大規模言語モデルにおける混合エキスパートモデルの一種 Branch-Train-Merge (BTM)の勉強

はじめに
BTMは大規模言語モデル(LLM)を効率的に訓練・推論する際の有効な手法の一つです。
学習用テキストを専門ごとにN分割
N個のモデルをそれぞれ独立に訓練
全てのモデルをマージして利用
というフローで学習・活用されます。「専門家を集めてAIを作る」というイメージがピッタリの手法です。
有名所だと、Mixture of Experts (MoE)が知られていますが、これはトークンレベルでモデルを入れ替えます。それに対し、BTMは文章レベルで入れ替えるのが大きな違いのようです。
MoEはハードウェアの特性を踏まえた高度なシステム設計が必要になってくる課題があります。
(基本的な背景情報は以下の記事を参照)
本記事では、BTMについて論文を参照しながら掘り下げて行きます。
1. 元祖BTM
LLMとしては以下のプレプリント(2022)が元祖のようです。
データセット分割
N個のモデルを訓練するにあたり、学習用のデータセットをN分割する必要があります。
似たようなジャンルのテキストを集めて分割すると良いとされています。
ランダム分割では精度が出ないようです。
この分割作業どどうやるかが、BTMの難しさのようです。
この論文では、人間が手作業でジャンルを決め、データセットを分割したようです。
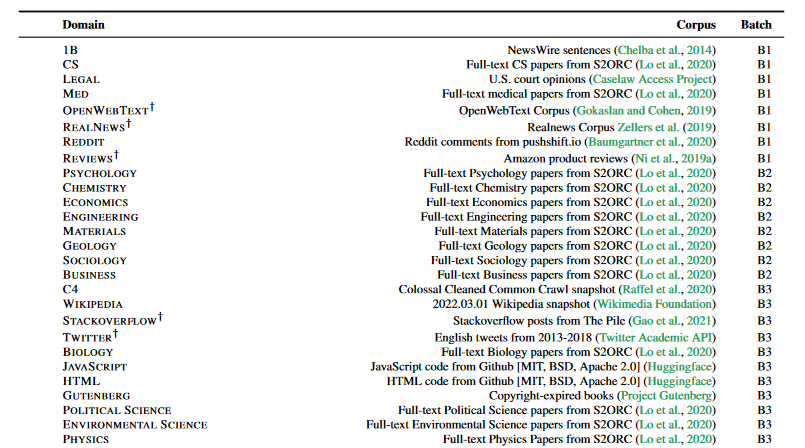
分割したデータセットを各々の独立なモデルで訓練することで、学習が完了します。
モデル活用
モデルの利用段階では、訓練済みの各エキスパートモデルのどれを使うかが、推論性能に直結する大きな課題になります。
あまり深く理解できていないのですが、論文では二通りの方法が提案されていました。
1つ目は、単に出力の平均を利用する方法、
2つ目は、ターゲットとなるテキストと専門モデルの親和性を評価しながら、必要なものをピックアップする方法のようです。
以下、2つ目の手法をGPT-4で要約したものです。
ドメインの考慮:これは、テキストが話題として何についてのものか(例:科学、文学)を見極めることです。各ELM(専門家モデル)は自分の得意な話題についてのテキストを識別しようとします。つまり、テキストを見て、「これは私の専門分野だ!」と判断できるかどうかを各モデルが試みるわけです。
キャッシュされた事前分布の使用:これは、過去のデータを使って、テキストがどの話題についてのものかをより良く判断するための方法です。たとえば、これまでにたくさんの科学関連のテキストを見てきたなら、新しいテキストが科学についてのものである確率を「予測」するのにこの情報を使います。この「予測」は、過去の情報に基づいてテキストがどの話題に属するかを推測するのに役立ちます。
簡単に言えば、たくさんの専門家(ELM)がそれぞれの得意分野を持っており、新しいテキストがどの分野に関連しているかを見分けようとします。そして、過去のデータを利用して、それぞれのテキストがどの分野に最も関連しているかをより正確に判断し、最も適した専門家(ELM)を選ぶのです。これにより、どんなテキストにも柔軟に対応でき、最高の答えを出すことができるわけです。
実装
実装コードはGitHubで公開されています。
fairseqというモジュールを使っている点が気になります。
Fairseqは、seq2seqをターゲットにしたライブラリで、大規模言語モデルが流行る前によく使われていた印象です。
