
Google PinpointでスキャンPDFの「表」をCSVに変換する

前回の記事ではGoogle Pinpointを使ってスキャンPDFの文章を読み込み、単語や日付で絞り込む方法を解説しました。
Google Pinpointでは文章だけでなく、表や箇条書きなど何らかの構造を持つ文書を表形式で取得する「構造化データの抽出(Extract Structured Data)」と呼ばれる機能があります。この記事では、前回と同じく日本銀行のスキャンPDF資料から表をCSV形式で抽出する方法を解説します。
サンプルデータの読み込み
まずサンプルデータをダウンロードします。
https://drive.google.com/file/d/1GEhAg86ks6WYC8H3d7L9YV_NdL5DILZK/view
前回と同様に、日本銀行の金融政策決定会合議事録から抜粋したものです。資料内にはいくつかグラフがありますが、スキャンPDFなのでそのままではコピーすることができません。単純にOCRで文字起こしを行っても、表の構造を再現できず数字が羅列されるような形になるはずです。Google Pinpointではこのような表の構造を保持したままCSVファイルに変換することができます。今回は3ページ目にある以下のような表を解析してみます。

ダウンロードしたら前回と同じくPinpointにアクセスします。
ログインして自分のワークスペースを開き、新しいコレクションを新規作成してください。文章と同様に「ドキュメントを追加」からPDFファイルをアップロードします。
ここからが前回と異なる部分です。画面左下の「構造化データを抽出(ベータ版)」というリンクをクリックします。「類似した構造のドキュメントのコレクションをスプレッドシートに変換します」というモーダルウインドウが出るので「使ってみる」をクリックしてください。
ここでも初回の場合は登録画面が出るかもしれません。Pinpointへの初回登録と同様に情報を入力して申請ください。
登録が完了していれば新規タブで以下のような画面に移るので「Process collection」ボタンを押します。
解析を開始すると「Processing collection」という画面に映るのでしばらく待ちます。今回もサンプルファイルのページ数は絞ってあるため、数十秒で完了するはずです。一度ブラウザを閉じても解析は続行されます。完了したら「Annotate collection」ボタンを押します。

表の抽出
「Annotate collection」ボタンを押すと「構造化データの抽出」ページに移ります。中央に大きく読み込んだPDFファイルが見えているはずです。まず画面上部のメニューから「Tables」を選択します。これが表の抽出です。ちなみに右から「キーと値のペア」「繰り返しのセクション」「表」「ヘッダーとフッター」です。

