Twitter投稿内の画像データから投稿におけるエンゲージメント率を予測する

こんにちは!Katsuです!
今回私は、プライベートで行っているTwitterでのツイートにおける画像データから、それに対するエンゲージメント率を予測するモデルを構築してみました。
概要
ここで今回のデータに用いる指標についてまとめておきたいと思います。
Twitter Analyticsでは過去のツイートに関するさまざまな指標を確認することが可能となっています。

さらに、今回扱うエンゲージメント率と、それに関連する且つツイートに関係する基本的な指標としてインプレッション・エンゲージメント総数というものがあります;
・インプレッション:投稿が表示された回数のこと。
・エンゲージメント総数:一つのツイートに対する「反応数」のこと。いいね・リツイート・返信・フォロー・クリックがこれに該当する
・エンゲージメント率:エンゲージメント総数をインプレッションで割ったもの。投稿が表示された回数(インプレッション)のうち、どのくらいの割合で上記のようなアクションがなされたのかを示す指標となる。
今回は各ツイートの画像データからエンゲージメント率を予測するモデルを作成します。画像データという観点からエンゲージメント率の高低のダイナミクスの特徴をつかみ、それを予測モデルに用いることで、どのような画像であればより良いエンゲージメント率を残せるのか(どのような画像であればユーザーに興味を持ってもらえるツイートとなっているのか)という課題の解決を目指し、今回この分析に取り組むものです。
次に今回の予測に使ったデータについてですが;
・筆者およびその仲間が投稿したツイート(2021年8月中旬~2022年2月中旬までの約半年間)を使用
・対象期間におけるツイートペースは、週2~3回。
・計134枚の画像データに加え、それぞれに対して水増し処理を施した画像データを使用(後述します。)
ちなみに今回の予測モデルの構築環境ですが;
・Python3
・Surface Laptop Studio
・Chrome
・Google Colaboratory
となります。
先に結果を記載します

エンゲージメント率をx 1,000倍をしています)
そして次が;

