
Pythonで雀魂の対局結果を自動集計する③

こんにちは!カツキチです。
前回、対局結果画像から特定の個所を切り取った画像から文字認識する手法を取り、かなり精度が上がったもののいくつかの課題に直面しました。
素点、順位点を正確に読み取るにはどうしたら良いのだろう、、、眠れない日々が続きました(約1日)。
原因分析と対策
色々と情報収集してみたところ、原因は以下と推測しています。
素点、順位点のフォントが雀魂オリジナル?
背景にテキストが溶け込んでいる?
順位点の記号(+, -, . )を文字として認識している
それぞれの原因に対する対策は以下を設定しました。
日本語ではなく英語として文字認識する
グレイスケール+二値化する
順位点は素点から計算する
英語として文字認識する
数値を文字認識する際、Tessaract-OCRの訓練データとして日本語ではなく英語を用いるのが良いようです。コードを以下のように変更します。
#txt_pyocr = tool.image_to_string(img_name, lang='jpn', builder=builder)
txt_pyocr = tool.image_to_string(img_name, lang='eng', builder=builder)グレイスケール+二値化する
背景に文字が溶け込む可能性がある場合、白黒にしてテキストのみを浮き上がらせれば良いようです。コードに以下の処理を追加します。
# グレイスケール&二値化
img = cv2.imread("player_name.png", 0); #グレイスケールで読み込む
ret, img = cv2.threshold(img, 150, 255, cv2.THRESH_BINARY)
cv2.imwrite("player_name.png", img)順位点は素点から計算する
順位点についてもグレイスケール+二値化し、英語で文字認識させてみましたがどうしても安定しませんでした。そのため、順位点は素点から計算して算出することにしました。
雀魂の友人戦の順位点は「(素点 - 25000)÷ 1000 + 順位ウマ」で計算されます。ウマは1位:15、2位:5、3位:-5、4位:-15です。そのため、コードの順位点の取得処理を以下に変更します。
# OCR処理(順位点)
#img_name = Image.open("player_rank.png")
#rank = tool.image_to_string(img_name, lang='eng', builder=builder)
#rank = ''.join(trank.split())
#print(rank)
# 順位点の計算
uma = {1:15, 2:5, 3:-5, 4:-15} #順位ウマ
rank = round(( int(point) - 25000 ) / 1000 + uma[1], 2)
print(rank)サンプルコード Ver 0.4
以上3点の対策を反映したコードがこちらです。
import os
import pyocr
from PIL import Image
import cv2
# PATH設定
TESSERACT_PATH = 'C:\\Program Files\\Tesseract-OCR' #インストールしたTesseract-OCRのpath
TESSDATA_PATH = 'C:\\Program Files\\Tesseract-OCR\\tessdata' #tessdataのpath
os.environ["PATH"] += os.pathsep + TESSERACT_PATH
os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH
# OCRエンジン取得
tools = pyocr.get_available_tools()
tool = tools[0]
# OCRの設定 ※tesseract_layout=6が精度には重要。デフォルトは3
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
# 画像をOpenCVで読み込む
img = cv2.imread("image.png")
# 1位のプレイヤー名、素点の座標を絶対値指定
player_name_tl = ( 960, 305)
player_name_br = (1250, 345)
player_point_tl = ( 960, 355)
player_point_br = (1200, 420)
# 指定した範囲を切り取り、画像として保存する
cv2.imwrite('player_name.png', img[player_name_tl[1]:player_name_br[1],player_name_tl[0]:player_name_br[0]])