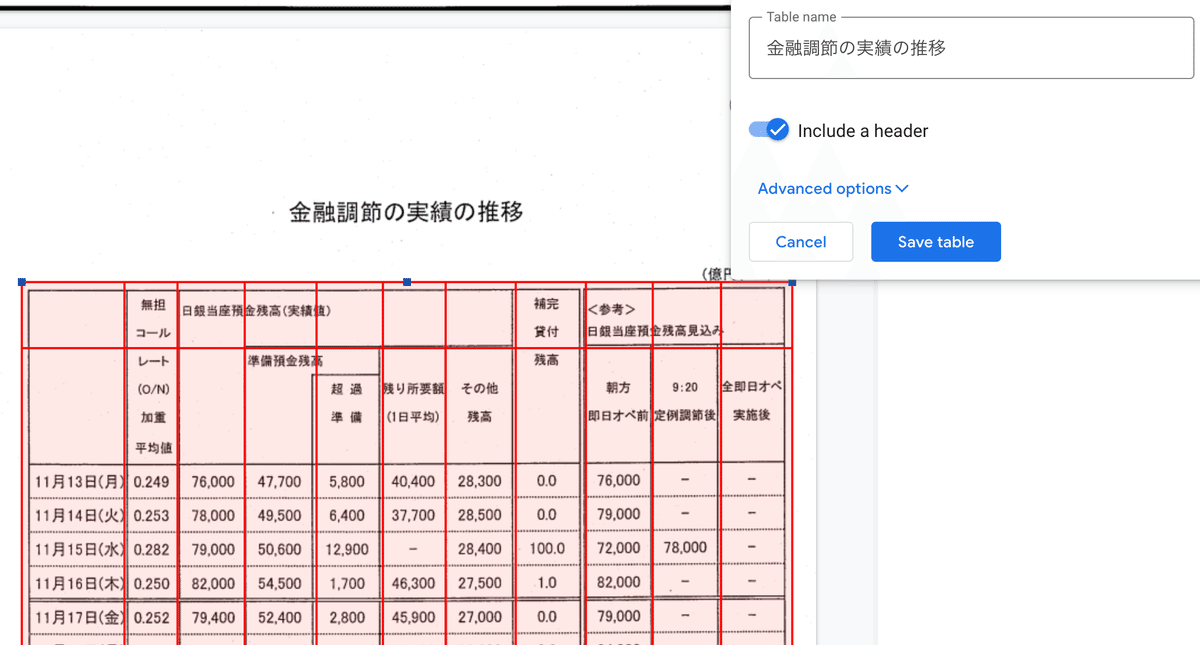
3ページ目に移動すると、表「金融調節の実績の推移」が掲載されています。マウスカーソルが十字型になっていると思うので、解析したい表をドラッグで囲みます。囲むと表の名前を入力する画面が出てくるので、適当な名前を入力してください。Enterキーを押すか「Save table」ボタンを押すと表が保存されます。
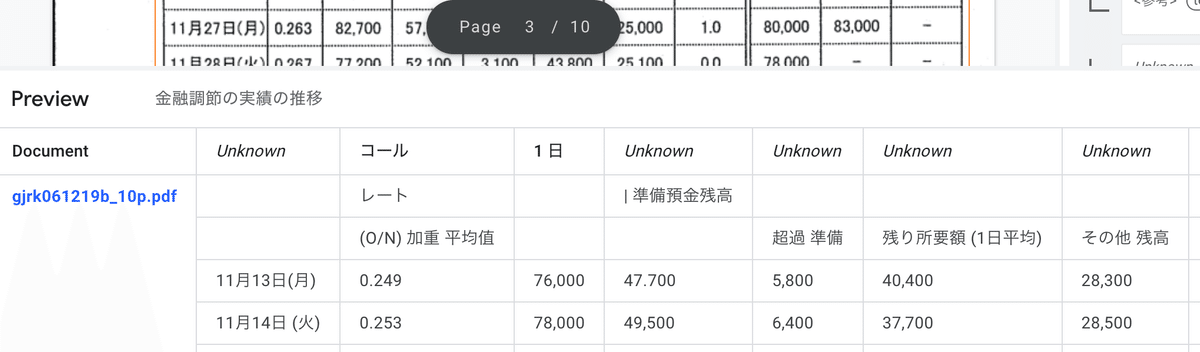
表が保存されると画面下部にプレビューが10行ほど表示されるので、列や行が問題なく読み込まれているか確認します。
問題なければ右上の「Extract」ボタンを押します。「Extraction in progress」というウインドウが出た後「Extraction done」という表示に切り替われば抽出完了です。右下の「Download」ボタンを押すとCSVファイルで表がダウンロードできます。

