
Pythonで雀魂の対局結果を自動集計する②

こんにちは!カツキチです。
前回、画像から文字認識したものの目的の情報の収集には程遠い結果となりました。
画像から「名前」「素点」「順位点」の4組を正確に収集するにはどうしたら良いのだろう、、、眠れない日々が続きました(約1日)。
そして思いついたのは、「画像内の特定の場所のみをOCRすれば良いのでは」という仮説です。雀魂の対局結果画像は(大幅なバージョンアップがない限りは)フォーマットが決まっているので、「特定の場所」の指定はしやすいはず。ただし、以下の要素により「特定の場所」は若干異なる想定です。
雀魂のブラウザ版とアプリ版の違い
デバイスの画面サイズの違い
スクリーンショットの範囲の違い
しかし、Discord内のプレイヤーは限られるし、スクショをアップしてくれるのはほぼ北海さん(たまに私)なので以下の2つのパターンに限りました。
ブラウザ版、FHD(1920x1080)、全画面(北海さん環境)
アプリ版、FHD+(2400×1080)、全画面(カツキチ環境)
画像内の指定した箇所をOCRするには
調査したところ、OpenCVという画像処理ライブラリを使うのが良さそうです。
画像を(x,y)座標で表し、左上が原点(0,0)として以下のフローでテキスト化します。
OCRしたい箇所の左上と右下の座標を指定する
指定した範囲を切り取り、画像として保存する
保存した画像を、前回作成したプログラムでテキスト化する
サンプルコード Ver 0.2
作成したコードがこちらです。とりあえず1位のプレイヤー名のみをブラウザ版の画像で絶対値指定しました。
import os
import pyocr
from PIL import Image
import cv2
# PATH設定
TESSERACT_PATH = 'C:\\Program Files\\Tesseract-OCR' #インストールしたTesseract-OCRのpath
TESSDATA_PATH = 'C:\\Program Files\\Tesseract-OCR\\tessdata' #tessdataのpath
os.environ["PATH"] += os.pathsep + TESSERACT_PATH
os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH
# OCRエンジン取得
tools = pyocr.get_available_tools()
tool = tools[0]
# OCRの設定 ※tesseract_layout=6が精度には重要。デフォルトは3
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
# 画像をOpenCVで読み込む
img = cv2.imread("image.png")
# 1位のプレイヤー名の座標を絶対値指定
player_name_tl = ( 960, 305)
player_name_br = (1250, 345)
# 指定した範囲を切り取り、画像として保存する
cv2.imwrite('player_name.png', img[player_name_tl[1]:player_name_br[1],player_name_tl[0]:player_name_br[0]])
# OCR処理
img_name = Image.open("player_name.png")
txt_pyocr = tool.image_to_string(img_name, lang='jpn', builder=builder)
txt_pyocr = ''.join(txt_pyocr.split())
print(txt_pyocr)
# 検索対象画像内に、検索結果を黄色い長方形で描画
cv2.rectangle(img, player_name_tl, player_name_br, (0, 255, 255), 2)
# 検索結果を描画した画像を出力
cv2.imwrite("image_wr.png", img)OpenCVライブラリのインストール
PS > pip install opencv-pythonサンプルコードの実行
PS > python.exe .\sample_v0.2.py
りょーちんさん
PS >

