ラビットチャレンジ_深層学習day1

ニューラルネットワークの全体像
確認テスト1:
Q.ディープラーニングは、結局何をやろうとしているのか?
A.ニューラルネットワークを用いて入力値から目的とする出力値に変換
するための数学モデルを構築すること。
Q.どの値の最適化が最終目的か?
A.重み[w] バイアス[b]
確認テスト2:
Q.入力層:2ノート1層 中間層:3ノード2層 出力層:1ノード1層
A.

Section1:入力層~中間層
・何かしらの値xを入力し、重みwとバイアスbを加えて総入力uを算出する
(中間層はこのuを受け取り活性化関数を通して出力層に渡す)
u = w1x1 + w2x2 + w3x3 + b
=Wx + b ...①
実装演習:
単層・単ユニット:
・重みとバイアスをランダムにして入力層を出力する
・活性化関数にReLU関数を用いて中間層を出力する
# 順伝播(単層・単ユニット)
## 試してみよう_配列の初期化
#W = np.zeros(2)
#W = np.ones(2)
W = np.random.rand(2)
#W = np.random.randint(5, size=(2))
print_vec("重み", W)
## 試してみよう_数値の初期化
b = np.random.rand() # 0~1のランダム数値
#b = np.random.rand() * 10 -5 # -5~5のランダム数値
print_vec("バイアス", b)
# 入力値
x = np.array([2, 3])
print_vec("入力", x)
# 総入力
u = np.dot(x, W) + b
print_vec("総入力", u)
# 中間層出力
z = functions.relu(u)
print_vec("中間層出力", z)
単層・複数ユニット:
・重みをランダムに生成し入力層を出力する
・重みを3*4で生成することで中間層のノードが3つになる(複数ユニット)
・活性化関数にシグモイド関数を用いて中間層を出力する
# 順伝播(単層・複数ユニット)
# 重み
## 試してみよう_配列の初期化
#W = np.zeros((4,3))
#W = np.ones((4,3))
W = np.random.rand(4,3)
#W = np.random.randint(5, size=(4,3))
print_vec("重み", W)
# バイアス
b = np.array([0.1, 0.2, 0.3])
print_vec("バイアス", b)
# 入力値
# 入力値と重みの配列の形が計算できる形か確かめることが大切
x = np.array([1.0, 5.0, 2.0, -1.0])
print_vec("入力", x)
# 総入力
u = np.dot(x, W) + b
print_vec("総入力", u)
# 中間層出力
z = functions.sigmoid(u)
print_vec("中間層出力", z)
3層・複数ユニット:
・重み、バイアスを3つ準備し、入力層⇒中間層1⇒中間層2⇒出力層を
作成する
・活性化関数にReLu関数を用いて中間層を出力する
・疑問:・講義では中間層が1つと言っていた。中間層は2つではない?
・結果の出力の「出力1」と「出力合計」に「z1」の結果を
出力している理由はなに?
# 順伝播(3層・複数ユニット)
# ウェイトとバイアスを設定
# ネートワークを作成
def init_network():
print("##### ネットワークの初期化 #####")
network = {}
#試してみよう
#_各パラメータのshapeを表示
#_ネットワークの初期値ランダム生成
network['W1'] = np.array([
[0.1, 0.3, 0.5],
[0.2, 0.4, 0.6]
])
network['W2'] = np.array([
[0.1, 0.4],
[0.2, 0.5],
[0.3, 0.6]
])
network['W3'] = np.array([
[0.1, 0.3],
[0.2, 0.4]
])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['b2'] = np.array([0.1, 0.2])
network['b3'] = np.array([1, 2])
print_vec("重み1", network['W1'] )
print_vec("重み2", network['W2'] )
print_vec("重み3", network['W3'] )
print_vec("バイアス1", network['b1'] )
print_vec("バイアス2", network['b2'] )
print_vec("バイアス3", network['b3'] )
return network
# プロセスを作成
# x:入力値
def forward(network, x):
print("##### 順伝播開始 #####")
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# 1層の総入力
u1 = np.dot(x, W1) + b1
# 1層の総出力
z1 = functions.relu(u1)
# 2層の総入力
u2 = np.dot(z1, W2) + b2
# 2層の総出力
z2 = functions.relu(u2)
# 出力層の総入力
u3 = np.dot(z2, W3) + b3
# 出力層の総出力
y = u3
print_vec("総入力1", u1)
print_vec("中間層出力1", z1)
print_vec("総入力2", u2)
print_vec("出力1", z1)
print("出力合計: " + str(np.sum(z1)))
return y, z1, z2
# 入力値
x = np.array([1., 2.])
print_vec("入力", x)
# ネットワークの初期化
network = init_network()
y, z1, z2 = forward(network, x)
確認テスト1:図に動物分類の実例を入れてみる
確認テスト2:式①をPythonで書け
u = np.dot(x , W) + b確認テスト3:1-1のファイルから中間層の出力を定義しているソースを抜き出せ