これが抽出されたCSVファイルです。概ね数字の配置は正しく取得できているかと思います。私が試したところだと、テーブルの構造や数字はかなり正確に取得してくれます。その代わり日本語の細かい文字は読み取れない場合もあったり(たとえば「11月16日(木)」が「11A16B()」になっている)、罫線が文字と認識される場合があるようです。
最も左の列「File Name」はファイル名、画像にはありませんが最も右の列「Validation Link」はPinpointの該当行にすぐ遷移できるリンクです。CSVと原本を引き比べて作業したいときに使います。
うまく抽出できないときは
今回は1度目で概ね正しく表を抽出できましたが、表の構造によってはうまくいかない場合もあります。
次は8ページ目「最近のオペ結果の推移」で同じように抽出を試してみてください(ページ上部のメニューがTablesから自動的にKey/valueに切り替わっていることがあるので注意)。プレビューを見ると複数のセルが同じセル扱いされていることがわかります。
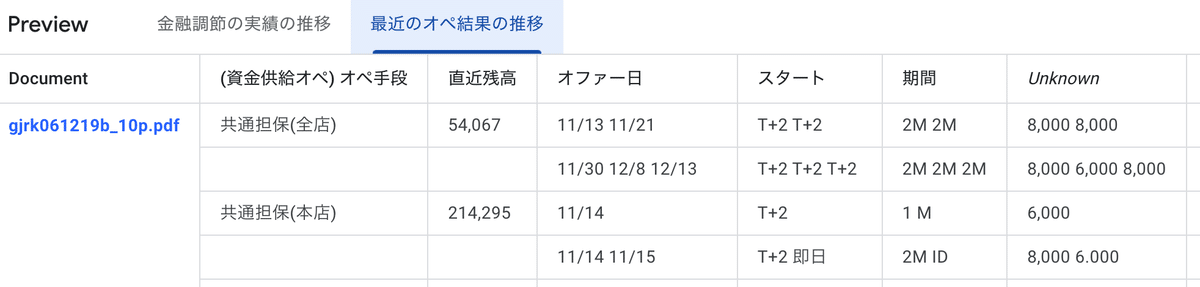
こういう場合は行や列の抽出メソッドを変えます。右側「Fields」をスクロールして「最近のオペ結果の推移」(または自分でつけた表の名前)をクリックし、表示された編集ボタン(鉛筆のアイコン)をクリックします。
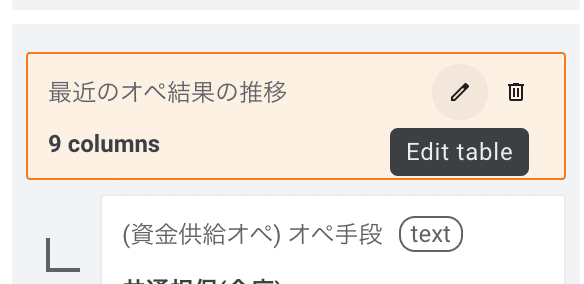
表の名前をつけたウインドウが再び表示されるので、「Advanced options」をクリックしてRowとColumnのBoundary extraction methodを表示させます。これが行と列の抽出メソッド選択オプションです。
Rowは4番目「Each text line in a separate row」、Columnは3番目「White-space analysis (disregard annotations)」に合わせます。それぞれ「改行をすべて1行ずつとして扱う」「余白を基準に列を分ける」という意味です。

「Save table」を押すとプレビューも更新されます。今度は先ほどと異なり、ほぼ正確に行と列が抽出されているはずです。

このようにして行や列の抽出メソッドを変えることで精度が良くなる場合もありますので、うまく抽出できない場合は試してみてください(それぞれのメソッドに意味があるのですが、経験上とりあえずセレクトボックスをポチポチ変えて一番良いものを選ぶ方が早いです)。
Pinpointは縦書きも読める
ちなみにGoogle Pinpointは縦書きの文章も(ある程度)読み込むことができます。以下は新聞記事をスマートフォンで撮影し、Pinpointに読み込ませたものです(実際には1本の記事をすべて読み込ませていますが、下の写真は抜粋です)。せっかくなので私の名前が言及された記事を解析しましたが、紙の折れや影があっても問題なく文字起こしされており、「荻原和樹」もきちんと人名として扱われていました。きちんと行間や解像度が確保されているものであれば、縦書きであっても問題なく読んでくれそうです。

Google News Labでは他にも報道に役立つデジタル技術のワークショップやレクチャーを無償で行っています。オンラインで誰でも参加できる形や、報道機関や大学に訪問して開催する形があります。興味のある方はX(旧Twitter)、Facebook、LinkedInなどからご連絡ください。