
【StableDiffusion Web-UI】SDXL環境を構築してANIMAGINE & Pony Diffusionを 試したい!【環境構築】

■記事の対象ユーザ
1.StableDiffusion WebUI環境を構築してイラストを生成している
2.最近リリースされたANIMAGINE XL 3.0を試してみたいけどSDXL環境がない
3.どうせなら今話題のPony Diffusion V6 XLも・・・という欲張りさん

■ようするに?
・SDXL化自体は簡単
・ANIMAGINEはお手軽高性能だが高品質=エッチと捉えている節がある
・Pony Diffusionはクセが強すぎるが制御できると良さそう
はじめに
い、1/11にANIMAGINE XLがリリースされたタイミング記事を書き始めたはずが、パルワールドに現を抜かしていたらいつの間にか3月になっていて情報が古くなっていた。何を言ってるかわからねーかと思うが折角だから加筆をはじめた3月上旬の情報にアップデートしてお送りするぜ。
今回は手元にSD1.5環境しかない人(つまり私)向けの記事となるので
まず公式のSDXL環境を構築して、そのあとにアニメ調SDXLモデルの代表格と噂のANIMAGINE XLとPony Diffusionを使えるようにしていくよ。
長くなるのでSD1.5とSDXLについては本記事では割愛させてもらうね。
ANIMAGINE XL 3.0について
2024/1/11に公開されたSDXL向けの新モデル。
テキストからイメージ生成するにあたり、よりプロンプトを理解するようになり、破綻も少なくなり・・・という文句で紹介されているけど
要するに「より高品質なアニメ調画像を出せるようになったよ!」
この部分はSDXL環境においては弱かったらしいので、話題になっているみたいね。
ANIMAGINE XL 3.0 IS LIVE!
— Linaqruf (@linaqruf_) January 10, 2024
We are happy to announce the launch of Animagine XL 3.0. The next iteration of our opinionated open-source anime text-to-image model. Compared to the last iteration, it has better knowledge, better concept, and prompt understanding. It also can generate… pic.twitter.com/HfSTs3GPte
<日本語訳>
ANIMAGINE XL 3.0 がリリースされました!
Animagine XL 3.0 のリリースを発表できることを嬉しく思います。 私たちの独自のオープンソース アニメ テキストから画像へのモデルの次のバージョン。 前回のイテレーションと比較して、より良い知識、より良い概念、そして迅速な理解が得られています。 また、より優れた手の解剖学的構造を生成することもできます。
Pony Diffusion V6 XLについて
2024/1/15(1/7?)に公表されたSDXL対応モデル。
元々はマイリトルポニーを極めるために作られていたモデルらしいのですが
いつの間にかアニメ調の画像生成に対して抜群の性能を持つようになっていた狂気を孕んだモデル。ANIMAGINEより性能が良いなんて噂も。
(最近だとよりアニメよりにした派生モデルもあるとか何とか)
Pony Diffusion V6 is out!
— Astralite Heart (@AstraliteHeart) January 15, 2024
Pony/furry/humans. SFW/NSFW. Simple prompts and quality tags. Anime, cartoons and semi-realistic styles. Don't sleep on this model.https://t.co/a3DpxMdwlf#stablediffusion #aiart #aiartist #stablediffusionart #mlpfim #aidrawing #aiアート #aiイラスト pic.twitter.com/o5k45My9Py
事前準備①公式のSDXLモデルのダウンロード
SDXL環境では「Baseモデル」「Refinerモデル」「VAE」という3つのモデルを使うよ。まずは公式から以下をダウンロードしてこようね。
全部で10GB超あるから注意しようね。
Baseモデル:「sd_xl_base_1.0.safetensors」
通常のCheckPointと同じ
Refinerモデル:「sd_xl_refiner_1.0.safetensors」
アップスケール時に使うモデル、必須ではない
VAE:「sdxl_vae.safetensors」
SD1.5ではVAEは適当でも画像出たけどSDXLだと影響が大きいらしいよ
事前準備②ControlNetモデルのダウンロード
SDXL環境ではSD1.5環境で使っていたControlNetのモデルが利用できないので事前に必要なモデルを取得しておくことを推奨するよ。
同じ機能のモデルを複数の作者様がそれぞれ公開しているのでどのモデルがいいかは実際に使ってみて判断してみようね。
この記事では代表してイリヤスフィールさんと、青龍聖者さんのモデルを紹介しておくよ。
https://t.co/jUYPh3tYl1
— 青龍聖者@ひぐらしのなく頃に 鑑賞勢 (@bdsqlsz) October 12, 2023
qinglong-controlnet-lllite collection
i will post changelog in this twitter
list now:
animeface_segment
mlsd
normalmap
color/shuffle
To do list:
dwpose
lineart
recolor
clothingsegment(maybe)#ai #AIArtwork #sdxl #ControlNet #SDXL
事前準備③ANIMAGINEとPony Diffusionモデルのダウンロード
CivitaiからAnimagine XL V3とPony Diffusion V6 XLのモデルをダウンロードしてくるよ
10GBくらいあるから気長に待とうね(私は一晩寝かせておいたよ)
ダウンロードしたモデルはモデル置き場に配置しようね
[モデル]
\stable-diffusion-webui\models\Stable-diffusionStableDiffusion Web-UI環境での設定
事前準備が終わったら設定に移るよ。ダウンロードしてる内にやる気削れてない?大丈夫?
ダウンロードしてきたモデルとVAEをそれぞれ配置するよ
モデル2つはモデル側に
Baseモデル:「sd_xl_base_1.0.safetensors」
Refinerモデル:「sd_xl_refiner_1.0.safetensors」
VAEはVAE側に配置してね
VAE:「sdxl_vae.safetensors」
[モデル]
\stable-diffusion-webui\models\Stable-diffusion
[VAE]
\stable-diffusion-webui\models\VAEControlNetのモデルも同様にControlNetフォルダに配置しておこうね
[ControlNet]
\stable-diffusion-webui\models\ControlNetSDXLの利用にあたって
配置が終わったらWebUIを起動してモデルとVAEを指定するよ
VAEを選ぶプルダウンがここにない人は設定タブのVAEメニューから選べるよ
モデルとVAEにSDXL公式から落としてきたものを選択し、
Baseモデル:「sd_xl_base_1.0.safetensors」
VAE:「sdxl_vae.safetensors」
生成する画像の幅と高さを1024x1024にして生成するよ。

