ラビットチャレンジ_深層学習day4

Section1:強化学習
1-1:要点
・長期的に報酬を最大化できるように環境の中で行動を選択できる
エージェントを作ることを目標とする機械学習
⇒行動の結果として与えられる利益をもとに、
行動を決定する原理を改善していく仕組み
・強化学習のイメージ

⇒方策と価値を学習するのが強化学習の目的である
方策は報酬がたくさんもらえるように学習する
価値はもっともいい状況を学習する
例:働きやすくてボーナスがたくさんもらえる職場にする方法を学習する
⇒方策と価値の2つが最適になることで強化学習がうまくいく
・探索と利用のトレードオフ
・過去のデータで、ベストとされる行動のみを常に取り続ければ
他にもっとベストな行動を見つけることはできない
⇒探索が足りない
・未知の行動のみを常に取り続ければ、過去の経験が活かせない
⇒利用が足りない
・価値関数
・エージェントが何を目標に価値を決めるのかを表す関数
状態価値関数:ある状態の価値に注目する
行動価値関数:状態と価値を組み合わせた価値に注目する
⇒行動価値関数が最近は注目を集めている
⇒全ての行動を終えたうえで勝てそうか判定する関数
・方策関数
・方策ベースの強化学習手法において、ある状態でどのような行動を
採るのかの確率を与える関数
⇒ある瞬間の1つ1つの行動を決める関数
・方策関数の学習
Θ:重み
t :時間
J :期待収益(NNの誤差関数と同じ意味)
⇒NNでは誤差を小さくするためマイナスだったが
機械学習では期待値を大きくするためにプラスに変化している

期待収益の定義方法

・強化学習の歴史
モデルの手法や当時のコンピュータでは強化学習では難しかった
⇒関数近似法とQ学習を組み合わせる手法が登場したことによって
急速に発展した
Q学習:行動価値関数を、行動する毎に更新することにより学習を
進める方法
関数近似法:価値関数や方策関数を関数近似する手法
Section2:AlphaGo
2-1:要点
・AlphaGo (Lee)の方策関数の作成

・AlphaGo (Lee)の価値関数の作成

・AlphaGo (Lee)の学習手順
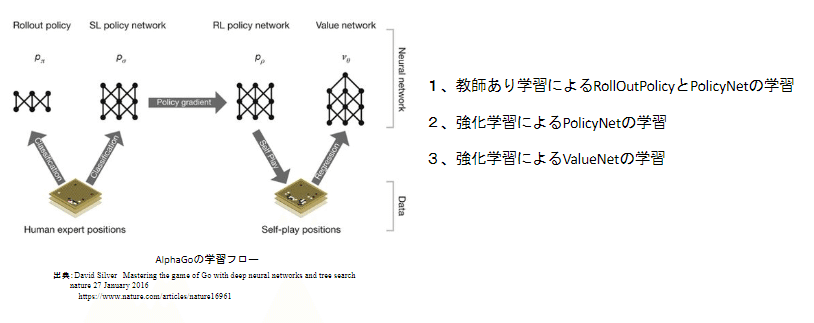
・教師あり学習によるRollOutPolicyとPolicyNetの学習
・棋譜データからPolocyNetを学習する
⇒精度は57%ぐらい
・棋譜データからRollOutPolicyを学習する
⇒精度は24%ぐらい
・RollOutPolicy
・Policy Netよりも精度は落ちるが計算結果が速いネットワーク
⇒Policy Netの1000倍計算速度が速い
・方策関数と学習関数の学習方法
・方策関数(Policy Net)の学習

・価値関数(Value Net)の学習

・AlphaGo Zero
・AlphaGo (Lee)との違い
・教師あり学習を一切行わない
・特徴入力を石の配置のみにした
・PolicyNetとValueNetを1つにした
・Residual Netを導入した
・モンテカルロ木探索からRollOutシミュレーションをなくした

※NNはAlphaGoZeroのように途中で分岐することもできる
AlphaGoZeroでは1つの入力から2つ(方策関数、価値関数)出力する
・Residual Block
・ネットワークにショートカット構造を追加し、勾配の爆発、消失を
抑える効果がある
・ショートカットするパターンとショートカットしないパターンで
異なるネットワークが作成される
⇒メリット:異なるネットワークの学習を行うことができる