Fairseqは、Facebook AI Researchによって開発されたオープンソースの機械学習ライブラリで、特に自然言語処理(NLP)のためのシーケンス・ツー・シーケンス(seq2seq)モデリングに焦点を当てています。Pythonで書かれており、PyTorchフレームワーク上で動作します。
Fairseqは、機械翻訳、テキスト要約、音声認識など、さまざまなNLPタスクに対応するための効率的で柔軟なモデリングツールを提供します。このライブラリには、Transformerモデルをはじめとする先進的な深層学習アルゴリズムの実装が含まれており、研究者や開発者が最新のNLPモデルを容易にトレーニング、評価、使用できるように設計されています。
2. Cluster-BTM (C-BTM)
元祖BTMではデータセット分割を手動で行いましたが、C-BTMでは分割を自動化するようです。
参考記事も出ています。
データセット
手作業でデータを分割する代わりに、教師なし学習でテキストをクラスタリングするようです。
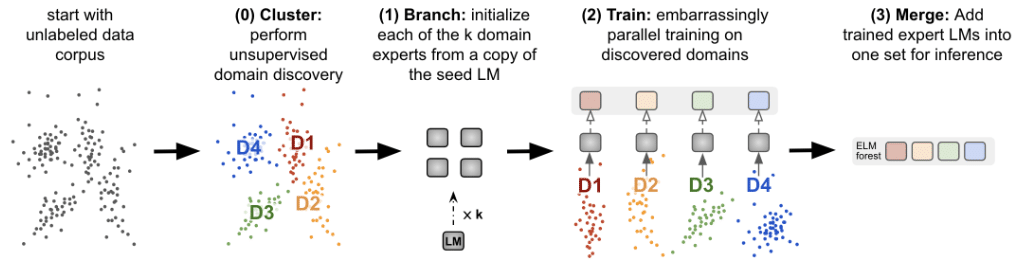
データのクラスタリングについて説明します。各コーパスを、バランスの取れたk-meansクラスタリングを用いてセグメント化します。ここでkは{2, 4, 8, 16, 32, 64, 128}の値を取ります。クラスタリングモデルをトレーニングするために、まず全データをscikit-learnを使用してtf-idfベクトルで埋め込みます。この際、最小限の前提条件として、固定された辞書からのストップワードのみを除去し、数値をダミートークンに置き換えます。次に、結果として得られる埋め込みの次元を削減します。具体的には、100次元での切断されたSVDを実行し、そのベクトルから平均を除去し、単位分散にスケーリングすることで正規化を行います。これは初期の実験でクラスタリングの品質が向上することが観察されました。最後に、これらの表現はカスタムのPytorch実装を使用してクラスタリングされます。学習されたクラスタと可視化は、図4および付録の図Aに示されています。クラスタリングモデルとそのエンベッダーをトレーニングするために、各トレーニングコーパスのシングルシャード(C4の場合は384Kドキュメント、S2ORCの場合は155Kドキュメント)を使用します。このプロセスでは評価データは使用されません。
用語説明
TF-IDFベクトル
TF-IDF(Term Frequency-Inverse Document Frequency)は、テキストデータの特徴抽出に使われる手法の一つで、文書内の単語の重要度を評価します。この手法は以下の2つの概念に基づいています:TF(Term Frequency):単語の出現頻度。文書内における単語の出現回数です。ある単語が文書内に多く出現するほど、その文書にとって重要であると考えられます。
IDF(Inverse Document Frequency):逆文書頻度。ある単語がどれだけの文書に珍しく出現するかを示します。全文書中で少数の文書にしか出現しない単語ほど、IDF値は高くなり、その単語の重要度が高いと考えられます。
TFとIDFの値を掛け合わせることで、TF-IDF値が算出されます。この値が高い単語ほど、文書内で重要な単語とみなされます。TF-IDFベクトルは、文書を単語の重要度に基づいてベクトル空間にマッピングすることを可能にし、機械学習モデルでのテキスト処理において広く使用されています。
SVD(特異値分解)
SVD(Singular Value Decomposition)は、行列を特定の構成要素に分解する一種の行列分解手法です。具体的には、任意の行列AAを3つの特定の行列の積に分解します:A=UΣV∗A=UΣV∗。ここで、UUとVVは直交行列であり、ΣΣは対角行列です。この対角行列には特異値と呼ばれる値が含まれており、これらは行列AAの重要な特性を捉えます。