SDXLはこれまでのSD1.5と違って1024x1024で最適化されているので、基本512x512じゃなくて1024x1024で生成するようにしようね。
【補足】公式推奨の解像度
ここから選んで生成して、任意に切り出しやアップスケールを
1024 x 1024 (1:1)
1152 x 896 (9:7)
896 x 1152 (7:9)
1216 x 832 (19:13)
832 x 1216 (13:19)
1344 x 768 (7:4)
768 x 1344 (4:7)
1536 x 640 (12:5)
640 x 1536 (5:12)
ControlNetについて
事前準備②で書いた通り、既存のControlNetモデルが使えないので
ダウンロードしてきたSDXL対応のControlNetモデルを選ぶ必要があるよ

「1girl」だけで生成してみる。出来はともかくちゃんとCannyは効いてるみたいね!

LoRAについて
SDXL環境はSD1.5環境で作ったLoraは効かないらしいので
試しにSD1.5で使っていたウチの子のLoRAを当てて動作を確認してみるよ。



確かに!これっぽっちも効いてないね!
EasyNegative(embedding)について
SD1.5でお世話になったEasyNegativeだけど、SDXLだと使えないようです。
同じ作者さんが「negativeXL」というSDXL版EasyNegativeを提供してくれているのでダウンロードしてembeddingsフォルダに置いておこうね
WebUI環境で途中まで書いてた記事をStabilityMatrix環境で加筆したものだから、もしかしたら保存先が「embeddings」じゃなくて「TextualInversion」になっているかもしれないよ
ANIMAGINE XL 3.0
まずはSDXL公式モデルとANIMAGINE XL 3.0を同条件で比較してみるよ
■環境
サンプラー:DPM++ 2M Karras
ステップ数:30
CFGスケール:7
全て同一シード値を使用
1.プロンプト指定なし

2.1girlのみ

3.1girl+sky+smile

4.1girl+sky+smileにnegativeXL

この時点で私なんかは「はえーすっごい」と感心しちゃってたんだけど、
ANIMAGINEモデルの説明をちゃんと確認すると

ということで、サンプラーを「Euler a」にした上で、
推奨のプロンプトとネガティブプロンプトを設定してみるよ
[推奨プロンプト]
masterpiece, best quality[推奨ネガティブプロンプト]
nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name5.サンプラー変更
DPM++ 2M Karras → Euler a