cv2.imwrite('player_point.png', img[player_point_tl[1]:player_point_br[1],player_point_tl[0]:player_point_br[0]])
# グレイスケール&二値化(名前)
img_name = cv2.imread("player_name.png", 0); #グレイスケールで読み込む
ret, img_name = cv2.threshold(img_name, 150, 255, cv2.THRESH_BINARY)
cv2.imwrite("player_name.png", img_name)
# OCR処理(名前)
img_name = Image.open("player_name.png")
name = tool.image_to_string(img_name, lang='jpn', builder=builder)
name = ''.join(name.split())
print(name)
# グレイスケール&二値化(素点)
img_point = cv2.imread("player_point.png", 0); #グレイスケールで読み込む
ret, img_point = cv2.threshold(img_point, 150, 255, cv2.THRESH_BINARY)
cv2.imwrite("player_point.png", img_point)
# OCR処理(素点)
img_point = Image.open("player_point.png")
point = tool.image_to_string(img_point, lang='jpn', builder=builder)
point = ''.join(point.split())
print(point)
# 順位点の計算
uma = {1:15, 2:5, 3:-5, 4:-15} #順位ウマ
rank = round(( int(point) - 25000 ) / 1000 + uma[1], 2)
print(rank)
# 検索対象画像内に、検索結果を黄色い長方形で描画
cv2.rectangle(img, player_name_tl, player_name_br, (0, 255, 255), 2)
cv2.rectangle(img, player_point_tl, player_point_br, (0, 255, 255), 2)
# 検索結果を描画した画像を出力
cv2.imwrite("image_wr.png", img)実行結果はこちら。欲しい情報が抽出されました!
PS > python.exe .\sample_v0.4.py
りょーちんさん
45700
35.7
PS > 


単に画像内の位置を指定するのでは芸がない
2位~4位でも同じような処理を行う必要があります。
手っ取り早くするなら同じコードを3つ書いて切り取り個所の座標にも変更すれば良いのですが、ブラウザ版とアプリ版の対応や多少の誤差も発生しそうなので、チマチマ絶対値指定なんかしていられません。
いろいろ調べたところ、OpenCVにはテンプレート画像のマッチング機能があることが分かりましたのでそれを利用することにします。
OpenCV(Python)でTemplate Matchingを使用して物体検出をしてみた | DevelopersIO
OpenCVのテンプレートマッチング機能とは
ベースの画像の中に、テンプレートの画像がマッチした(x,y)座標を返してくれる機能です。ベースの画像は対局結果画像、テンプレートの画像は各順位の画像を用いました。





テンプレート画像ごとにテンプレートマッチングを行い、一番信頼度が高い座標をベースとして水色の長方形で囲いました。
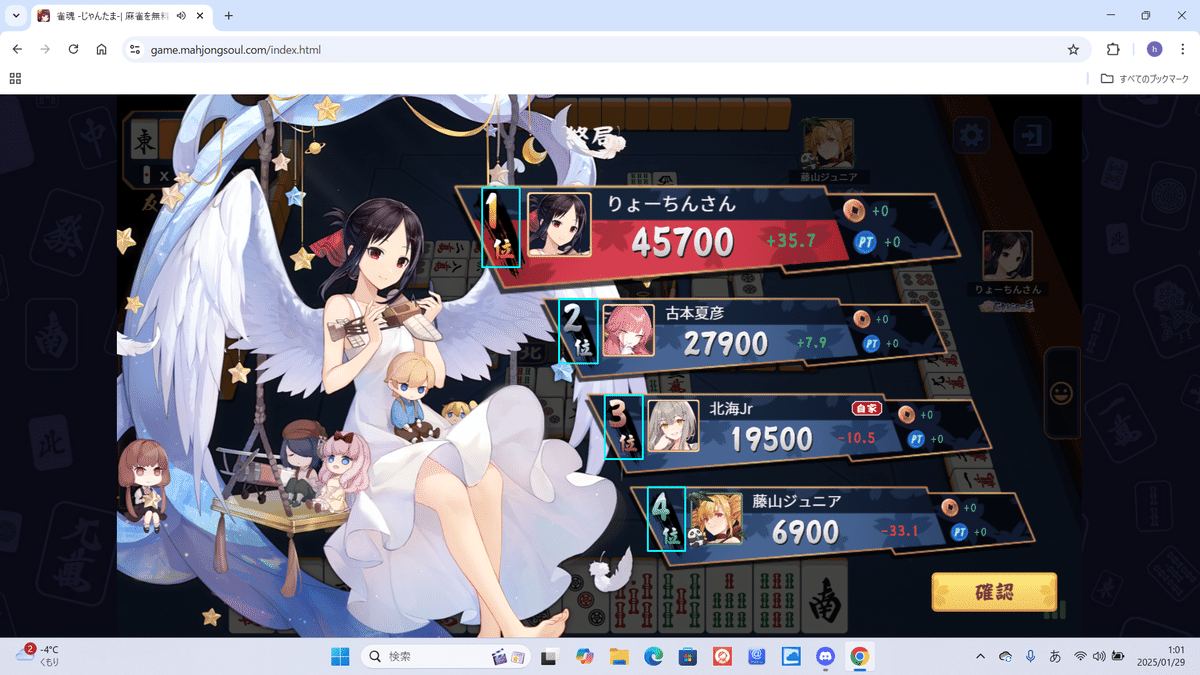
こうすることでマッチングした座標からx軸(右方向)とy軸(下方向)にずらせば名前と素点を抽出できそうかわかります。また1位はプレイヤー画像やフォントが大きいですが、2位~4位は小さく、かつ位置は異なるものの決まった分だけずれているように見えるので、マッチング座標からの位置は同じ分ずらせば良さそうです。
サンプルコード Ver 0.5
やや大作となってきましたが、関数を作ったため比較的行数は抑えられました。(Pythonって素晴らしい!)
また画像サイズからブラウザ版かアプリ版かを判別し、それぞれ座標を指定しています。
import os
import pyocr
from PIL import Image
import cv2
