Llama2を「化学物性+言語」データセットでファインチューニングして融点を予測させる

2024/1/4
ファインチューニングの結果を追記しました。
こちらの続きです。
はじめに
既存のケモ・マテリアルズインフォマティクスは基本的に言語モデルを使いません。
そのような特化型モデルは、予測過程が人間に分かりづらかったり、科学的にはありえないロジックで推論してしまうデメリットがありえます。
なので、大規模言語モデルに物事を考えさせる研究を進めています。


前回までに、GPT-4を用いて「質問(分子構造)」ー「答え(融点)」のデータセットから「理由」を生成しました。 「質問」+「理由」でプロンプトチューニングすると、予測精度が上がるかも?という兆候が出ました。
実装はこちら
ファインチューニング
データセットは鋭意生成中ですが、既に500件ほどは溜まったので、試しに、llama2でファインチューニングしてみようと思います。
実装コードはこちら。(そのうち、google colabで動かせるようにしたいです)
データセット
まずは試しということで、適当に選んだ10件をテストデータ、残りを訓練データとします。
訓練データは以下のような感じです。

モデル類
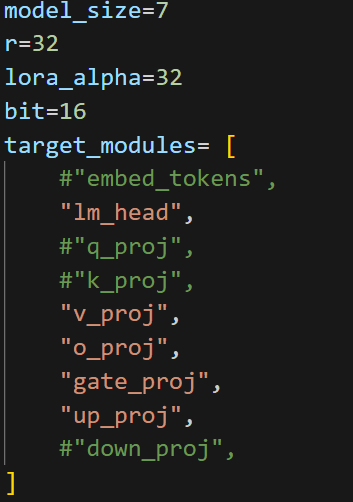
とりあえずLlama2-chat-7bを使いました。
16 bitでモデルを動かし、LoRA (r=32)でアダプターをつけています。
学習率は適当に10^-5, epoch=3です。
アダプター層は少し工夫しています。
LoRAについては、これまで色々と最適化してきました。以下の研究を参照。
VRAMは20GBほど使いました。4-bitにすると半分以下になると思います。
3分ほどで学習は終了。
推論結果
ランダムに選んだ3件のデータでプロンプトチューニングしておきました。これは、定型的にReasonとPredictionを生成させる目的です。
オリジナルのLlama2
10件のデータを予測させたのですが、きちんと数値を出力してくれないことが多く、半分以上は回答がNaNでした。
ファインチューニングしたモデル
一目瞭然、予測精度が上がりました。素晴らしい!

2024/1/4追記: ファインチューニングの追加検討
追記: 1/8データを修正
執筆時点で、2.5kほどの理由付きデータが生成されたので、もう少しまじめにファインチューニングを行ってみました。
[条件詳細] ベースモデル = Llama2-7b
LoRA: r=32, alpha=32, lr=10-5, epoch=2
layers=lm_head, v_proj, o_proj, gate_proj, up_proj
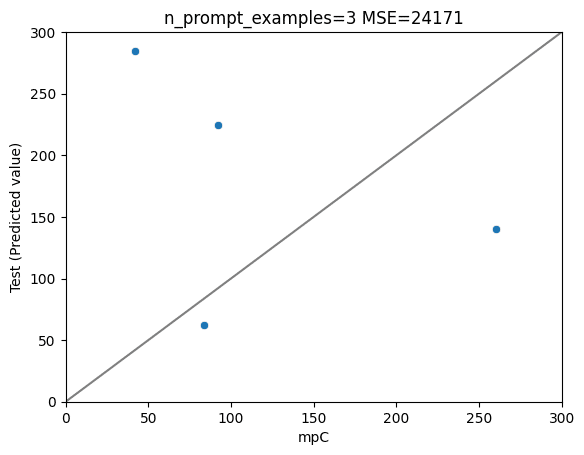
2.5kほどのデータを訓練、ランダムに選んだ50件を試験データとしました。
(推論に時間がかかるので、テストデータは少なくしています)
予測結果は以下の通り。

ファインチューニングを経て、平均予測誤差(MAE)を半分くらいまで減らすことができました。
Google Colabのコードも一応作りました。
が、無料のT4 GPUだと、7b (4-bit)条件でも、推論時にout of memoryになってしまいました。一旦ランタイムをリセットして、オプティマイザのメモリを開放するなどの工夫をすれば、動かせるとは思います。
プロントチューニングやハイパラを最適化すれば、もっと予測精度は上がる見込みです。もし、もっと良いコード実装や予測性能を出せた方がいたら、教えていただけると大変ありがたいです。
(謝礼を出すのは難しそうですが、論文中の謝辞などには載せられる見込みです)
Discordサーバーでも活動しています。
今後のTODO
コンセプトを実証はできたので、今後は作り込みなどをしていく必要があります。
データセットの拡充(25kのうち2.5k完了)
プロンプトチューニング/ファインチューニングの条件最適化
モデルを大きくするetc
なぜ/本当に精度が上がったのかなどの学問的な解析
定量的、統計的な比較
など。