
LLM のニューロンを可視化し理解する Gemma Scope のススメ

LLM(に限らず NN の多く)は便利だが時にブラックボックス過ぎるキライがある。Google が発表した Gemma Scope は Google の LLM「Gemma」の内部ニューロンを可視化し分析することのできるオモシロツールである。
公式が Colab を用意しているため触ってみた備忘録。
LLM の内部を理解する Mechanistic Interpretability(機械論的解釈可能性)
Mechanistic Interpretability(機械論的解釈可能性)。唐突に難しい言葉だが、Gemma Scope 含めた LLM 内部挙動の理解を試みる領域を指す言葉なので触れておく。
深層学習モデルのブラックボックスを明らかにしようとする「機械論的解釈可能性」(Mechanistic Interpretability) の研究が注目されています。
機械論的解釈可能性の目標は、「AIモデルをリバースエンジニアリングすること」と説明されます。
機械論的解釈可能性では LLM 内部挙動をどうにかして分析しようとするわけだが、その方法はいくつかあり、近年トレンドなのは LLM 中間レイヤ出力をスパースオートエンコーダー(以降、SAE)に与え特徴を取り出す手法。
少し前に Anthropic が発表した「自身をゴールデンゲートブリッジと誤認する LLM」や OpenAI の GPT-4 の内部分析、それから今回の Gemma Scope も全て SAE を用いた手法が取られている。
SAE を用いて LLM を分析する
ざっくりとした流れは以下の通りである(Anthropic の事例の場合)。
① 学習済みの LLM を準備する(Claude 3 Sonnet)
② LLM の中間レイヤ出力で 1 層の SAE を学習する
③ 学習後、LLM へ入力して得られる SAE の中間層ベクトルの各次元が「概念」を表すようになる
同系統の入力(プロンプト)にやたら反応する隠れ層ベクトルの次元があったとして、例えばそれがゴールデンゲートブリッジに関する話題なのであれば、その次元は「ゴールデンゲートブリッジ」概念を指していると解釈するイメージ
実装上は反応したプロンプト群を LLM に食わせてサマライズ(概念抽出)しているっぽい
上記 ①〜③ を通して LLM が体得した「概念」を分析したり可視化することが可能。面白いのがここからで、SAE のゴールデンゲートブリッジ概念部分が強まるように LLM の重みを置き換えるとゴールデンゲートブリッジの話題ばかり話したり、自身をゴールデンゲートブリッジと誤認するようになる。

Gemma Scope では Gemma の各レイヤに対して学習済みの SAE が準備されており、入力プロンプトに対し Gemma がどのような概念を想起したかを分析することができる。
Gemma Scope を触ってみる
Gemma Scope は前述の通り Colab が用意されているので上から下まで眺めるだけでも勉強になる。触っている中で気になった部分をいくつかメモ。
Gemma Scope 同様に LLM を分析するためのツールとして SAELens や TransformerLens 等があるらしい
gpt-2 や mistral-7b 等の学習済み SAE がある
Anthropic の Garcon にインスパイア
gather_residual_activations
register_forward_hook が PyTorch にはある
中間レイヤ出力にアクセスする API。便利!
ここにSAEを登録してやれば OK
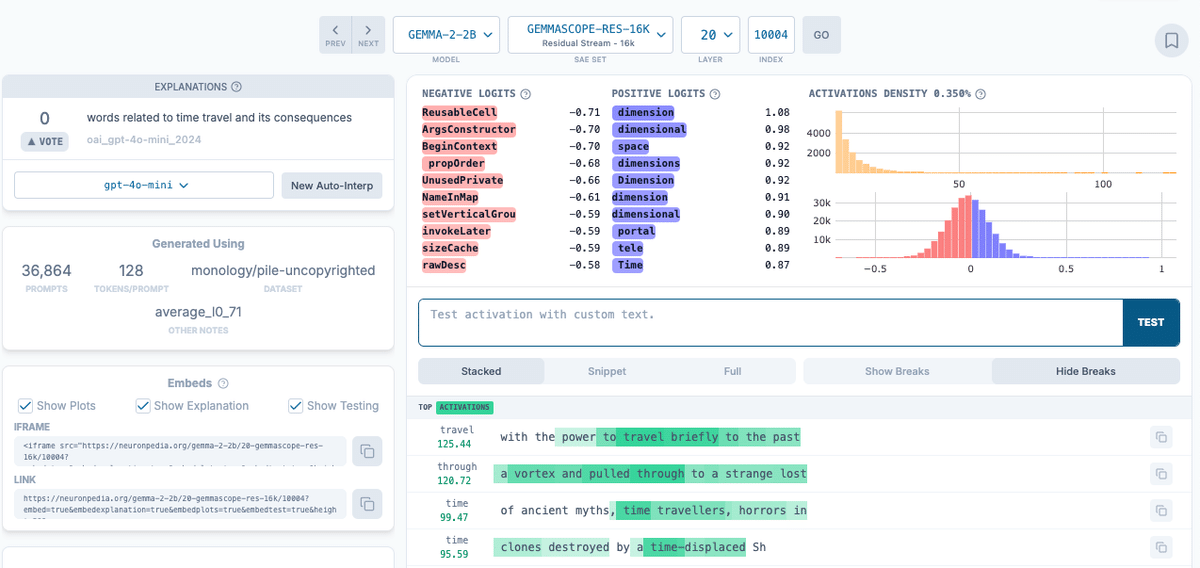
values, inds = sae_acts.max(-1) によって最も強く反応した SAE 中間層次元のインデックスを取得
今回は 10004 であり、この次元が反応するプロンプト群を GPT-4o-mini にまとめさせた結果は「time travel」を指す概念とのこと
プロンプトは「Would you be able to travel through time using a wormhole?」なので概念は合ってそう?

終わりに
LLM の内部分析に切り込むトレンドは確かに起こり始めている。結局 LLM の説明性ってどうなのよ?に関する社会の要請も高まっているように感じる。技術的に面白そうなトピックなので深掘りたい。
この記事が気に入ったらサポートをしてみませんか?