
【StableDiffusion】Animagineの出力を厳選してつくる衣装LoRA制作メモ

■記事の対象ユーザ
1.SDXLのLoRAを作っている(=つよつよグラボを持っている)
2.衣装LoRAを作ってみたが上手く行かない
3.データセットとキャプションをどうしたら良いか判らない
■ようするに?
プロンプトだけだと低確率でしか出せない服を厳選してLoRAにすることで出現確率があがるようにしてみたよ。という話
はじめに
先日書いたVRoidのスクリーンショットから服LoRAを作る記事なんだけど、元々はこの記事の内容とあわせて1つの記事になる予定だったのよね。
あっちは「ベースモデルでは表現できない(言語化出来ない)衣装」がテーマで、こちらは「ベースモデルでもガチャを回せば再現出来るけど成功率が低い衣装」がテーマということで分けた方が分かりやすいかなと思って。
こちらは特段変わったことはしてなくて、自分の学習準備とパラメータ値の備忘の面が強いので一例として参考になればって感じの内容です。
1.今回の目標
今回のテーマはウチの子「Khaula」ちゃんの私服インナーなんだけど、
このLoRAを作るまでは「halterneck」とか「halter cross neck」とか「crop top」とか「tube top」なんかを強度調整しながら試行回数で殴ってました。


もちろん粘れば上の1枚みたいに出せることもあるにはあるけど、この為だけに数十枚~レベルで出力を続けるのは時間的にも電気代的にも気が引けるよね。

上記のタグでAnimagineさんに大量にかつ色んな方向から見た画像を生成してもらい、正解の画像を集めてデータセットにするっていうやり方でこんな感じの補正効果を持つLoRAが出来上がりました。

2.覚えたい衣装について
データセットを闇雲に作り始める前に「そもそもKhaulaちゃん私服のインナーってどういう服なのよ」ってのをイメージしておく必要があるよ。

アウターのジャケットを着ていない状態はとこんな感じをイメージ。
(物理的に不可能な服だとかは気にしないものとする)
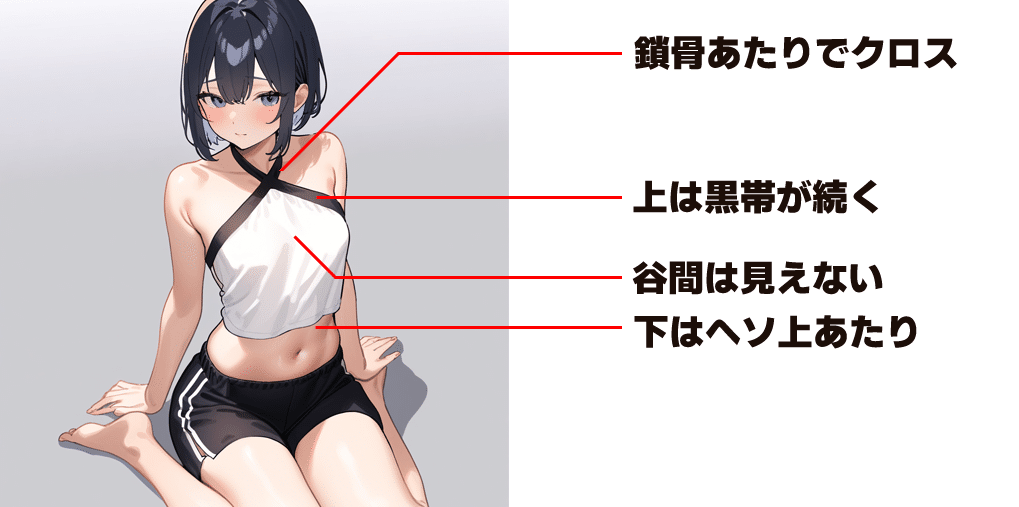
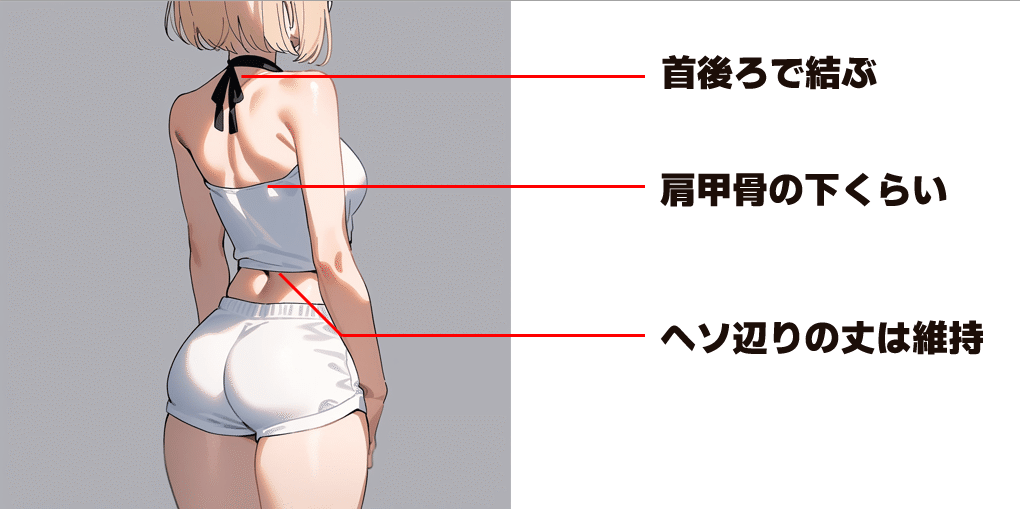