・★Residual Networkの派生
⇒E資格は工夫などの問題がよくでるため工夫方法と
説明を覚えておくと試験対策にはなる

・AlphaGoZeroの学習

2-2:異なる資料からの要点
・AlphaGoでは、CNNを用いて4つのニューラルネットワークを学習させる。人間の棋譜の遷移関係を学習させることで1つ次の手を予測し勝ちに繋がりやすい状態を列挙するSL Policy、SL Policyの予測性能を落とす代わりに計算速度を上げたRollout Policy、SL Policyのネットワーク同士の対戦による学習で予測性能を向上させたRL Policy、またある盤面からRL PolicyとRollout Policyのネットワークを用いて勝敗がつくまでゲームを進めこの勝敗をもとに盤面の勝利確率を学習させ、予測するValue Networkを学習する
・黒本では上記の内容が具体的な数式を用いて解説がされている
⇒要チェック!!
Section3:軽量化・高速化技術
3-1:要点
・高速化技術
分散学数では複数の計算資源を使用し、並列的にニューラルネットワー
クを構成することで、効率の良い学習を行う
・モデル並列
・大きなNNの場合に使用する方法
・モデルのパラメータ数が多いほど効果が大きい
・NNの分岐部分などで分割することが現在は多い

・データ並列
・データの並列化には同期型と非同期型がある
・速度では非同期型がいい
⇒非同期型は最新のモデルのパラメータを利用できないため
学習が不安定という問題がある
・現在は同期型と非同期型を使いわけている
⇒同期型:データセンタのPCなど全てのPCが制御できる状態の場合
非同期型:待機中の世界中のPCなどを利用する場合


・GPU
・CPU:高性能なコアが少数 複雑で連続的な処理が得意
・GPU:比較的低性能なコアが多数 並列処理が得意
NNの学習は単純な行列演算が多いので、高層化が可能
⇒NNではGPUを使う!
・GPGPU:元々の使用目的(ゲームの映像をきれいに表示する)で
あるグラフィック以外の用途で使用されるGPUの総称
・GPGPUの開発環境
・CUDA
GPU上で並列コンピューティングを行うためのプラットフォーム
Deep Learningフレームワーク(Tensorflow, Pytorch)内で実装され
ているため、簡単に使用することができる
・軽量化
・量子化
・パラメータの64bit浮動小数点を32bitなど下位の精度に落とすこと
でメモリの演算処理を削減を行う
⇒深層学習では16bitを用いることが多い(64bitでも16bitでも
そこまで精度は変わらないが速度は10倍以上になる)
・メリット:計算の高速化、省メモリ化
・デメリット:精度の低下
・蒸留
・学習済みの精度のモデルの軽量なモデルへ継承させる
・蒸留は教師モデルと生徒モデルの2つで構成する
・教師モデル:予測精度の高い、複雑なモデルやアンサンブル
されたモデル
・生徒モデル:教師モデルをもとに作られる軽量なモデル
・学習方法:
1)教師モデルの重みを固定し生徒モデルの重みを更新する
2)誤差は教師モデルと生徒モデルのそれぞれの誤差を使い重みを
更新する

・プルーニング
・モデルの精度に寄与が少ないニューロンを削減することで
モデルの軽量化、高速化を行う

・深層学習では多くのパラメータを削減することができる

⇒閾値が0.5:パラメータを約半分にしても精度は91%保てる
閾値が2.6:パラメータの99%を削減しても精度は87%保てる
⇒精度は少し下がるが大幅に高速化することが可能
Section4:応用モデル
4-1:要点
・MobileNet(画像認識のネットワーク)
・Depthwise Separable Convolutionという手法を用いて計算量を削減
している。通常の畳込みが空間方向とチャネル方向の計算を同時に
行うのに対して、Depthwise Separable Convolutionではそれらを
Depthwise ConvolutionとPointwise Convolutionと呼ばれる演算によ
って個別に行う
⇒一般的な畳み込みの計算量は多いため計算量を減らす
通常:H × W × K × K × C × M
MobileNet:H × W × C × K × K + H × W × C × M


