PDCIが辞書データとしてインポートできるテキストファイル、CSVファイルの覚書+付随雑記

*以下「PDIC」はPDIC/Unicodeを指しています、PDIC for Win32ではありません
最近辞書検索ソフトウェアであるPersonal Dictionary(PDIC)用の辞書をいくつか作成しました。
辞書用のテキストファイルを作成、それをPDICでインポートするという手順です。
本記事はその際の覚書です。
辞書作成時にどの形式を選ぶべきか
PDICが辞書としてインポートできる形式はいくつかあるのですが、今回確認したのは
・1行テキスト形式
・CSV形式
です。
結論としては
CSV形式を選んだほうが無難
となりました。
CSV形式と比較した場合、1行テキスト形式には以下のデメリットがありました。
・見出語、訳語、用例しか指定できない=発音記号や単語レベルが指定できない
・句点(。)、読点(、)、全角スペースが一律半角カンマ(,)に変換されてしまい可読性が落ちる → 他にも変換されてしまう文字があるかも、エスケープ処理等で変換されずにインポートする方法は見つけられなかった
逆にこれらが気にならないのであればPDIC1行テキスト形式を選択しても問題ないと思います。
辞書データとしてインポートするテキストファイルに指定する文字コード、BOMの有無、改行コードについて
PDICに
設定→詳細設定→テキストファイルの文字コード
という設定項目があります。
*これはPDICの「エクスポート、書き込み」用の設定で、今回の目的である「インポート」には影響しません
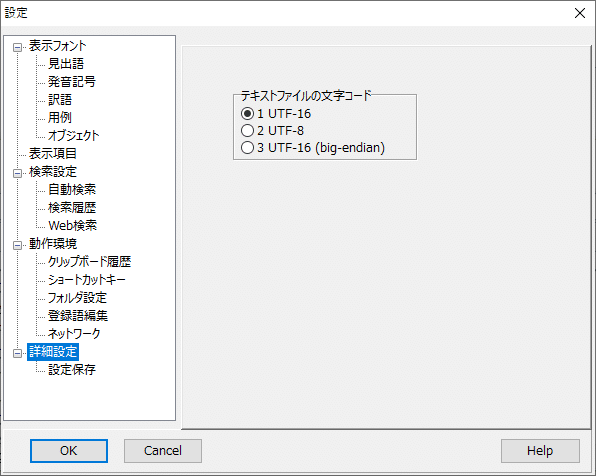
PDICは上記スクリーンショットで指定できる
・UTF-16
・UTF-8
・UTF-8(big-endian)
のファイルはインポートできました。またCP932(ShiftJIS)もインポートできました。
今回私が作成した辞書ファイルは
・文字コード:UTF-16(=UTF-16LE)
・BOMの有無:あり
・改行コード:CRLF
としました。
PDICはBOMがないファイルをインポートできるものの、検索結果が文字化けしました(これはPDICが警告を出してもいいと思うのですが)。
改行コードはLFでも問題なかったのですが、PDICで辞書をエクスポートして確認したところCRLFだったのでそれに従っています。
ちなみにPDICの辞書エクスポートの手順は以下の通りです。
File→辞書設定<詳細>→辞書グループ選択→辞書右クリック→辞書変換→任意の変換先辞書選択、変換先ファイル形式:CSV形式→OK(→エクスポートされたファイルを任意のテキストエディタ等で確認)
CSVの書式について
これはヘルプのページに詳しめに書いてあります。
・1行目に"word"という項目があればその行を項目名のリストとして扱います。(つまり、wordは必須)
・1行目に"word"という項目がない場合は1行目以降を辞書データとして扱います。その場合、次のような項目の並びであることを前提にします。
word,trans,exp,level,memory,modify,pron
CSVの1行目に必要な項目のみヘッダーを出力(例えばword,trans(見出語と訳語)の2項目)、2行目以降はヘッダーに従ってデータを出力します。つまり「不要な項目はヘッダーに記述しなければ良い」ということになります。
1行目にヘッダーがない場合(=1行目に"word"という項目がない場合)、項目は
word,trans,exp,level,memory,modify,pron
となるそうですが、こちらは今回未確認です。
発音記号項目を使用するか否か
PDICの辞書グループには複数の辞書が指定可能です。それらの辞書が各自に発音記号項目を持っていると、発音記号が辞書ごとに改行されて羅列されます。つまり重複して表示されることになります。
以下は3辞書が見出語"A"それぞれに発音記号"a"を持っていた場合の表示例。
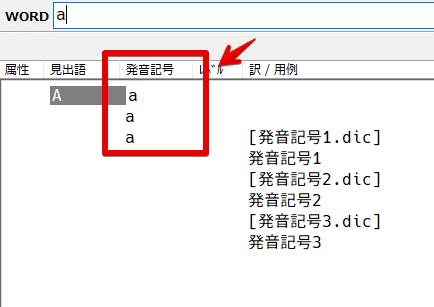
重複した発音記号を非表示にする設定は多分ありません
同一の発音記号であっても全て列挙されます。
複数辞書をグループ化して使用する場合、このことを考慮して発音記号項目を設定したほうが良さそうです。
対策としては常用する辞書(1辞書)でのみ発音記号項目を設定する、手間はかかりますが発音記号表示用の辞書ファイルを作成するなどでしょうか。もっとよい方法をご存じの方がいらしたらコメントで教えていただけると嬉しいです。
今回は発音記号を訳語の先頭に記述、発音記号項目は使用しないことにしました。
大容量テキストファイルの確認、置換について
辞書ファイルを作成している際に大容量テキストファイルを開いて確認、及び内容を置換したい場合が出てきました。
当初この作業をすべて秀丸エディタで行っていたのですが
秀丸は扱うファイルのサイズが大きいと
・動作が緩慢になる(alt+tabによるウインド選択ですらスムーズでない場合がある)
・正規表現で改行を含むデータを置換するのに非常に時間がかかる(クイック全置換でも遅い、今回対処法は発見できず)
という問題がありました。
置換にSpeeeeedを使用してみたのですが一部正規表現が使えませんでした(*私がパラメータを勘違いしている可能性もあります)。
その時に以下の記事を思い出し無償版「EmEditor」(EmEditor Free版)を使用してみたところスムーズに作業できました。
無償版「EmEditor」でも巨大ファイルを扱えるように ~v21.3がリリース - 窓の杜
50分かかった超大容量置換が1秒に! 検索と置換がさらに速くなったEmEditorはなにを目指すのか? - 窓の杜
(窓の杜はEmEditor推しっぽいです、まあその記事を読んだ結果今回使ってみたわけですが、正直まんまと乗せられた感もちょっとあります)
EmEditorは永久ライセンスが4万円以上(2022年8月現在)と気軽に買える価格ではなくなってしまいましたが、今回の目的ではFree版でも必要な作業は実施できました。Free版はキーバインドが変更できませんが、私はAutoHotkeyで対応しました。
【了】