6.推奨プロンプト追加
(masterpiece, best quality) 追加

7.推奨ネガティブプロンプト追加
スコアの高いデータセットはNSFW(エッチなの)なのでってこういうことなのね・・・、ネガティブにNSFWが入ってるのも納得

Year Modifier(直訳:年就職子)

ANIMAGINEの説明をみて驚いたのは年代で画風制御ができるというタグ。
学習した画像の時代で制御してるのかしら?試しに並べてみるよ

Pony Diffusion V6 XL
モデル紹介で書いた通り、従来のモデルと比べてめちゃくちゃ癖が強いよ。
Civitaiの説明を確認すると
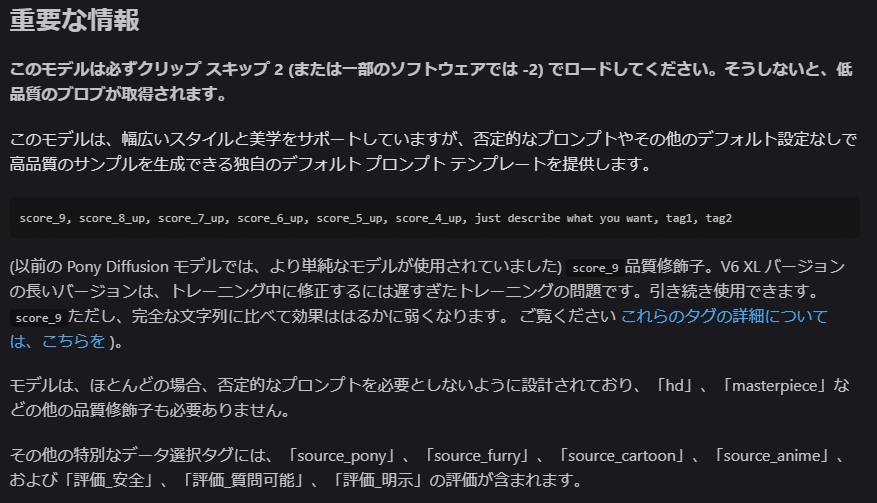

Clip Skip = 2 、ステップ数 = 25、サンプラーを「Euler a」に指定する他
以下のデフォルトプロンプトテンプレートを推奨する等書いてあるよ
score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up,
just describe what you want, tag1, tag2更にインターネットを検索すると「source_pony」や「source_furry」といったマイリトルポニー要素をNegativeプロンプトで指定することでマイリトルポニーっぽい画風を除外でき、結果品質が向上する・・・という情報も。
(このモデルの存在意義を真正面から否定するような狂気を感じる)
上記設定を順に取り入れながら変化を見ていくよ
■環境
サンプラー:Euler a
ステップ数:25
CFGスケール:7
Clip Skip:2
上のAnimagineXLの検証と同一シード値を使用
1.プロンプトなし

2.1girlのみ

3.1girl+sky+smile

4.推奨プロンプトの付与
(score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up)

5.ポニー要素除外
ネガティブプロンプトに(source_pony,source_furry)

5.アニメ調追加
プロンプトに(source_anime,source_cartoon)

おわりに
今回はSDXLの導入と、アニメ調モデルの有名どころの2つのお試しをやってみたよ。
まずSDXL導入についてはモデルのダウンロードに時間がかかったり、使うGPUがRTX2000番台だとそもそも動かなかったりする問題はあるものの、導入自体は簡単に出来たね。
ANIMAGINEとPony Diffusionについては、色々と推奨設定や注意事項があるものの、公式SDXLモデルに比べてアニメ調画像の生成が格段に上手くなっていて、当時タイムラインを賑わせていたのにも納得がいきました。
そしてこれらが2024年1月の話で、加筆時点の2024年3月には更なるマージモデルが続々と登場しています。モデル試しに夢中になって作りたいものが作れない本末転倒マンにならないよう気をつけないとね・・・
折角なので最後に両モデルのプロンプトだけでウチの子(Khaulaちゃん)出力してみたよ!
次はSDXL環境下でのLoRA学習について調べていく予定だから、興味があればまた覗きに来てね。


この記事が気に入ったらサポートをしてみませんか?