とまぁ、こんな感じのインナーの上の部分だけを学習しようってわけ
3.データセットについて
素材となる正解画像を求めてAnimagineさんに生成を頑張ってもらうわけだけど、まずは自分でそれっぽいプロンプトを考えるよ。
基本となるプロンプトの用意
■ ポジティブプロンプト
__animagine__:Animagine XL 3.1の推奨ポジティブプロンプト
1girl:1人の女性
solo:1人
very short hair:とても短い髪
(chorker:-1):チョーカー(のマイナス指定)
halter neck:ホルターネック
halter cross neck:交差したホルターネック
black shoulder strap:黒い肩紐
(cleavage:-1):胸の谷間(のマイナス指定)
white tops:白い上着
fit body tops:フィットする上着
navel:おへそ
shorts:短パン
bare arms:裸の腕
bare legs:裸の足
neck string:首紐
simple background:シンプルな背景
■ ネガティブプロンプト
__animagine_negative__:Animagine XL 3.1の推奨ネガティブプロンプト
chorker:チョーカー
swimsuit:水着
(realstic:0.5):リアル調
nipple:乳首
【補足】 ワイルドカードについて
__animagine__とか__animagine_negative__はWebUI拡張のワイルドカードを導入していると使える書き方で、事前に別ファイルで用意したプロンプトを呼び出すことができるので、それぞれにAnimagine XL 3.1のポジティブ・ネガティブプロンプトを設定しているよ。
ワイルドカードなしで書くと以下のような感じになるね(長い)
# ワイルドカード ( __animagine__ )
safe,masterpiece,best quality,very aesthetic,absurdres
# ワイルドカード ( __animagine_negative__ )
sensitive,nsfw,lowres,(bad),text,error,fewer,extra,missing,worst quality,jpeg artifacts,low quality,watermark,unfinished,displeasing,oldest,early,chromatic aberration,signature,extra digits,artistic error,username,scan,[abstract](chorker:-1)みたいなマイナス指定はWebUI拡張のNegpipを使っています。
マイナスついてたりネガティブプロンプトにあるのは出てほしくない要素が出やすい時に指定していると思えばいいよ
何枚か作ってみると、こんな感じのが出力されるけど・・・



アクセサリ辺りはネガティブプロンプトに「jewelry」でも入れれば回避できそうだけど、下の帯を回避するのは自然言語では難しいのよね・・・
とはいえ、たまに正解の画像が作れるようにはなったから、試行回数を増やして物理で殴る・・・!前にワイルドカードの準備をするよ。
ワイルドカードの準備
上で引用したとおり、ワイルドカードは事前に用意したプロンプトの中からランダムで1つ選択してくれる機能なので、基本のプロンプトに追加で「範囲」「方向」「ポーズ」、おまけで「胸の大きさ」あたりを用意しておくと様々な画角から多彩なポーズが撮影できるようになるよ。
基本プロンプトに下記のワイルドカードを指定して色んな方向から画像を生成し、お目当ての画像が集まるまでAIに労働を続けて貰うね・・・
■ 範囲
full body:全身
upper body:上半身
cowboy shot:首下~太腿
■ 方向
front view:正面
from behind:背面
side view:側面
from above:上から
from below:下から
■ ポーズ
sitting:座る
standing:立つ
arms_up:腕を上げる
waving:手を振る
などなど(※)
■ おむね
flat chest:胸に72の傷を持つ、女
small breasts:正解に近い、もっとも限りなく正解に近い
large breasts:でっ!
huge breasts:でっ!!!!
gigantic breasts:でかすぎんだろ・・・
※ポーズについてはイオさんの超辞典で配布されているのを愛用してますが、有料記事からの引用ですので少しだけ抜粋して書いておきます。
私は準備してあって楽だからワイルドカードを使っているけど、別にランダム要素の数が少なかったらDynamic Promptを使って{}で括った中からランダム選択する方法でも問題ないよ。勝てばよかろうなのだ。
ワイルドカードやダイナミックプロンプトとかの拡張機能そのものについては過去記事で紹介してるから良かったら見てみてね。
厳選してまとめる
そんなこんなで数百枚生成して、色々な範囲・方向から成功したものから正解画像を厳選していくよ。厳選後、顔の部分が入ってしまうと学習に影響が出るのでPhotoShopとか使って顔部分は映らないように加工しておこうね。

