大規模言語モデルの設計について、scaling lawやアンサンブルをキーワードに考える勉強メモ

はじめに
大規模言語モデルを作ろうと思った時に、どういう選択肢があるか、特徴や課題について調べたメモです。分野を網羅しているというわけでは全くありません。
どのモデルを使うべきか?
学習を行う上で大切な指標の一つは、計算効率です*。
限られたリソース(FLOP数)で最大限の学習効果を得ることが目的です。
この観点から、本記事では様々なモデルの計算効率を見ていきます。
*計算効率以外にも、推論速度や必要メモリなど、諸々の要素はあります。
Scaling lawに基づく比較
Scaling lawとは?
機械学習におけるスケーリング則(scaling law)とは、モデルの性能がそのサイズ、訓練データの量、または計算資源の増加に伴ってどのように変化するかを定量的に記述した法則です。
計算結果の比較
モデルの学習効率を見るにあたって、FLOPsあたりの誤差を見ていくことが重要と言えます。
モデル毎に効率を比較した論文(サイトA,B)があったので、見てみます。
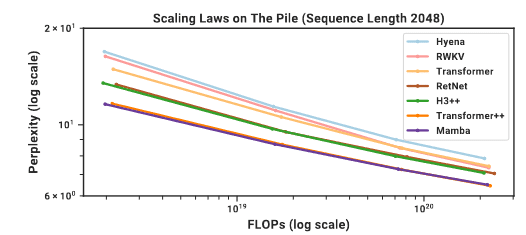
Hyena
計算コストが低くて高速なことが特徴なモデルのようです。入力トークン数も多い模様。ただし、今回の比較ではworstな効率となりました。
RWKV
ある意味では古典的とも言える、再帰ニューラルネットワークを使った実装です。こちらも高速なのが特長ですが、FLOPs効率は相対的に劣るようです。
Transformer/ Transformer++
大規模言語モデルにおける定番のアルゴリズムです。Transformer++は、諸々を最適化したベストプラクティスのようです。ほぼ最高性能を示しています。実施例もたくさんあるので、やはり、こちらが現状の定番のアルゴリズムと言えそうです。
ResNet, H3++
あまり詳しくはわかりませんが、Transformerの後継・亜種のようです。
Mamba
2023年の末頃から流行っているモデルのようで、attentionはMLPからの脱却を狙っているとのこと。
Tramsformer++と同等あるいはそれ以上の性能を示すことから、選択肢としては有りかもしれません。
ただし、上記のグラフはMambaを推す論文であり、多角的な視点からの検証はこれからという印象です(特にモデルを大きくしたときの挙動)。
まとめ
モデルを使用するユーザーの立場からすると、とりあえずはTransformerベースのアルゴリズムがまだ手堅い印象です。
Mixture of Experts (MoE)はどうか?
MoEとは?
Mixture of Experts (MoE)は、大規模言語モデルをより効率的に、かつパフォーマンスを向上させるための技術です。大規模言語モデル、特にGPT-3やGPT-4のようなモデルは、数十億から数千億パラメータを持ち、莫大な計算リソースを消費します。MoEはこの問題に対処するための一つのアプローチで、モデルの柔軟性とスケーラビリティを高めることができます。
こちらの動画がとても参考になりました。以下の内容は、ほぼ受け売りです。
総合的なモデルサイズは大きいけれど、実際の訓練は個々のモデルなので、計算コストを下げられる、というのが利点のようです。
Switch Transformers
MoEというアイデアは昔からあったようですが、transformerで検討され始めたのは、わりと最近のようです。
定番の論文はこちら(引用回数>1000, 2021年)。
学習効率の比較結果は以下の表になります。
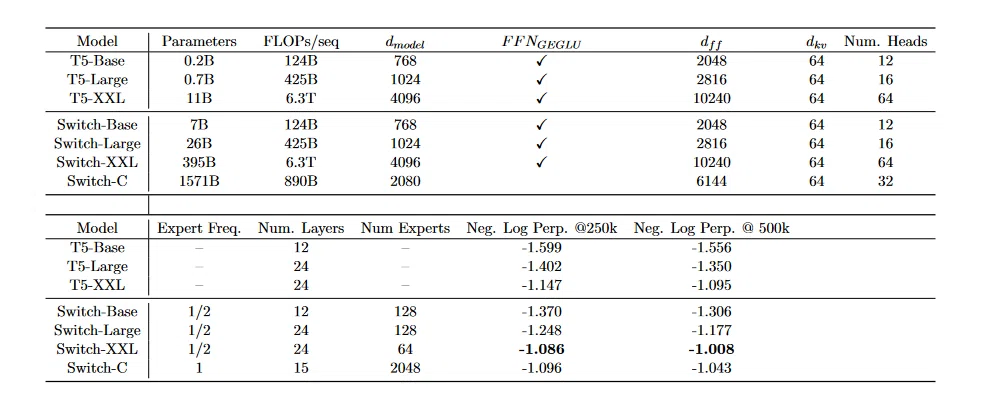
わかりにくいですが、こちらの動画(16:35付近)によると、ポイントは、
MoEで7B相当(55m x 128)のモデルを作ってみたところ、通常モデルの0.2, 0.7Bと同等程度の学習時間 & より優れた推論性能を出せた
とのことです。すごいですね。
Mixtral
最近のMoEと言えば、GPT-4(あくまで噂)や、Mixtralが有名です。どちらも高性能です。
MoEの難しさは?