誤差としては、ものにもよりますが、約15~20程の差があるといったところです。
が、これに関しては、以下で触れますが、平均二乗誤差を損失関数として今回のモデル構築では採用していますので、それぞれの行列内の要素を1,000で割ったものが実際の誤差となります。ですので、一つ目の要素を例にとると;
(小数第二位は四捨五入)
42.9- 53.4 = -10.5
-10.5 / 1000 = -0.0105
これが一つ目の要素のエンゲージメント率における
訓練データと検証データの間の実際の誤差になります。
以下はモデル学習の結果です。
Val_lossの数字としては300±30あたりを行ったり来たりしているものの、ここではmodel.compileの部分でloss='mse'としている(=平均二乗誤差を損失関数としてとっている)ので、300±30の平方根をとった数がその学習時の誤差範囲となります。;
Epoch 1/40 21/21 [==============================] - 2s 89ms/step - loss: 88.4014 - val_loss: 361.9297 Epoch 2/40 21/21 [==============================] - 2s 82ms/step - loss: 68.4331 - val_loss: 328.0037 Epoch 3/40 21/21 [==============================] - 2s 82ms/step - loss: 71.8526 - val_loss: 311.9635 Epoch 4/40 21/21 [==============================] - 2s 82ms/step - loss: 67.9206 - val_loss: 326.1109 Epoch 5/40 21/21 [==============================] - 2s 82ms/step - loss: 77.8519 - val_loss: 298.1821 Epoch 6/40 21/21 [==============================] - 2s 82ms/step - loss: 72.5469 - val_loss: 340.5644 Epoch 7/40 21/21 [==============================] - 2s 82ms/step - loss: 70.7362 - val_loss: 365.3192 Epoch 8/40 21/21 [==============================] - 2s 82ms/step - loss: 61.4045 - val_loss: 296.3844 Epoch 9/40 21/21 [==============================] - 2s 82ms/step - loss: 68.4164 - val_loss: 355.6284 Epoch 10/40 21/21 [==============================] - 2s 82ms/step - loss: 58.3053 - val_loss: 322.7552 Epoch 11/40 21/21 [==============================] - 2s 82ms/step - loss: 72.8377 - val_loss: 325.5472 Epoch 12/40 21/21 [==============================] - 2s 82ms/step - loss: 64.8481 - val_loss: 309.9313 Epoch 13/40 21/21 [==============================] - 2s 86ms/step - loss: 65.7386 - val_loss: 323.3021 Epoch 14/40 21/21 [==============================] - 2s 82ms/step - loss: 66.0436 - val_loss: 294.2788 Epoch 15/40 21/21 [==============================] - 2s 83ms/step - loss: 70.4625 - val_loss: 323.0106 Epoch 16/40 21/21 [==============================] - 2s 82ms/step - loss: 63.0484 - val_loss: 304.8846 Epoch 17/40 21/21 [==============================] - 2s 83ms/step - loss: 68.2289 - val_loss: 303.4382 Epoch 18/40 21/21 [==============================] - 2s 86ms/step - loss: 82.7852 - val_loss: 339.8987 Epoch 19/40 21/21 [==============================] - 2s 83ms/step - loss: 64.2600 - val_loss: 294.2351 Epoch 20/40 21/21 [==============================] - 2s 82ms/step - loss: 65.3108 - val_loss: 320.0265 Epoch 21/40 21/21 [==============================] - 2s 83ms/step - loss: 61.4352 - val_loss: 353.5197 Epoch 22/40 21/21 [==============================] - 2s 83ms/step - loss: 70.7465 - val_loss: 270.6357 Epoch 23/40 21/21 [==============================] - 2s 83ms/step - loss: 132.9631 - val_loss: 299.2587 Epoch 24/40 21/21 [==============================] - 2s 83ms/step - loss: 74.9428 - val_loss: 327.4743 Epoch 25/40 21/21 [==============================] - 2s 83ms/step - loss: 71.8211 - val_loss: 302.3325 Epoch 26/40 21/21 [==============================] - 2s 83ms/step - loss: 79.9004 - val_loss: 307.6630 Epoch 27/40 21/21 [==============================] - 2s 83ms/step - loss: 72.3954 - val_loss: 350.4557 Epoch 28/40 21/21 [==============================] - 2s 83ms/step - loss: 71.4454 - val_loss: 272.9068 Epoch 29/40 21/21 [==============================] - 2s 84ms/step - loss: 62.8831 - val_loss: 388.0725 Epoch 30/40 21/21 [==============================] - 2s 83ms/step - loss: 76.2654 - val_loss: 337.2790 Epoch 31/40 21/21 [==============================] - 2s 83ms/step - loss: 59.0420 - val_loss: 289.5619 Epoch 32/40 21/21 [==============================] - 2s 86ms/step - loss: 75.4525 - val_loss: 317.9636 Epoch 33/40 21/21 [==============================] - 2s 82ms/step - loss: 66.9732 - val_loss: 317.2074 Epoch 34/40 21/21 [==============================] - 2s 83ms/step - loss: 67.5775 - val_loss: 295.8447 Epoch 35/40 21/21 [==============================] - 2s 83ms/step - loss: 67.3038 - val_loss: 325.1971 Epoch 36/40 21/21 [==============================] - 2s 82ms/step - loss: 73.3099 - val_loss: 280.8031 Epoch 37/40 21/21 [==============================] - 2s 82ms/step - loss: 95.9330 - val_loss: 252.7266 Epoch 38/40 21/21 [==============================] - 2s 83ms/step - loss: 96.5582 - val_loss: 320.8510 Epoch 39/40 21/21 [==============================] - 2s 83ms/step - loss: 82.0064 - val_loss: 311.2285 Epoch 40/40 21/21 [==============================] - 2s 87ms/step - loss: 79.5071 - val_loss: 341.5414 1/1 [==============================] - 0s 118ms/step - loss: 341.5414 Test loss: 341.5413818359375
では、次に実際に行ったことを以下の通り記載します
分析フロー(まずは日本語で)
画像データ&いいね数やエンゲージメント率が記載された各ツイート単位でのツイート情報が盛り込まれたcsvファイル(後述します)をTwitterより取得
画像データのファイル名を、各ツイート情報にも反映(複数画像があるツイートの場合には当該行を画像枚数文コピー&ペースト)
画像データが入ったzipファイルの読み込み&csvファイルをDataFrameにして読み込み
データ準備&水増し画像の準備
予測モデルの構築
分析フロー(一つ一つ、コードや実際の画面とともに、
追ってみていきましょう)
1. 画像データ&いいね数やエンゲージメント率が記載された各ツイート単位でのツイート情報が盛り込まれたcsvファイル(後述します)をTwitterより取得
画像データの取得は、ツイートのタイミング毎に「このツイートはこの画像…」という風に後で振り返られる形で画像を保存していたわけではないので、過去のツイートを振り返っては保存し振り返っては保存し…という力技でした。
一方でcsvファイルについては、便利なことに、Twitterでは各ツイート単位でのいいね数やエンゲージメント率の情報が盛り込まれたファイルをダウンロードできるので、これを取得しました。今回の予測では、このようなcsvファイルを6つ取得しています。