・Depthwise Convolution
フィルタ数を1に固定することで計算量を減らす
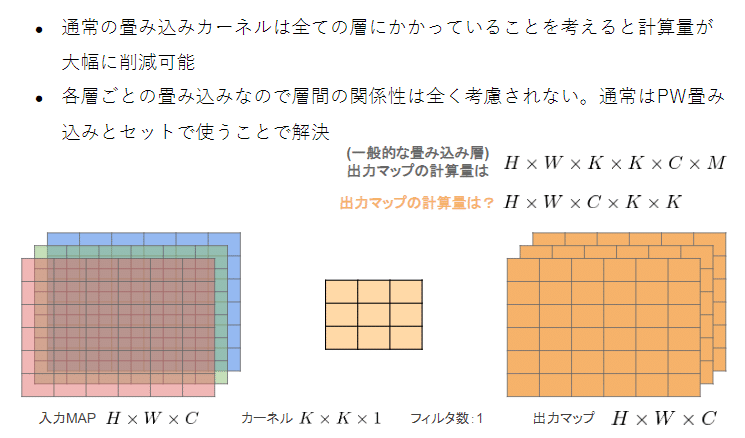
・Pointwise Convolution
カーネルのサイズを1に固定して計算量を減らす

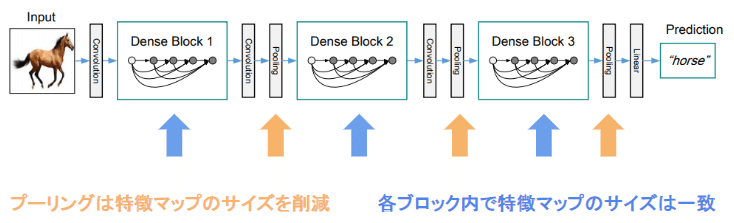
・DenseNet(画像認識のネットワーク)
・層が深くなるほど学習が難しくなる問題への対策
・DenseBlockでは前方の各層からの出力全てが後方の層への入力
として用いられる
・DenseBlockで増えたチャンネルは畳み込みとプーリングで
3チャンネルに戻すことでチャンネル数の増加を防いでいる

・Batch Norm Layer
・レイヤー間を流れるデータの分布をミニバッチ単位で正規化する
・学習時間の短縮や初期値への依存低減、過学習の抑制の効果がある
・問題点:Batch Sizeが小さい条件下では、学習が収束しないことある
代わりにLayer Normalizationなどの正規化手法が使われることがある
・正規化手法↓
Batch Normはミニバッチのサイズに影響を受ける正規化手法である

・Batch Norm

・Layer Norm
⇒Batch Normがミニバッチサイズに影響を受ける問題点を解消したもの
・入力データや重み行列に対して、以下の操作を施しても、
出力が変わらないことが知られている。
・入力データのスケールに関してロバスト
・重み行列のスケールやシフトに関してロバスト

・Instance Norm

・Wave net(音声の生成)
・深層学習を用いて結合確率を学習する際に、効率的に学習が行える
アーキテクチャを提案したことがWaveNet の大きな貢献の1 つであ
る。提案された新しいConvolution 型アーキテクチャは、Dilated
causal convolutionと呼ばれ、結合確率を効率的に学習できるように
なっている。
Dilated causal convolutionを用いた際の大きな利点は、単純な
Convolution layer と比べてパラメータ数に対する受容野が広いこと
である。

Section5:Transformer
5-1:要点
・Encoder-Decoder Model(Seq2seq)
・系列を入力して系列を出力するモデル
・入力系列がEncode(内部状態に変換)され、
内部状態からDecode(系列に変換)する
・実用例:翻訳、音声認識など
・Seq2Seqは、RNNと言語モデルを合わせたモデルとほぼ同じ
下記がRNN×言語モデルの内容