なかなかいい感じですね。
サンプルコード Ver 0.3
次は1位のプレイヤー名、素点、順位点を絶対値指定し、読み取ります。
import os
import pyocr
from PIL import Image
import cv2
# PATH設定
TESSERACT_PATH = 'C:\\Program Files\\Tesseract-OCR' #インストールしたTesseract-OCRのpath
TESSDATA_PATH = 'C:\\Program Files\\Tesseract-OCR\\tessdata' #tessdataのpath
os.environ["PATH"] += os.pathsep + TESSERACT_PATH
os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH
# OCRエンジン取得
tools = pyocr.get_available_tools()
tool = tools[0]
# OCRの設定 ※tesseract_layout=6が精度には重要。デフォルトは3
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
# 画像をOpenCVで読み込む
img = cv2.imread("image.png")
# 1位のプレイヤー名、素点、順位点の座標を絶対値指定
player_name_tl = ( 960, 305)
player_name_br = (1250, 345)
player_point_tl = ( 960, 355)
player_point_br = (1200, 420)
player_rank_tl = (1200, 365)
player_rank_br = (1330, 405)
# 指定した範囲を切り取り、画像として保存する
cv2.imwrite('player_name.png', img[player_name_tl[1]:player_name_br[1],player_name_tl[0]:player_name_br[0]])
cv2.imwrite('player_point.png', img[player_point_tl[1]:player_point_br[1],player_point_tl[0]:player_point_br[0]])
cv2.imwrite('player_rank.png', img[player_rank_tl[1]:player_rank_br[1],player_rank_tl[0]:player_rank_br[0]])
# OCR処理(名前)
img_name = Image.open("player_name.png")
txt_pyocr = tool.image_to_string(img_name, lang='jpn', builder=builder)
txt_pyocr = ''.join(txt_pyocr.split())
print(txt_pyocr)
# OCR処理(素点)
img_name = Image.open("player_point.png")
txt_pyocr = tool.image_to_string(img_name, lang='jpn', builder=builder)
txt_pyocr = ''.join(txt_pyocr.split())
print(txt_pyocr)
# OCR処理(順位点)
img_name = Image.open("player_rank.png")
txt_pyocr = tool.image_to_string(img_name, lang='jpn', builder=builder)
txt_pyocr = ''.join(txt_pyocr.split())
print(txt_pyocr)
# 検索対象画像内に、検索結果を黄色い長方形で描画
cv2.rectangle(img, player_name_tl, player_name_br, (0, 255, 255), 2)
cv2.rectangle(img, player_point_tl, player_point_br, (0, 255, 255), 2)
cv2.rectangle(img, player_rank_tl, player_rank_br, (0, 255, 255), 2)
# 検索結果を描画した画像を出力
cv2.imwrite("image_wr.png", img)サンプルコードを実行します。「は」?ww
PS > python.exe .\sample_v0.3.py
りょーちんさん
45700
は35,7
PS > 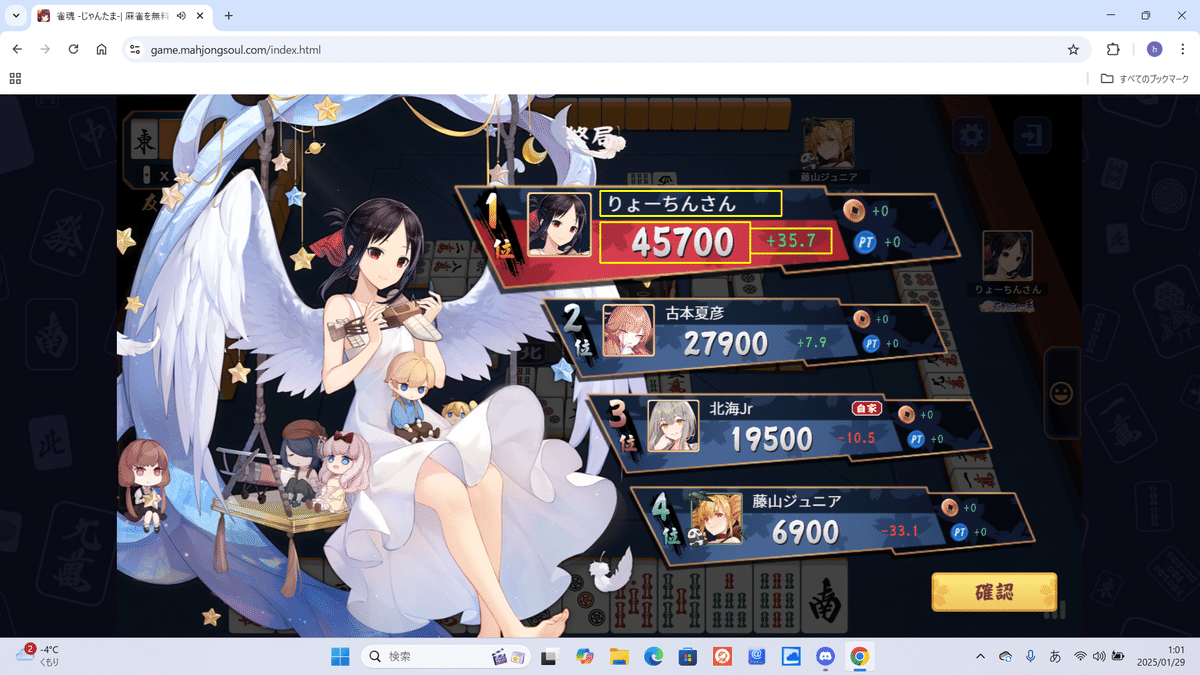


数字の読み取り精度は思ったよりも低いようですね。上の例では順位点がうまく読み取れず、「+」を「は」、「.(小数点)」を「,(カンマ)」と誤認識しています。複数枚の画像で試しましたところ、素点を誤認識するパターンもありました。
精度高く認識するにはどうしたらよいものか。次回へ続きます。