DeepSeek-R1誕生の仕組みを解説:強化学習を増やしSFTを最小にする

1. なぜ誕生の仕組みを解説するのか?
大規模言語モデル(LLM)の発展は急速に進み、特に推論能力を向上させるための研究が活発に行われている。DeepSeekが蒸留を使用している点は別に述べたので本稿では、DeepSeek-R1の誕生プロセスについて詳細に解説する。教師ありファインチューニング(SFT)と強化学習(RL)を融合した独自の学習手法、さらには中間推論モデル「R1-Zero」の役割について解説する。
2. モデルの全体構造
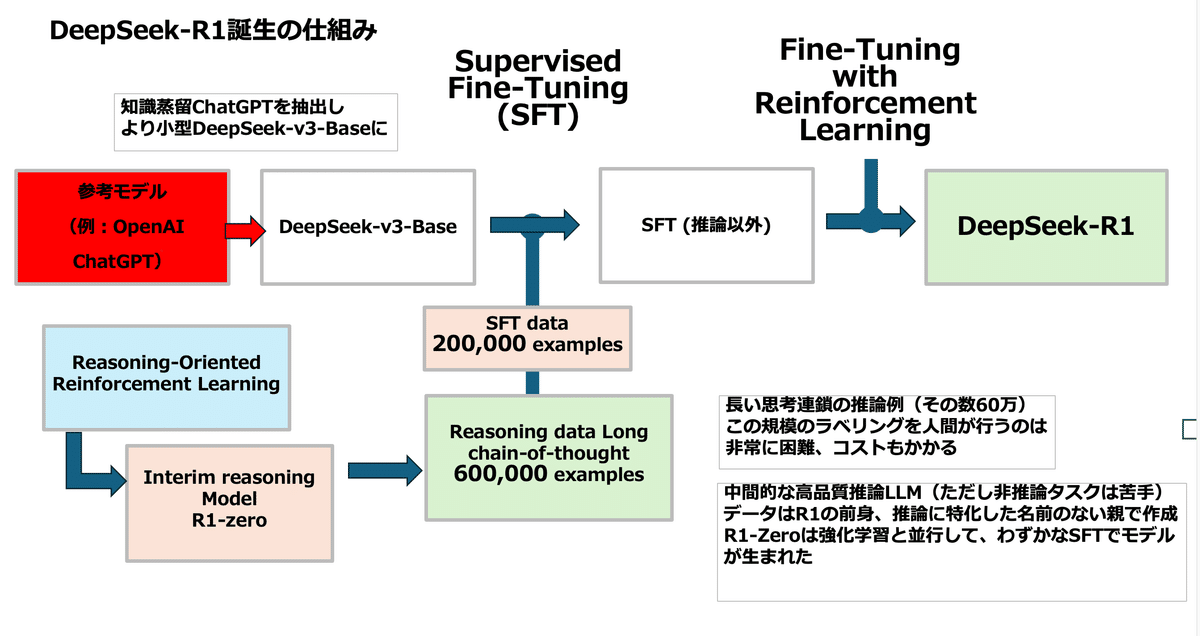
DeepSeek-R1の開発は、以下の3つの主要なステップを通じて行われた。
教師ありファインチューニング(SFT)
ベースモデルであるDeepSeek-v3-Baseを使用。
約 200,000件 のSFTデータを学習。
長い思考連鎖に基づいた 600,000件 の推論データを適用。
中間推論モデル(R1-Zero)の導入
「Reasoning-Oriented Reinforcement Learning(推論指向の強化学習)」を適用。
事前に作成された高品質な推論モデル「R1-Zero」を活用し、SFTデータを補完。
この段階で、通常のSFTではカバーしきれない推論能力を強化。


強化学習(RL)による微調整
R1-Zeroの出力を基に、SFTデータを拡張。
強化学習を適用し、最終的なDeepSeek-R1を形成。
推論タスクと非推論タスクのバランスを最適化。
#3 . 教師ありファインチューニング(SFT)
3.1 SFTのデータ設計
DeepSeek-R1の学習には、大量のSFTデータが不可欠である。本研究では、特に推論に関連するデータセットを重点的に収集し、以下の2種類のデータを利用した。
一般的なSFTデータ(200,000例)
通常の自然言語処理タスク(QA、翻訳、要約など)を含む。
長い思考連鎖データ(600,000例)
数学や論理的推論に特化したデータセット。
人間がラベル付けを行うにはコストがかかるため、自動生成手法を併用。

4. 中間推論モデル(R1-Zero)の役割
4.1 R1-Zeroとは何か?
R1-Zeroは、DeepSeek-R1の前身であり、推論に特化した中間モデルである。このモデルは、強化学習によるトレーニングを経て、少ないSFTデータでも高品質な推論能力を発揮することができる。
4.2 R1-Zeroの学習手法
R1-Zeroのトレーニングは、通常のSFTを経ずに、直接 強化学習(RL) を適用する点が特徴的である。
SFTデータを持たずに推論能力を向上
推論タスクの自動検証を実施
例:「数値のリストを受け取り、ソートされた順序で返すPythonコードを書きなさい」
LLMが生成したコードを 自動実行し、正答率を計測
間違った解答はフィルタリングし、学習データとして再利用
5. 強化学習(RL)による最終調整
5.1 RLを適用する理由
DeepSeek-R1の開発において、RLは2つの目的で使用された。
R1-Zeroの学習
SFTデータなしで推論能力を強化。
DeepSeek-R1の最適化
R1-Zeroの出力を用いたSFTデータを作成し、さらに強化学習で微調整。
5.2 推論タスクの評価方法
推論タスクの評価には、以下のアプローチを採用。
コードの実行結果を自動評価
ユニットテストを生成し、結果の正確性を測定
実行時間の測定による最適解の選択
DeepSeek-R1は従来のSFTモデルよりも推論能力を高めることに成功した。
6. DeepSeek-R1のモデルアーキテクチャ
6.1 アーキテクチャの概要
DeepSeek-R1は、Transformerベースのモデルであり、以下の特徴を持つ。
61層のデコーダーブロック
エキスパート混合レイヤー(Mixture of Experts, MoE)
高品質トークン(14.8兆トークン)による事前学習
推論特化のトークン生成プロセス
7. 結論
DeepSeek-R1の開発プロセスについて詳細に述べた。特に、中間推論モデル(R1-Zero)を活用し、SFTと強化学習を組み合わせた新しい学習アプローチ は、従来のLLMとは異なる点である。
本研究の重要なポイントは以下の通り:
SFT + 推論特化データ(600,000例)を組み合わせた学習
R1-Zeroによる推論能力の事前強化
強化学習による最終的なモデルの最適化
これらの手法によって、DeepSeek-R1は従来の言語モデルを超えた高精度な推論能力を実現した。
8. 参考文献
DeepSeek-V3 技術レポート
DeepSeekMoE: Mixture of Expertsに関する研究
Open R1: Hugging FaceにおけるオープンソースLLM
RLHF(Reinforcement Learning from Human Feedback)関連論文
Hands-On Large Language Models(O'Reilly)