画像の準備ができたら通常のLoRA作成と同じようにWebUI拡張のTaggerでタグをつけ、Dataset Tag Editorで服装に関する部分を削除+先頭にトリガーワードを付与したら完成です。
タグ付け周りは過去記事を参照されたし。

キャプション付きの画像セットがこちらです。ご査収ください。
4.Kohya's GUIでの学習設定について
学習設定については今回の本題ではないから、上手く行った設定を参考に残しておくだけにしておくね。
詳細は学習設定を読み込んでみてください。
学習に使ったバージョン:kohya_ss_v24.1.4
グラボ:RTX3080 10GB
学習時間:1時間程度
■ Model
Pretrained model name or path:Animagine XL 3.1を指定
Trained Model output name:任意のLoRA名を指定
Image folder (containing training images subfolders):教師画像の配置されているフォルダ(の1つ上のフォルダ)を指定
SDXL:✅

■ Folders
Output directory for trained model:LoRAの保存先を指定

■ Parameters
Train batch size:うちのRTX3080 10GBでは2が限界
Epoch数:10(16枚でバッチサイズ2だと10エポックで1600STEPになる)
Save every N epochs:2(チェック用に少し細かく保存)

LR Scheduler:cosine
Optimizer:Prodigy
Optimizer extra arguments:decouple=True weight_decay=0.1 betas=0.9,0.99

Learning rate:1 (Prodigyは自動調整のため)

Network Rank (Dimension):16
Network Alpha:1

fp8 base training (experimental):✅ VRAM節約
Gradient checkpointing:✅ VRAM節約

すべて設定を終えたら学習開始で1時間ほど待ちます。
5.動作確認
完成したLoRAの動作確認のため今回学習したインナーだけじゃなくて私服全体を出すプロンプトを用意し、そこにLoRAを当てて動作を確認するよ。
通常プロンプト(LoRAなし)
■ ポジティブプロンプト
__animagine__,
1girl,solo,kazuya_bros_khaula,dark skin,fox ears,white animal ear fluff,black hair,aqua inner hair,short hair,yellow x hair ornament,aqua eyes,white pupils,bright pupils,black choker,halterneck,crop top,black jacket,black belt,white skirt,pleated skirt,black thighhighs,dorsiflexion,(bare sholder:-1.5),smile,open mouth,
<lora:kazuya_bros_khaula_adafactor:0.4>,
<lora:sdxl2-flat2-512b:0.5>,
■ネガティブプロンプト
__animagine_negative__,
animal tail,tail,
反映プロンプト(LoRAとトリガーワードあり)
■ ポジティブプロンプト
__animagine__,
1girl,solo,kazuya_bros_khaula,dark skin,fox ears,white animal ear fluff,black hair,aqua inner hair,short hair,yellow x hair ornament,aqua eyes,white pupils,bright pupils,black choker,khaula_tops,halterneck,crop top,black jacket,black belt,white skirt,pleated skirt,black thighhighs,dorsiflexion,(bare sholder:-1.5),smile,open mouth,
<lora:0706_khaula_tops7:0.5>,
<lora:kazuya_bros_khaula_adafactor:0.4>,
<lora:sdxl2-flat2-512b:0.5>,
■ネガティブプロンプト
__animagine_negative__,
animal tail,tail,
上記のプロンプトで出した画像がこちら。
学習していたインナーの部分がきれいに出ていることが判るね。

たまたま良いのが出ただけの可能性もあるから他にもいくつか試してみたけど中々の高確率(1/3くらい)で正解の画像が出力できるようになったよ。




私ももう少し素材いるかなぁと思ってたけど、意外と少ない枚数でも効果が出てることが確認できたね。元々モデルが出せる物を正解に誘導する感じだから破綻しづらいのかな?
おわりに
今回のLoRAでは衣装の一部分だけを再現しやすくるものを作ったけど、これくらいのボリュームならアウター、インナー、ズボン、靴くらいで個別に作ってもいいかもしれないよね。

では今回はこのあたりで