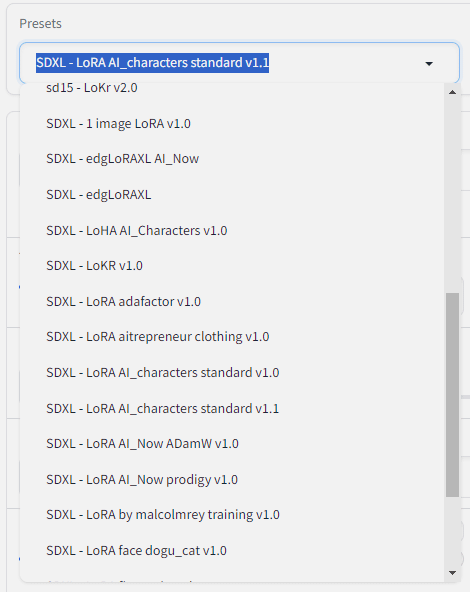
今回は、SD1.5の記事の時も採用していた学習率を自動で調整してくれる「adafactor」を使うプリセットのSDXL版っぽい
「SDXL - LoRA adafactor v1.0」
を採用してみるよ。
■ デフォルト値との差分

■学習回数(STEP数)について
SD1.5の時に上の記事で少し調べて見たんだけど、大体1,500STEP程度で効果が見て取れたので今回もとりあえず1,500STEPを目指して調整してみるよ。
STEP数の計算に必要なのは以下4つで
・Train batch size(バッチ数) ← kohya_ssのパラメータ
・Epoch(エポック数) ← kohya_ssのパラメータ
・繰り返し回数 ← 画像フォルダ名
・学習用の画像の枚数 ← フォルダ内の画像数
今回の条件で1,500 STEPを実現するには以下の様な感じになるよ
画像45枚 × 繰返し10回 = 450
→ 450 ÷ バッチ数3 = 150
→ 150 × エポック数10 = 1,500 STEPバッチ数は、学習の時に何枚同時に学習するかを指定する値なんだけど、
ここの数字は大きければ早く学習が終わるけど、その代わりGPUのVRAMを沢山使うのでメモリのエラーで止まっちゃうことがあるの。
なので、自分の環境と相談してバッチ数をコントロールしてあげてね。
バッチ数とエポック数はKohya_ssのパラメータをデフォルトから

繰り返し回数と画像枚数は画像フォルダから変更するよ。

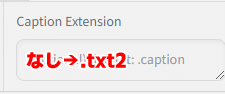
■ adafactorプリセットの注意
なぜかキャプションファイルの拡張子を指定する部分がtxtじゃなくて
「.txt2」になっているから「.txt」に直しておいてね。
■ 参考
ちなみに、各パラメータの概要については有志(hoshikat様)が記事にまとめてくれているのを見つけたので、頑張れるパワーがある人は一読してみてね。
4-4.Dataset Preparation(使わない)

「このセクションでは、データセットのセットアップに役立つ Dreambooth ツールを提供します。」と説明があるけど、ここでは特に使わないので割愛するよ。
4-5.Configuration

今回の設定を保存したり、過去の設定を読み込んだりするのに使うよ。
出力先を指定するだけなので割愛するね。
5.学習を開始する
お疲れ様でした。ここからは皆のGPUちゃんが頑張る時間だよ。
準備が整ったら画面下部にある「Start traning」ボタンで学習を開始するよ。

StabilityMatrix側の画面が以下の様になったらエラー無く学習が開始されているので、STEPSが100%になるまで気長に待とうね。

6.効果を確認する
一晩寝かせてるうちに完成するくらいの時間だと思うので、おはようかな?
恐らく出来上がってる(であろう)LoRAを早速使ってみるよ。わくわく。
4.2項で指定したディレクトリに.safetensorsファイルが出来上がっているのでStability Matrixの「Checkpoints」メニューから「LoRA」のところにドラッグ&ドロップですることでLoRAが登録されるよ。
■ 設定
モデル:Animagine XL 3.1
サンプラー:Euler a
STEP数:25
CFGスケール:8
解像度:1024x1024
同一シード値:2460454391
プロンプト
Animagine XL 3.1の推奨+トリガーワード+1girl+LoRA
ネガティブプロンプト
Animagine XL 3.1の推奨
■ 結果
LoRAの効果を0.0~1.4まで0.2刻みで出力させてみるよ。
0.6~ハッキリ効くようになってきてるけど、1.0を超えても崩れてないところを見ると1,500STEPでは少し学習が不足しているような気がするね。

7.おわりに

被験者Khaulaちゃんに悲劇は訪れたようですが、無事(?)SDXL環境でもウチの子LoRAが作ることができたよ!
最大の敵はGPUのメモリ不足なんだけど、作れるだけのGPUを積んでる皆はパラメーターとか学習素材を工夫してLoRA作ってみよう!
【2024/6/2追記】
VRAM軽減についてコメントを頂き学習時にOutOfMemoryで学習ができない場合に打てる手を再確認したので追記します。太字の項目は効果が強い印象。(画像はKohya_ss GUI v24.1.4での画像です)
・Train batch sizeを下げる(最小1)
・Max resolutionを下げる
・Network dimとNetwork alphaを下げる
64以下は誤差らしいですが、多少効果があるそうです。
※Network alphaはdimと同値か半分にしてみてください。
・Optimizerを軽量のものにしてみる
AdamW(8bit)やLionを選んでみる
AdafactorとProdidyは学習率自動調整なので
こちらを選ぶ場合はLearning Rateを1e-4(=0.0001)にしてみる
・fp8で学習する
Advance設定にある「fp8 base training (experimental)」をチェックする
(下記画像の上段左)
・Gradient checkpointingを有効にする
(下記画像の下段左)
・Memory effcient attentionを有効にする
(下記画像の下段右)

・Save precisionをfp16にする

記事内で紹介している下記記事内で「VRAM」とか「メモリ」で検索すると関連するパラメータと解説があるので参考になるかと思います。
あとは鉄板の公式ドキュメントでも同様・・・
他にもあるかもしれませんが一旦私が分かる範囲ではこのくらいですね。
参考その2 GPU何が良いか問題
ちもろぐさんが色んなグラボでベンチマークしてくれてますので参考に