SVDは、データの次元削減、ノイズの除去、データの圧縮など、さまざまな用途に使用されます。テキストデータや他の種類の高次元データにおいて、SVDを利用することで、データの本質的な構造を抽出し、計算の複雑さを低減することができます。
切断されたSVD(Truncated SVD)は、SVDの一種であり、特異値のうち最も大きいものからいくつかを選んで、元の行列を近似する方法です。これにより、元のデータの重要な特徴を保持しつつ、データの次元を効果的に削減することが可能になります。文書や単語のベクトル空間モデルにおいて、Truncated SVDを使用することで、計算効率を上げ、データの扱いやすさを向上させることができます。
単語レベルのクラスタリングですが、それでもわりとジャンル分けできるようです。

推論
ちゃんと読んでませんが、クラスタリングアルゴリズムを使って学習させるモデルを割り振るようです。
スパースアンサンブルによる推論では、複数の専門家モデル(Expert Language Models, ELMs)からなるアンサンブルを効率的に活用して、新しい入力に対する予測を行います。このプロセスは、すべてのELMを毎回活性化するのではなく、入力コンテキストに基づいて最も適切な少数のELMを選択して活性化します。以下に、スパースアンサンブルによる推論の一般的なアルゴリズムを簡単に説明します。
ステップ 1: 入力のクラスタリング入力テキストを、事前にトレーニングされたクラスタリングモデル(例えばk-means)を使って、特定のクラスタに割り当てます。このクラスタは、特定のドメインやトピックに関連する文書のグループを表すことができます。
ステップ 2: 適切なELMの選択入力テキストが割り当てられたクラスタに基づいて、そのクラスタを専門とする1つ以上のELMを選択します。選択プロセスには、クラスタとELMの間の事前のマッピング情報や、ELMのパフォーマンスメトリクスが使用されることがあります。
ステップ 3: スパースアンサンブルの形成選択されたELMを活性化し、それらの出力を組み合わせて最終的な予測を形成します。出力の組み合わせ方には、単純な平均化、加重平均、またはより複雑な統合方法が含まれることがあります。加重平均の場合、各ELMの重みはその信頼度や以前のパフォーマンスに基づいて決定されることがあります。
ステップ 4: 推論の実行形成されたスパースアンサンブルを使用して、入力テキストに対する推論(例えば、次の単語の予測、テキストの分類など)を実行します。
このアプローチの利点は、計算資源の効率的な使用と、特定のクラスタやドメインに特化したモデルの専門知識を活用できる点にあります。これにより、大規模な一般モデルよりも高い精度やパフォーマンスを達成することが可能になります。また、新しい入力に対して最も関連性の高い知識を持つモデルのみを活用することで、より関連性の高い、質の高い予測を提供することができます。
結果
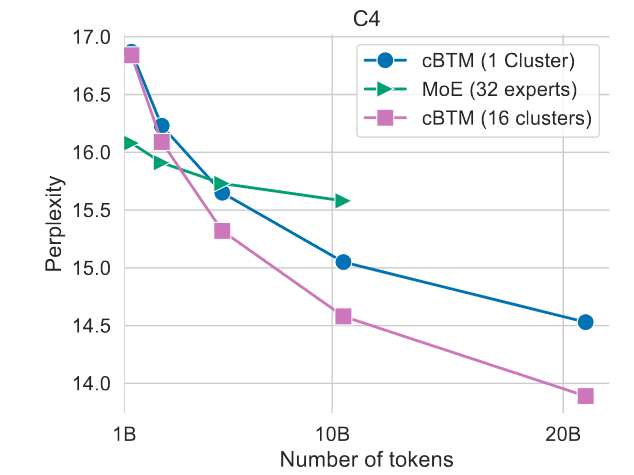
MoEよりも良いそうです。
実装
metaseqというライブラリを使うようです。
metaseqとfairseqはどちらもFacebook AI Research(FAIR)によって開発された深層学習フレームワークで、特に自然言語処理(NLP)タスクやシーケンスモデリングのためのものです。両者は共通の目的を持っていますが、主に以下の点で違いがあります。