"Export data"でcsvが取得できる
2. 画像データのファイル名を、各ツイート情報にも反映(複数画像があるツイートの場合には当該行を画像枚数文コピー&ペースト)
先ほど取得したcsvファイルの各種情報をもとに、1行1行に対して画像データのファイル名をB列内の対応する行に入力していきました。
B列記載の画像データのファイル名ですが、”UTXXXX”とUTの後ろに四桁の数字が並んでいます。複数枚画像データがツイートされていた場合は、一枚目の行をその画像枚数文コピー&ペーストして、最初の三桁はその画像データのファイル名と同じ数字を、最後の四桁目は違う数字を入れていくことで対応しました。
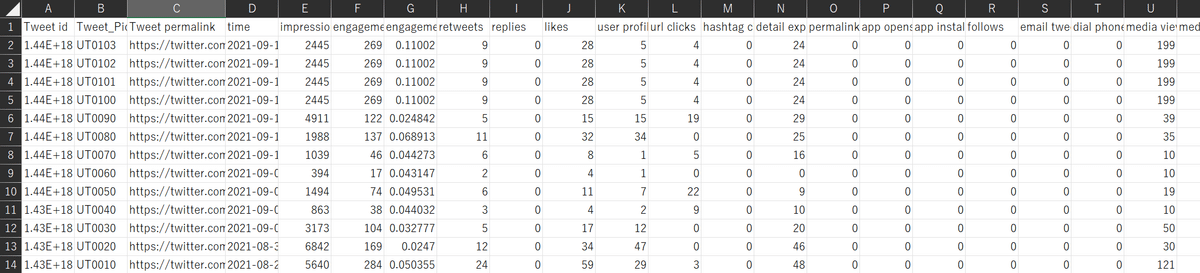
B列には実際のツイート文が記載されていたが今回は不要かつ文字化けしていたため削除
代わりに、画像データの名前を各行に入力していった
ちなみに今回必要だったのはB列とG列のみだったので、後述するDataFrameへの変換時に
その2行の実を選択するコードも入れている。
3. 画像データが入ったzipファイルの読み込み&csvファイルをDataFrameにして読み込み
2.まで出来たらいよいよコーディングです。
まずは画像データをzipファイルから読み込みます;
読み込んだ画像データは"/content/drive/MyDrive/成果物/ТPС╠"へと
件数分格納されます。
*出力は画像データが多いため割愛します。
import os
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# zipファイルの解凍&解凍先ファイルのディレクトリ取得
# !unzip -d /content/drive/MyDrive/成果物/ /content/drive/MyDrive/成果物/画像データ.zip
# from google.colab.patches import cv2_imshow
# img = cv2.imread("/content/ТPС╠/UT0010.jfif")
# cv2_imshow(img)
path_image = os.listdir("/content/drive/MyDrive/成果物/ТPС╠")
# 画像データを一枚ずつ格納していく
imgs = []
for i in range(len(path_image)):
img = cv2.imread( "/content/drive/MyDrive/成果物/ТPС╠/"+ path_image[i])
img = cv2.resize(img, (100,100))
imgs.append(img)次に、後のDataFrameでの処理に使うのですが、画像データのファイル名部分のみの抽出を行います;
# 画像データの名前部分のみを抽出
# path_image[0][:-5]
new_imgs = []
for i in path_image:
tmp_path = i[:-5]
new_imgs.append(tmp_path)
new_imgs出力結果は以下の通りです;