・RNNは系列情報を内部状態に変換することができる
・文章の各単語が現れる際の同時確率は、事後確率で分解できる
⇒事後確率を求めることがRNNの目標になる
・言語モデルを再現するようにRNNの重みが学習されていれば、
ある時点の次の単語を予測することができる
⇒先頭単語を与えれば文章を生成することも可能
・実際のSeq2Seq
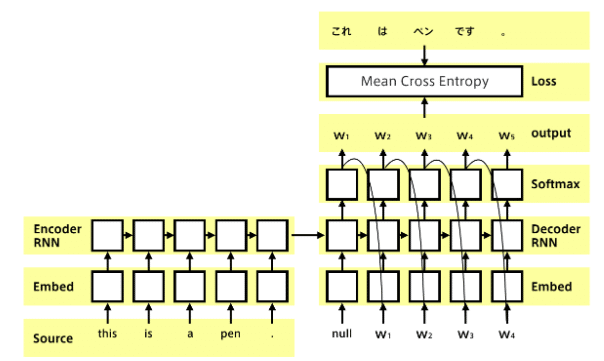
・特徴
・Decoder側の構造は言語モデルRNNとほぼ同じだが 隠れ状態の
初期値にEncder側の内部状態を受け取る
・Decoderのoutput側に正解を当てれば教師あり学習がEnd2end
で行える
5.2.2 Transformer
・Seq2Seqの弱点

・対策としてAttention (注意機構)が開発された

・Attentionを使うと文が長くなっても翻訳精度が落ちない

・Attentionのみを使用するTransformerが開発された
LSTMに次ぐ次世代のユニットと呼ばれている

・全体像

・AttentionにはSelf-Attentionを使用している
特徴:ある文章が与えられたときにどの情報に注目するかを
自分の入力のみで決める

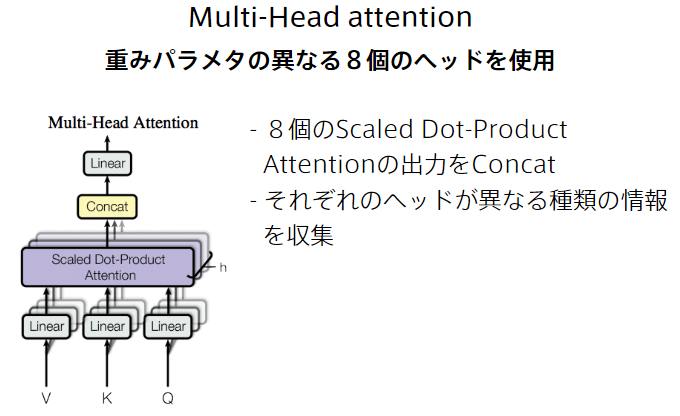
・Multi-Head attentionの中で行うScaled dot product attention

・Multi-Head attention
8つにユニットを分けている理由:
・8つが独自に学習することで特徴をとらえやすくなる
⇒イメージはアンサンブル学習
・Decoder

・Add & Norm

・Position Encoding

5-2:実装演習
5.2.1 Seq2Seqで翻訳を行うモデルを実行してみる
※プログラムは下記のファイルを参照
・lecture_chap1_exercise_public.ipynb
・訓練結果
・評価にはBLEUを使用している
BLEUの値が徐々に上がっているため学習はできていそう
⇒BLEUは40を超えてくると高品質と言われている

・生成
・思っていたよりは、ちゃんとした文が生成されている
⇒BLEUが18ぐらいだと主旨を理解できないと言われている

・もう1回生成してみる
⇒主旨が分からない文が生成された
文によっては、いい感じに生成されることもあるが何回も
生成していくと確かに主旨が理解できない文が多くあった

5.2.2 Transformerで翻訳を行うモデルを実行してみる
※プログラムは下記のファイルを参照
・lecture_chap2_exercise_public.ipynb
・訓練結果
・RNNを使ったSeq2Seqに比べるBLEUの値が高くなっている

・生成
・BLEUの値が上がった割には微妙な結果
⇒学習データが足りないと思うが、やはりBLEUで評価する
場合は、40ぐらいを目標にしないと翻訳としては使えなさそう




・BLEUの値
![]()
5-3:確認問題
1.Q

1.A 1回誤差が生まれると連鎖的に誤差が増えていく
⇒RNNでは、時刻 t の出力を時刻 t+1 の入力とすることができる
が、この方法でDecoderを学習させると連鎖的に誤差が大きく
なっていき、学習が不安定になったり収束が遅くなったりする
問題が発生します。
2.Q