# PATH設定
TESSERACT_PATH = 'C:\\Program Files\\Tesseract-OCR' #インストールしたTesseract-OCRのpath
TESSDATA_PATH = 'C:\\Program Files\\Tesseract-OCR\\tessdata' #tessdataのpath
os.environ["PATH"] += os.pathsep + TESSERACT_PATH
os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH
# OCRエンジン取得
tools = pyocr.get_available_tools()
tool = tools[0]
# OCRの設定 ※tesseract_layout=6が精度には重要。デフォルトは3
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
# 画像をOpenCVで読み込む
img = cv2.imread("image.png")
# 画像のサイズからPCかSPかを決める
if img.shape[1] < 2000:
flag = "PC" #ブラウザ版
else:
flag = "SP" #アプリ版
# 指定した画像をOCRしてテキストを抽出
def img2text(image_file, lang, place):
# グレイスケール&二値化
img = cv2.imread(image_file, 0); #グレイスケールで読み込む
ret, img = cv2.threshold(img, 150, 255, cv2.THRESH_BINARY)
cv2.imwrite("output/" + str(place) + image_file, img)
# OCR処理
img = Image.open("output/" + str(place) + image_file)
txt = tool.image_to_string(img, lang=lang, builder=builder)
txt = ''.join(txt.split())
return(txt)
# 順位に応じたプレイヤーの名前、素点、順位点を出力
def player_info_print(template_file, place, flag):
# テンプレート画像の読み込み
template = cv2.imread(template_file)
h, w, _ = template.shape # 幅と高さを取得
# 画像の検索(Template Matching)
result = cv2.matchTemplate(img, template, cv2.TM_CCORR_NORMED)
# 検索結果の信頼度と位置座標の取得
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
# 検索結果の座標を取得
top_left = max_loc # 左上
bottom_right = (top_left[0] + w, top_left[1] + h) #右下
# 検索対象画像内に、検索結果を水色の長方形で描画
cv2.rectangle(img, top_left, bottom_right, (255, 255, 0), 2)
# 名前と素点の座標を指定
if flag == "SP": #アプリ版
if place == 1:
player_name_tl = (top_left[0] + 230, top_left[1] - 20)
player_name_br = (top_left[0] + 530, top_left[1] + 40)
player_point_tl = (top_left[0] + 230, top_left[1] + 45)
player_point_br = (top_left[0] + 530, top_left[1] + 135)
else:
player_name_tl = (top_left[0] + 195, top_left[1] + 0)
player_name_br = (top_left[0] + 420, top_left[1] + 40)
player_point_tl = (top_left[0] + 195, top_left[1] + 45)
player_point_br = (top_left[0] + 420, top_left[1] + 115)
else: #ブラウザ版
if place == 1:
player_name_tl = (top_left[0] + 190, top_left[1] + 3)
player_name_br = (top_left[0] + 440, top_left[1] + 50)