u2 = np.dot(z1,W2) + b2 で中間層の値を算出
z2 = functions.relu(u2)で中間層の出力を行っている
Section2:活性化関数
活性化関数:ニューラルネットワークにおいて、次の層への出力の大きさ
を決める非線形の関数
活性化関数の例
・中間層用の活性化関数
・ステップ関数 (現在ほとんど使われない)

・シグモイド関数
・ニューラルネットワークが発展したときに使われていた
・微分が可能で最適化ができる関数

・ReLu関数
・シグモイド関数の課題の「勾配消失問題」を解決できる

実装演習:
ステップ関数:
# ステップ関数(閾値0)
def step_function(x):
return np.where( x > 0, 1, 0) シグモイド関数:
# シグモイド関数(ロジスティック関数)
def sigmoid(x):
return 1/(1 + np.exp(-x))ReLu関数:
# ReLU関数
def relu(x):
return np.maximum(0, x) 確認テスト1:線形と非線形の違いを簡易に説明せよ。
線形:比例の式で表現ができる 例:y = ax + b
非線形:比例の式では表現ができないもの 例:y = ax^2 + bx^3
A.線形な関数は、加法性、斉次性を満たすもの
加法性:f(x+y) = f(x) + f(y)
斉次性:f(kx) = kf(x)
確認テスト2:配布されたソースコードより該当する箇所を抜き出せ。
1_1_forward_propagation.ipynb 順伝播(3層 複数ユニット)から
活性化関数を抜き出せ
# ReLU関数
def relu(x):
return np.maximum(0, x)
# 2層の総出力
z2 = functions.relu(u2)Section3:出力層
・出力層の役割:人間が欲しいデータを出力する(分類した確率など)
・誤差関数:出力と訓練データの誤差を算出する関数 例:二乗和誤差
⇒誤差関数は解く問題によって使い分ける
・分類問題:クロスエントロピー誤差
・回帰問題:平均二乗和誤差
・出力層の活性化関数:
・出力層と中間層の活性化関数の違い
「目的」
・中間層:入力された値の特徴を抽出する
・出力層:人間が扱いやすい形に変換する
「値の強弱」
・中間層:閾値の前後で信号の強弱を調整
・出力層:信号の大きさはそのままに変換
「確率出力」
・分類問題の場合、出力層の出力は0~1の範囲に限定し、
総和を1とする必要がある
・出力層の活性化関数の例:★★重要★★
⇒解きたい問題によって使うものは決まっている
※二乗誤差は実際は平均二乗和誤差を使用することが多い

