Llama2のモデル構造とパラメータ内訳

はじめに
論文を書くにあたり、大規模言語モデルLlama2のモデル構造とパラメータ内訳について、ある程度詳しく理解する必要があったので、整理しました。
間違っていたらすみません。
要点(個人的見解)
Lllama2において、attention層は全パラメータの約3割、MLPは約6割を占める。
パラメータ数の多いMLP層を更新した方が、ファインチューニングでの知識獲得には有利
一方でattention層を更新するだけでも知識獲得できる場合があるので、両者の間で明確な役割分担がなされているわけでは無さそう

関連記事
大規模言語モデルにおいて、知識獲得はどの層が担っているのか?という研究についての記事。
大規模言語モデルをファインチューニングするにあたり、LoRAを適用する層を変えてみた記事。
確認用コード
どのようなlayerが使われ、パラメータ数が幾つであるかを確認するためのgoogle colabのコードを書きました。7bモデルを使いました。
モデル初期化
#ライブラリ
!pip install transformers
!pip install peft
!pip install bitsandbytes
!pip install accelerate
#モデル読み込み。colabの無料プランでも読めるよう、4bitにする
from transformers import pipeline
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
#モデル読み込み
model_name = "meta-llama/Llama-2-7b-chat-hf"
#load base model
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_name,token=token)
model = AutoModelForCausalLM.from_pretrained(model_name,
quantization_config=bnb_config,
device_map="auto",
token=token
)
層の確認
num_dict={}
for name, param in model.named_parameters():
num_dict[name]=param.numel()
print(name)
パラメータ数の確認
name_set=[]
repl_parts=[
"model",
"layers",
"weight",
"mlp",
"self_attn",
]
def is_integer(s):
try:
int(s)
return True
except ValueError:
return False
for original_name in num_dict:
name=original_name.split(".")
name=[i for i in name if i not in repl_parts]
name=[i for i in name if not is_integer(i)]
name_set.append(".".join(name))
#主要なレイヤーグループの表示
print(set(name_set))
#パラメータ数の計算
name_group_dict={}
all_params=0
for k,v in num_dict.items():
found=False
for group_name in name_set:
if group_name in k:
if group_name not in name_group_dict:
name_group_dict[group_name]=v
else:
name_group_dict[group_name]+=v
all_params+=v
found=True
break
if not found:
print(k," not found")
import pandas as pd
df=pd.DataFrame.from_dict(name_group_dict,orient="index")
df.columns=["params"]
df["ratio"]=df["params"]/all_params*100
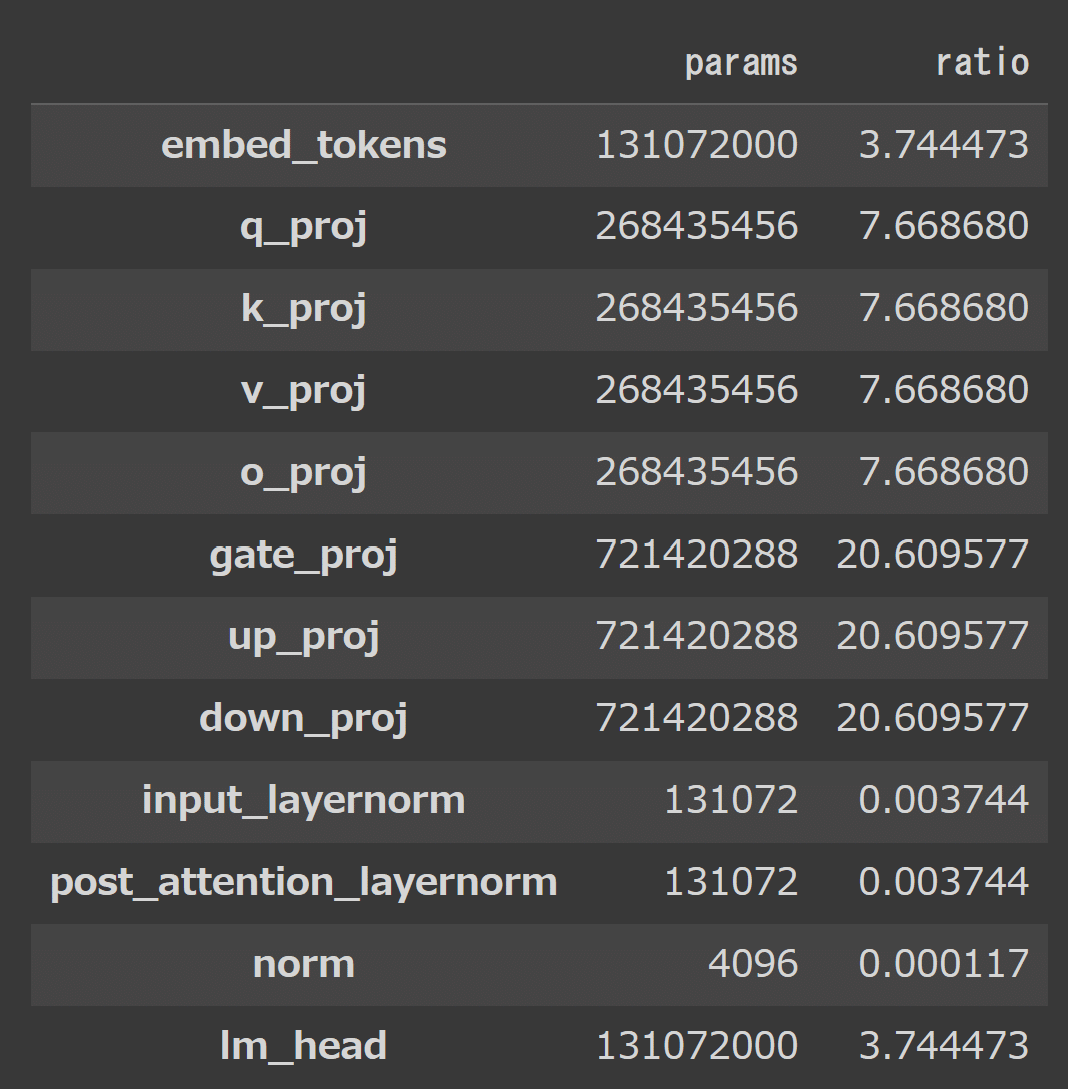
df最終出力は以下の通り
モデル構造
図示
出力された情報をもとに、モデル構造を図示してみます。
作図にはxmindを使いました。
※ norm系の層はパラメータ数が少ないので、表記していません
各レイヤーの意味
embedding
与えられたテキストのトークンをテンソル空間に転写するための層
単語の"意味"を捉える上で重要と思われる層
self-attention
文章の中の単語間の関係性を解釈するための層
q_proj: queryに関する層
k_proj: keyに関する層
v_proj: valueに関する層
o_proj: q,k,vの結果を統合して、MLPに持って行くための層
MLP
諸々のことを覚えるため?の層
gate_proj (gate projection): attention層からデータを受け取って、活性化関数を介さずにdown_projectionに飛ばす層
up_proj (up projection): attention層からデータを受け取って、活性化関数(SiLU)を返してdown_projectionに飛ばす層
down_proj (down projection): gate, upから受け取ったデータを処理して次の処理(attention or output)に出力する層
output
lm_head (language modeling head)
テンソル情報をトークン番号に戻すための層
MLPあたりはこちらの記事などを参考に書きました。間違っているかもしれません。
パラメータの内訳
図示した通りで、学習パラメータの約6割がMLP、3割がself-attention、1割がtoken-テンソルの相互変換層に使われいるようです。
昨日は、大規模言語モデルのメカニズムについて文献調査を行い、「全結合層は知識獲得において重要」という研究が報告されていたことを学びました。MLPが一種の辞書(key, value)のような役割?を果たしながら、記憶を獲得しているという仮説が提唱されていました。
仮説の正当性は別としても、言語モデルの6割をMLPが占めているわけですから、MLPが知識獲得において重要なのは、当然と言えそうです。
一方、attention層だけを更新しても、曲がりなりには新情報を学ぶことはできる印象です(学習効率は劣ります)。
いずれにせよ、上記記事でも使っているPEFTライブラリでは、標準でattention層の一部にしかLoRAアダプタを付けない仕様なので、ファインチューニングで知識追加したいケースでは、注意が必要です。
まとめ
これまでに調べてきたことの、個人的まとめです。
Lllama2において、attention層は全パラメータの約3割、MLPは約6割を占める。
パラメータ数の多いMLP層を更新した方が、ファインチューニングでの知識獲得には有利
一方でattention層を更新するだけでも知識獲得できる場合があるので、両者の間で明確な役割分担がなされているわけでは無さそう