player_point_tl = (top_left[0] + 190, top_left[1] + 55)
player_point_br = (top_left[0] + 440, top_left[1] + 120)
else:
player_name_tl = (top_left[0] + 160, top_left[1] + 5)
player_name_br = (top_left[0] + 360, top_left[1] + 40)
player_point_tl = (top_left[0] + 160, top_left[1] + 45)
player_point_br = (top_left[0] + 360, top_left[1] + 95)
# 指定した範囲を切り取り、画像ファイルとして保存
cv2.imwrite('player_name.png', img[player_name_tl[1]:player_name_br[1],player_name_tl[0]:player_name_br[0]])
cv2.imwrite('player_point.png', img[player_point_tl[1]:player_point_br[1],player_point_tl[0]:player_point_br[0]])
# 切り取った画像ファイルから文字認識
name = img2text('player_name.png', 'jpn', place)
point = img2text('player_point.png', 'eng', place)
# 順位点の計算
uma = {1:15, 2:5, 3:-5, 4:-15} #順位ウマ
rank = round(( int(point) - 25000 ) / 1000 + uma[place], 2)
# 結果を標準出力
print(place, name, point, rank)
# 検索対象画像内に、検索結果を黄色い長方形で描画
cv2.rectangle(img, player_name_tl, player_name_br, (0, 255, 255), 2)
cv2.rectangle(img, player_point_tl, player_point_br, (0, 255, 255), 2)
# 順位ごとに処理
player_info_print('../template/no1.png', 1, flag)
player_info_print('../template/no2.png', 2, flag)
player_info_print('../template/no3.png', 3, flag)
player_info_print('../template/no4.png', 4, flag)
# 検索結果を描画した画像を出力
cv2.imwrite("image_wr.png", img)実行した結果がこちらです。うまくできました!
PS > python.exe .\sample_v0.5.py
1 りょーちんさん 45700 35.7
2 古本夏彦 27900 7.9
3 北海Jr 19500 -10.5
4 藤山ジュニア 6900 -33.1
PS > 
続いて同じコードでアプリ版の画像をOCRします。
PS > python.exe .\sample_v0.5.py
1 かいとんばぱば_ 63500 53.5
2 はーーどおふ 28000 8.0
3 ざきむくぐ 4800 -25.2
4 yabukilab 3700 -36.3
PS > んん??プレイヤー名が変だなぁww

Tesseract-OCRの情報を色々調べましたが、日本語の読み取り精度は限界があるようです。Tesseractの訓練データを追加するなどしないと向上が難しいため、誤認識があった場合は以下のような補正プログラムを随時追加して対応することにしました。
# データ補正(名前)
name = name.replace('はーーどおふ', 'はーどおふ')
name = name.replace('ざきむくぐ', 'ざきむぐ')
name = name.replace('かいとんばぱば_', 'かいとんぱ_')力技ではありますが意図した結果にはなりました。
PS > python.exe .\sample_v0.5.py
1 かいとんぱ_ 63500 53.5
2 はーどおふ 28000 8.0
3 ざきむぐ 4800 -25.2
4 yabukilab 3700 -36.3
PS > とりあえずここまでで対局結果画像から欲しい情報をテキストで抽出することができましたが、対局結果テキストをどこかにまとめ、集計するにはどうしたらよいものか。
次回へ続きます。