実装演習:
・平均二乗和誤差
# 誤差関数
# 平均二乗誤差
def mean_squared_error(d, y):
return np.mean(np.square(d - y)) / 2
# 誤差
loss = functions.mean_squared_error(d, y)・クロスエントロピー誤差
# クロスエントロピー
def cross_entropy_error(d, y):
if y.ndim == 1:
d = d.reshape(1, d.size)
y = y.reshape(1, y.size)
# 誤差
loss = functions.cross_entropy_error(d, y)・多クラス分類(2-3-4ネットワーク)を3-5-4ネットワークに変更する
# 多クラス分類
# 2-3-4ネットワーク
# !試してみよう_ノードの構成を 3-5-4 に変更してみよう
# ウェイトとバイアスを設定
# ネートワークを作成
def init_network():
print("##### ネットワークの初期化 #####")
#試してみよう
#_各パラメータのshapeを表示
#_ネットワークの初期値ランダム生成
network = {}
network['W1'] = np.array([
[0.1, 0.3, 0.5 ,0.6 ,0.7],
[0.2, 0.4, 0.5 ,0.6 ,0.7],
[0.3, 0.5, 0.6 ,0.7 ,0.9]
])
network['W2'] = np.array([
[0.1, 0.4, 0.7, 1.0],
[0.2, 0.5, 0.8, 1.1],
[0.3, 0.6, 0.9, 1.2],
[0.4, 0.7, 0.8, 0.9],
[0.5, 0.8, 0.9, 1.0]
])
network['b1'] = np.array([0.1, 0.2, 0.3, 0.4 , 0.5])
network['b2'] = np.array([0.1, 0.2, 0.3, 0.4])
print_vec("重み1", network['W1'] )
print_vec("重み2", network['W2'] )
print_vec("バイアス1", network['b1'] )
print_vec("バイアス2", network['b2'] )
return network
# プロセスを作成
# x:入力値
def forward(network, x):
print("##### 順伝播開始 #####")
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 1層の総入力
u1 = np.dot(x, W1) + b1
# 1層の総出力
z1 = functions.relu(u1)
# 2層の総入力
u2 = np.dot(z1, W2) + b2
# 出力値
y = functions.softmax(u2)
print_vec("総入力1", u1)
print_vec("中間層出力1", z1)
print_vec("総入力2", u2)
print_vec("出力1", y)
print("出力合計: " + str(np.sum(y)))
return y, z1
## 事前データ
# 入力値
x = np.array([1., 2., 3.])
# 目標出力
d = np.array([0, 0, 0, 1])
# ネットワークの初期化
network = init_network()
# 出力
y, z1 = forward(network, x)
# 誤差
loss = functions.cross_entropy_error(d, y)
## 表示
print("\n##### 結果表示 #####")
print_vec("出力", y)
print_vec("訓練データ", d)
print_vec("誤差", loss)
確認テスト1:

二乗する理由:引き算をした際にマイナスとプラスの値が出力されるため、符号の異なるものを足し合わせると誤差が分からなくなってしまう。つまり、二乗する理由は符号を揃えるため
1/2の意味:微分した際に計算式を簡単にするために便宜上つけているもの
確認テスト2:

# ソフトマックス関数
def softmax(x): # 関数の定義
if x.ndim == 2: # ミニバッチ用の条件
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # オーバーフロー対策 ←プログラムを安定させるおまじない
return np.exp(x) / np.sum(np.exp(x)) # 問題の答え確認テスト3:

# クロスエントロピー
def cross_entropy_error(d, y): # 関数の定義
if y.ndim == 1: #ミニバッチ用の条件
d = d.reshape(1, d.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if d.size == y.size:
d = d.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size #問題の答え※ 「+ 1e-7」は対数関数は0に近づくと-∞に陥るためその場合は
とても小さい値としてあげるために足す
「batch_sixe」はミニバッチの何番目かを示す
Section4:勾配降下法
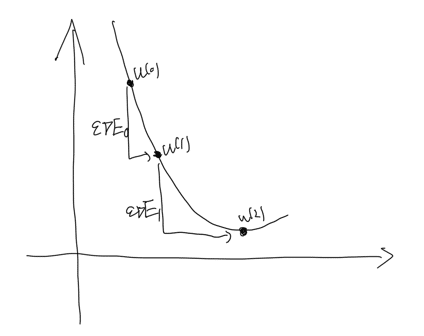
・勾配降下法は深層学習で重みなどのパラメータの最適解を探索するアルゴリズムのこと

・εは学習率と呼ばれるハイパーパラメータである
・学習率が適切でない場合は、局所最適解に陥ることがある
・ある次元から見れば極小でも別の次元から見ると極大になってしまう点のことを鞍点という
⇒鞍点に一度陥ると抜け出すことが困難でこの状態のことを
プラトーという
⇒鞍点問題に対しては、モーメンタムやAdam、AMSBoundなどが
対策方法として開発されている
・式のtのことをイテレーションと呼ぶ(何回繰り返し計算を行ったか)
・確率的勾配降下法(SGD)
・勾配降下法の1つの手法で、ランダムに抽出したサンプルの誤差で
最適解を探索する
・メリット:局所最適化に収束するリスクの軽減
オンライン学習ができる

・ミニバッチ勾配降下法
・勾配降下法の1つの手法で、ランダムに分割したデータの集合Dに属する
サンプルの平均誤差で最適解を探索する
・一般的に用いられる手法
・メリット:
・確率的勾配法のメリットを損なわず、計算機の計算資源を
有効利用できる
⇒CPUを利用したスレッド並列化やGPUを利用したSIMD並列化
※SIMD:1つの命令を複数のデータに対して行ってね