2.A 学習では答えが与えられるため学習が進むが、テストでは答えが
与えられなくなるため、うまく学習ができなくなる
⇒問題1,2のモデルにはそれぞれにデメリットがあるため2つを確率的に
まぜて使用することで、学習を行う必要がある
Section6:物体検知・セグメンテーション
6-1:要点
・分類、物体検知、意味領域分割、個体領域分割のイメージ
タスクの難易度は下にいくにつれて難しくなる
以下では、物体検知と意味領域分割についてまとめる

・物体検出
・物体検出のイメージ

・物体検出で使用する代表的データセット
⇒データセットは、同じデータを使って精度を検証することで
異なるアルゴリズムの精度を比較することができる

・Instance Annotation:物体個々にラベリングがされている
・Box/画像:1枚の画像の中にある物体の数
ILSVRC17ではアイコンのような画像のため非日常である
⇒最終的にやりたいことによって使うデータセットを変える
例:最終的にアイコンの画像を判別したい⇒ILSVRC17
日常的な風景から物体を検出したい⇒MS COCO18やOICOD18


⇒ある程度の精度が出たため終了した



⇒処理上データセットの画像サイズは大事な情報であるため
知っておくと良い
・分類の評価指標
Recall = 再現率 Precision = 適合率

・分類と物体検出の評価の違い
Threshold = 閾値

⇒クラス分類では閾値に関係なくBounding Boxは6つになるが、
物体検出では閾値によってBounding Boxが変化する
⇒物体検出では閾値以上の自信をもって判定できた物体のみ出力する
・物体検出においての物体一の予測精度

⇒よくある間違い:IoUが0.8だから80%物体位置を予測できている
⇒この解釈は違う為注意
例)1枚の画像でみる物体検出

⇒P1で既に人を検出している場合はP5はFPになる
⇒confの高い方をTPとしてconfの低い方をFPとする
例)複数の画像でみる物体検出
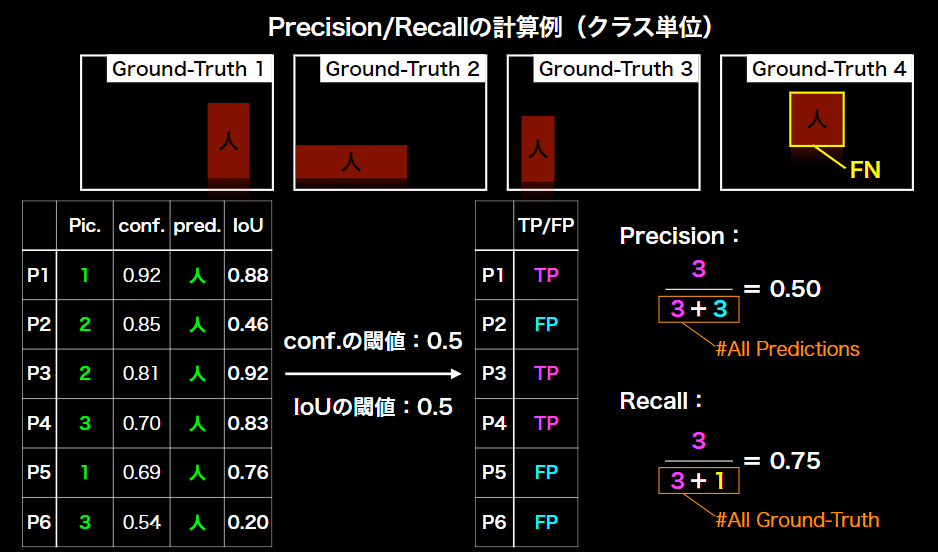
⇒Recallの+1はPic4の人を検出できていないためそれがFNとなる
・AP:Average Precision
IoUを固定してconfの閾値を変化させたときのPrecision、Recallを
計算してPR曲線を作成する

・mAP:mean Average Precision
Average Presicionは上の図ではクラスを人で固定していた
クラスがたくさんある場合(人、車、犬など)はその平均を算出する
※おまけのMS COCO
IoUの閾値を変化させてAP、mAPを計算する方法
IoUを変化させるということは、物体の位置についてより厳しく
見ていきたいときに使用する