良いとこ取りのMoEですが、学習が結構難しいようです。主な課題は以下の通り。
学習が安定しにくい
学習中にLossが急上昇する確率が相対的に高い
システム構築が高難度
分散学習が基本となります
通信のボトルネックなども真面目に考える必要が出てくるようです
特定のモデルにタスクが振られすぎると、並列学習の旨味が激減
前者については、特定のモデルを自動選択するというタスク(離散最適化)のチューニングが難しそうな印象です。そのあたりを解決しようとする試みも提案され始めています。
後者はわりと難題で、現状では、ハードウェアのクセや特徴もきちんと把握した上で、学習システムを設計する必要があるようです。まだbest practiceが無く、素人にはキツイ印象です。
Branch-Train-Merge (BTM)
BTMとは?
こちらは聞き慣れない方も多いかもしれませんが、実はこちらが、一般人が想像する「エキスパートモデルの混合」な気がします。
MixtralなどのMoEでは、tokenレベルで逐一、タスクの振り分けをする学習をします。その結果、token毎に用いられるexpertが入り乱れて変化することになります。

これに対し、BTMでは、データセット毎にexpertを用意し、統合するようです。
イメージとしては、英語データセットを学んだモデル、日本語データを学んだモデル、などを独立に作り、最後に合体する感じのようです。
基本的に、モデル毎に独立にトレーニングを行う感じなので、分散学習システムの構築の難易度も低そうです。
BTMの定義by GPT-4
Branch-Train-Merge (BTM) は、大規模なニューラルネットワークモデル、特に自然言語処理(NLP)や画像認識などの分野で使用されるモデルのトレーニングを効率化するためのアプローチです。この方法は、大きなモデルを分散して並列に訓練し、その後、学習した知識を統合するプロセスに焦点を当てています。具体的には、以下の三つの主要なステップから成り立っています。
1. Branch(分岐)
このステップでは、大規模モデルを複数の小さなサブモデル(または「ブランチ」)に分割します。この分割は、モデルの異なるセクションを異なるデータセットやタスクで独立して訓練することを可能にし、トレーニングの柔軟性と効率性を高めます。
2. Train(訓練)
各ブランチは独立して訓練されます。このプロセスでは、各サブモデルが特定のデータセットまたはタスクに対して最適化され、異なる計算リソースや訓練戦略を活用することができます。これにより、リソースの使用を最適化し、全体としてのトレーニング時間を短縮することが可能になります。
3. Merge(統合)
最後のステップでは、独立して訓練されたブランチを統合して、元の大規模モデルを再構築します。この統合プロセスでは、各ブランチから学習された知識を組み合わせ、全体としてのモデルのパフォーマンスを向上させます。このステップは、異なるブランチ間で知識を効果的に転移させることが重要であり、全体のモデルが一貫性を保ちつつ、各サブモデルの特性を活かすことが求められます。
BTMアプローチは、特に大規模モデルのトレーニングにおいて計算コストと時間を削減するために有効です。しかし、適切な分割戦略の選択、ブランチ間での知識の統合方法、および全体のコヒーレンスを保つための調整は、このアプローチの成功において重要な課題となります。BTMは、モデルのスケーラビリティを向上させ、より大きなモデルをより効率的に訓練するための有望な手法と考えられています。
学習結果の例
こちらのプレプリントの学習結果を引用します。斜め読みなので間違っているかもしれません。
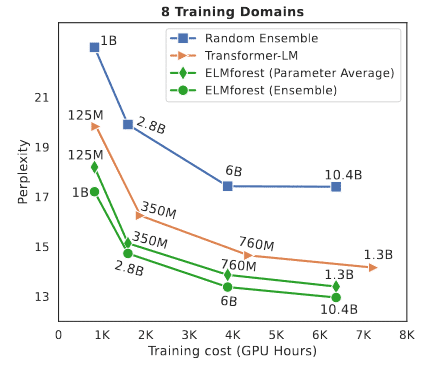
緑の丸:ドメインごとに学習させたモデルをうまくアンサンブルしたもの。
緑のひし形: 上記モデルの平均(?)をとったもの
Transformer: 普通のtransformer (コントロール)
青: ランダムにデータセットを分割して訓練、アンサンブルしたもの
上記の結果は、適切に学習システムを組めば、同じ計算時間で1.3B→10.4B相当のモデルを作れそうなことを示唆しています。
ただし、ドメインごとのデータセットの分割が鍵のようで、ランダムに分けるだけでは、逆に精度が落ちるようです。
疑問
これから勉強すべき事項 (わかる方いたら、教えてください)
モデルを訓練した後、タスクを振り分ける作業(ルーティング)はどのように学習させるのか
データセットの分割方法はどうしたらよいか
結局、モデルがわりと独立に動くことになるので、創発(emergent)を含めた「モデルの賢さ」が、どのような影響を受けるのかがいまいちわからない
わりと筋の良さそうなアプローチだが、あまり流行ってないのはなぜか?
データセット分割が属人的だから?
まとめ
大規模言語モデルを作るためのアルゴリズム指針について調べました。
諸々のアルゴリズムが出ているものの、やはりtransformerが性能・実績的にbest practiceな印象でした。
計算リソースが限られる場合、MoEやBTMはかなり効果的な印象がある一方で、実装難易度も上がるようです。
引き続き、勉強していきます。
この記事が気に入ったらサポートをしてみませんか?