実装演習:
# サンプルとする関数
#yの値を予想するAI
def f(x):
y = 3 * x[0] + 2 * x[1]
return y
# 初期設定
def init_network():
# print("##### ネットワークの初期化 #####")
network = {}
nodesNum = 10
network['W1'] = np.random.randn(2, nodesNum)
network['W2'] = np.random.randn(nodesNum)
network['b1'] = np.random.randn(nodesNum)
network['b2'] = np.random.randn()
# print_vec("重み1", network['W1'])
# print_vec("重み2", network['W2'])
# print_vec("バイアス1", network['b1'])
# print_vec("バイアス2", network['b2'])
return network
# 順伝播
def forward(network, x):
# print("##### 順伝播開始 #####")
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
u1 = np.dot(x, W1) + b1
z1 = functions.relu(u1)
## 試してみよう
#z1 = functions.sigmoid(u1)
u2 = np.dot(z1, W2) + b2
y = u2
# print_vec("総入力1", u1)
# print_vec("中間層出力1", z1)
# print_vec("総入力2", u2)
# print_vec("出力1", y)
# print("出力合計: " + str(np.sum(y)))
return z1, y
# 誤差逆伝播
def backward(x, d, z1, y):
# print("\n##### 誤差逆伝播開始 #####")
grad = {}
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 出力層でのデルタ
delta2 = functions.d_mean_squared_error(d, y)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ
#delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
## 試してみよう
delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)
delta1 = delta1[np.newaxis, :]
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
x = x[np.newaxis, :]
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
# print_vec("偏微分_重み1", grad["W1"])
# print_vec("偏微分_重み2", grad["W2"])
# print_vec("偏微分_バイアス1", grad["b1"])
# print_vec("偏微分_バイアス2", grad["b2"])
return grad
# サンプルデータを作成
data_sets_size = 100000
data_sets = [0 for i in range(data_sets_size)]
for i in range(data_sets_size):
data_sets[i] = {}
# ランダムな値を設定
data_sets[i]['x'] = np.random.rand(2)
## 試してみよう_入力値の設定
# data_sets[i]['x'] = np.random.rand(2) * 10 -5 # -5〜5のランダム数値
# 目標出力を設定
data_sets[i]['d'] = f(data_sets[i]['x'])
losses = []
# 学習率
learning_rate = 0.07
# 抽出数
epoch = 1000
# パラメータの初期化
network = init_network()
# データのランダム抽出
random_datasets = np.random.choice(data_sets, epoch)
# 勾配降下の繰り返し
for dataset in random_datasets:
x, d = dataset['x'], dataset['d']
z1, y = forward(network, x)
grad = backward(x, d, z1, y)
# パラメータに勾配適用
for key in ('W1', 'W2', 'b1', 'b2'):
network[key] -= learning_rate * grad[key] #★★計算★★
# 誤差
loss = functions.mean_squared_error(d, y)
losses.append(loss)
print("##### 結果表示 #####")
lists = range(epoch)
plt.plot(lists, losses, '.')
# グラフの表示
plt.show()
誤差が小さくなっていることが確認できる
・確認テスト1:オンライン学習とは何か2行でまとめよ
オンライン学習とは、学習でデータを小分けに入力してその都度パラメータの更新を行う学習方法。対照的なバッチ学習では、1度に全てのデータを読み込み学習を行う。
※補足:深層学習では基本的にメモリの観点からオンライン学習を行う
・確認テスト2

Section5:誤差逆伝番法
・勾配降下法では重みそれぞれに対して順伝播の計算を繰り返し行うため負荷がかかる
⇒誤差逆伝播法ではこの計算の負荷を減らすことができる
・誤差逆伝播法とは、算出された誤差を出力層側から順に微分し、前の層前の層へと伝播する。最小限の計算で各パラメータでの微分値を解析的に計算する手法。
⇒計算結果から微分を逆算することで、不要な再帰的計算を避けて微分を算出できる
実装演習:
上記の「勾配降下法」で確認済み
・確認テスト1:

# 出力層でのデルタ
delta2 = functions.d_mean_squared_error(d, y)
# 中間層でのデルタ
delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)確認テスト2

delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)grad['W1'] = np.dot(x.T, delta1)