fairseq公開時期: fairseqは以前から存在しているフレームワークで、オープンソースコミュニティに広く受け入れられています。
目的と機能: fairseqは、機械翻訳、文書要約、音声認識など、多様なNLPタスクに対応するための包括的なライブラリです。効率的なトレーニングと推論のための高度な機能を提供し、研究者や開発者が最先端のNLPモデルを簡単に実装、試験、適用できるように設計されています。
コミュニティとサポート: fairseqは広範なドキュメント、チュートリアル、プリトレーニングされたモデルが公開されており、オープンソースコミュニティによる活発な開発とサポートがあります。
metaseq公開時期: metaseqはfairseqに基づいて開発された比較的新しいフレームワークで、特定のプロジェクトや実験のために特化された機能や改善が加えられています。
目的と機能: metaseqは、fairseqのコア機能に加えて、特定の要件や最新の研究成果を反映した新機能や最適化が施されている場合があります。たとえば、特定のモデルアーキテクチャのサポートや、実験的な機能が含まれていることがあります。
コミュニティとサポート: metaseqはfairseqに比べてコミュニティが小さく、また特定のプロジェクトや目的に合わせて開発されたため、一般的な使用や広範なサポートにはfairseqが適している可能性があります。
metaseqとfairseqの違いは主に、両者がターゲットとするユーザーや使用シナリオにあります。fairseqは幅広いNLPタスクと一般的な使用に向けた堅牢なフレームワークであり、metaseqは特定のニーズや最新の研究成果を迅速に取り入れたいユーザー向けのフレームワークです。どちらを使用するかは、プロジェクトの要件や個人の好みによって異なります。
このあたりのライブラリ、あまり馴染みがないので、勉強が必要そうです。
まとめと考察
BTMの勉強をしました。トークンごとにタスクの振り分けが必要なMoEに対し、テキストごとにエキスパートモデルを割り当てるBTMは、並列計算性に優れているようです。2つの論文を読みました。
テキスト分割の方法について
1つ目の論文では、手作業で学習用テキストを分割する手法、2つ目の論文では、単語の類似度をもとに文章を自動クラスタリングする手法が適用されました。
文章の分割法としては、自動クラスタリング(後者)の方がスマートな気もしますが、なんだかんだで手作業(前者)の方が、使い勝手が良いかもしれません。
自動分割の利点
スケーラビリティが高い
属人性が低い
マニュアル分割の利点
言語モデルの基本は人間の好みに合う応答をさせることなので、人間の意図に沿ったドメイン分割の方が高性能を出せる可能性がある
例えば、日英のテキストが混在する場合、単純な単語ベースのナイーブなクラスタリングだと、「日本語の法律文書と俳句」と「英語の法律文書と俳句」のような感じで、ジャンルではなく言語が優先されて分割される恐れがありそうです。
モデル統合(ルーティング)のアルゴリズムについて
実際の推論時に、どのエキスパートモデルを用いるかが課題になっています。
提案されていた手法は、、
各モデルの出力の平均を取る
各モデルとテキストの親和性を見る
教師なし学習(クラスタリング)を使う
のようでした。
普通のMoEでは、もっとニューラルネットなどを用いた、もっと高度なタスク振り分け(ルーティング)を行っている印象です。このあたりは、色々と改善の余地がありそうです。
実装コードについて
実装面では、どちらも著者がMetaということで、fairseq, metaseqという、自分にはあまり馴染みのなかったライブラリを使っている点が気になりました。