ファイル名部分のみを抽出したものをリスト化しています。
次にcsvファイルをDataFrameとして読み込みます;
# csvファイルを一つずつDataFrameに変換→結合
path_twitter = os.listdir('/content/drive/MyDrive/成果物/tweet_activity')
df_twitter = pd.DataFrame()
for i in path_twitter:
tmp_df = pd.read_csv('/content/drive/MyDrive/成果物/tweet_activity/'+i)
df_twitter = pd.concat([df_twitter,tmp_df])
# Index再設定
df_twitter = df_twitter.set_index('Tweet_Picture')
df_twitter = df_twitter.reindex(index = new_imgs)
df_twitter = df_twitter.loc[:,["engagement rate"]]ここでは、先ほど取得した6つのcsvファイルをそれぞれfor文の繰り返し処理で読み込み、concatによる結合を行っています。また、読み込んだ後には、#Index再設定 という部分で、先ほど作成したnew_imgsをもとにDataFrame内のIndexの振り直しを行っています(画像データの読み込み順とDataFrameの順番を合わせるため。)
そして最後にlocでengagement rateのみを抽出しています。
4. データ準備&水増し画像の準備
from tensorflow.keras import optimizers
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
# データ準備
X = np.array(imgs)
y = np.array(df_twitter["engagement rate"])*1000
# ランダム化
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 水増しコード
def augmentation(img):
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
# 画像の左右反転
aug0 = cv2.flip(img,1)
# 閾値処理
aug1= cv2.threshold(img,100,255,cv2.THRESH_TOZERO)[1]
# ぼかし
aug2 = cv2.GaussianBlur(img,(45,45),0)
# モザイク処理
aug3 = cv2.resize(cv2.resize(x,(img_size[1]//5,img_size[0]//5)),(img_size[1],img_size[0]))
# 収縮
aug4 = cv2.erode(x,np.array([[0,1,0],[1,0,1],[0,1,0]],np.uint8))
return [aug0,aug1,aug2,aug3,aug4]
# 水増し後の画像リスト
X_aug = []
y_aug = []
# Xに入っている画像1枚1枚に対してループを行う
for x,y in zip(X_train,y_train):
# augmentationを行う関数
augimgs = augmentation(x)
X_aug = X_aug + augimgs
y_aug = y_aug + [y]*len(augimgs)
# もとのXと水増しされたX_augをつなげる。※yも同様
X_train = np.concatenate([X_train, X_aug])
y_train = np.concatenate([y_train, y_aug])画像データの水増しは、汎化性能を保持する観点から、画像データを訓練データと検証データに分けた後に行っています。
水増し処理内容としては;
1. 左右反転
2. 閾値処理
3. ぼかし
4. モザイク処理
5. 収縮
を行っています。
水増し処理後は、処理後の画像データとそのラベル(=engagement率)を水増し前の画像データとそのラベルとつなげることで、X_train、y_trainリストに格納しています。
5. 予測モデルの構築
ここまで来たらいよいよ予測モデルの構築を行っていきます。
今回はVGG16のImagenetを使用したモデル構築となります。
# input_tensorの定義をして、vggのImageNetによる学習済みモデルを作成
input_tensor = Input(shape=(100, 100, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 特徴量抽出部分のモデルを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(512, activation='relu'))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1))
# vgg16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 19層目までの重みを固定
for layer in model.layers[:19]:
layer.trainable = False
# 学習の前に、モデル構造を確認
model.summary()
# コンパイル
model.compile(loss='mse',optimizer='adam')
最初のinput_tensorでは、今回は画像データ読み込みの際にresizeで(100,100)としておりますので、これに合わせて(100,100,3)としています。
また、今回はengagement率という連続した値を予測しに行く”回帰”分析になりますので、最後の出力はmodel.add(Dense(1))となります。
出力は以下の通りです;


学習を進めるコードは以下の通りです;
# バッチサイズ32で学習を実施
model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=32, epochs=40)
# 以下の式でモデルを保存
model.save_weights('param_vgg_15.hdf5')
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores)学習回数を重ねるためepoch数は40としています。1回の実行にかかる時間としては1分半といったところでしょうか。
こちらの出力結果および検証データの予測結果は冒頭に述べたとおりです。
まとめ(今後の課題)
今回の予測モデルの構築において、画像データに映っている内容が古今東西本当にいろいろなものが映っていたということもあり、最初は全く精度がよくないモデルが仕上がっていたものの、画像水増しコードの実装だったり、深層学習部分のコーディングの工夫だったりと改善を施した結果、精度がそこまで悪くないモデルを作成することができました。一方で、まだ改善の余地は大幅にありますので、画像データの粒度を上げたりそもそものモデリングでVGG16以外のものを採用したりなど、さらなる改善を突き詰めていけたらと思っています。
以上です!ありがとうございました!