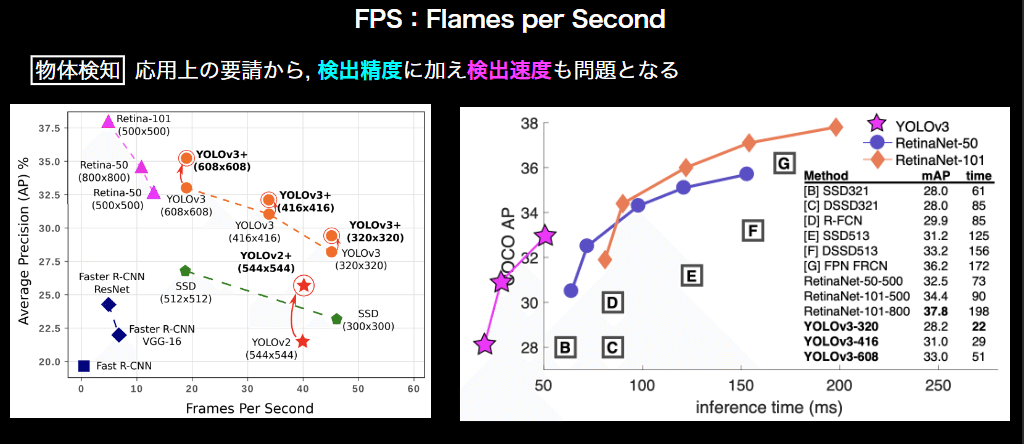
・速度面の評価
物体検出は速度も必要になってくるためFPS(1秒間に推論できる
フレーム数)などを用いて速度も指標に入れる必要がある
※FPSではなく、infrence time(1フレームの推論に何秒かかったか)
を使用することもある
・物体検知の大枠
・物体検出のフレームワークの歴史
物体検出のもとになったフレームワークなど全体的な流れは、
知っておいた方がいいい

・1段階検出と2段階検出の比較

・SSD
・1度のCNN演算で物体の「領域候補検出」、「クラス分類」の
の両方を行って、物体検出処理の高速化を可能にしています。


・特徴マップからの出力
・出力サイズ k(#Class + 4)m
k : マップ中の各特徴量にk個のDefault Boxを用意
mn : 特徴マップのサイズがm×n
数字: オフセット項

・特徴マップのサイズが小さくなると1枚の画像の中の大きなものを
検出しようとしている

・多数のDefault Boxを用意したことで生ずる問題への対処として
・ Non-Maximum Suppression
⇒IoUを計算して対処する方法
・ Hard Negative Mining
⇒背景と非背景の比を1:3に変更することで対処する方法

・SSDを実装する際の損失関数

・Semantic Segmentation
・画像認識、物体検出の問題点:
・層が深くなると解像度が落ちていく
・入力画像と同じ改造に戻すことをUp-samplingという
⇒Up-sampingのようなめんどうな処理をなくしたい!
⇒ならPoolingしなければいい...
でも受容野を広げるためにPoolingは必須

・基本アイディアとしてFCN(Fully Convolutional Network)があり、
全結合層を持たず、ネットワークが畳み込み層のみで構成されてお
り、クラス分類の結果がヒートマップとして出力されるようになる


・しかし輪郭がぼやけるため輪郭の情報を補完する

・U-Net
・低レイヤー(Pooling前)の情報を伝達する方法
・ 画像全体のクラス分類(MNISTなど)からFCNとdeconvolution
を使い、物体の位置情報を出力できるようになった
・ skip-conectionを用いて畳み込みによって失われる位置情報を
保持しておくと、より精密な領域を出力できる

・Dilated Convolution
本来7層の畳み込みでやっていた特徴抽出を3層でできる

おまけ:GAN
・生成器と識別器を競わせて学習する生成&識別モデル
・Generator:乱数からデータを生成
・Discriminator:入力データが真データであるかを識別

・2プレイヤーのミニマックスゲーム
式の意味:Discriminatorが最大化し、Generatorで最小化する
E:期待値を採るための操作


・最適化(勾配降下法)
・GeneratorとDiscriminatorの最適化をペアと考えて学習を行う


・DCGAN
GANを利用した画像生成モデル


この記事が気に入ったらサポートをしてみませんか?