GPT-4o(Claude)に危険物取扱者試験(甲種試験)を解かせてみる-その9: 様々なモデルの性能比較と感想

はじめに
大規模言語モデルに危険物取扱者試験(甲種試験)を解かせて合格させるという試みを行ってきました。
前回までの検討で、Claude-3.5-sonnetを使いつつ、試験対策本の類題でRAGを行えば、この資格試験の過去問でほぼ満点を取れることが分かりました。
本記事では、Claude-3.5-sonnet以外のモデルで同じ検証を行い、各モデルの地頭と読解力を検証します。
また、今後のモデル開発について思ったことについても、感想文を書きました(記事の最後)。
検証条件
データ
試験問題: 資格の公式サイトで配布されている過去問
RAGデータ: 試験対策本から抜き出した約600問の問題・回答・解説
解きたい問題にembedding vectorで近い10問を参照させる
典型的なプロンプト
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "あなたは誠実で優秀な日本人のアシスタントです。"},
{"role": "user", "content": "次の選択式問題に日本語で回答しなさい。回答について一つ一つ吟味し、最後に#回答 として選択肢番号のみを出力しなさい。必要に応じ、類題を参照してもよい。\n"+q}, #qは問題文
],
)モデル
以下のChatBot Arena日本語版で運用しているモデルを中心に検証しました。
'llama-405b', 'openai-o1', 'gemma-27b', 'calm3-22b', 'llama-70b-nemotron', 'swallow-70b', 'claude-sonnet', 'deepseek', 'qwen72b', 'openai-o1-mini', 'gpt4o', 'tanuki-8b', 'claude-haiku', 'tanuki-8x8b', 'gpt4o-mini', 'swallow-8b'
・ローカルモデルは4-8 bitに量子化して運用しました。
・api系のモデルは最新版を使用しました。
・gemini系は課金しておらず、無料枠では足りなかったので検証しませんでした(経験上、GPT-4oと同等orやや劣る程度の性能と推定されます)。
採点
当該試験は、選択肢番号を答える問題になっています。一部のローカルモデルは指示を守った定型出力をするのが苦手なので、半手動で採点しました。
結果
正答率は以下の通りになりました。

モデルをグループ分けして、考察していきます。
ほぼ完答できる: openai-o1, claude-3.5-sonnet
文献を参照しない状態でも80%程度の正答率を出しています。日本特有の法律に関する問題が多く含まれていることを鑑みると、かなり高い正答率です。
RAGを行った場合の正答率は90%以上でした。
誤答した問題は、過去問には含まれていない日本固有の法令知識に関する問いで、丁寧にRAG用のデータベースを設計すれば、おそらく100%の正答率は出せるだろうという手応えは得られています。
総じて、実用展開を目指せそうなレベル感です。
知識はトップレベルだが情報処理力がいまいち: GPT-4o
GPT4oとClaude-3.5-sonnetの地頭での正答率はどちらも80%程度でしたが、前者はRAGを行った際の正答率が伸び悩みました。
各問題ごとの正解・不正解を見てみると、GPT-4oの性能が伸び悩んだ理由が分かります。
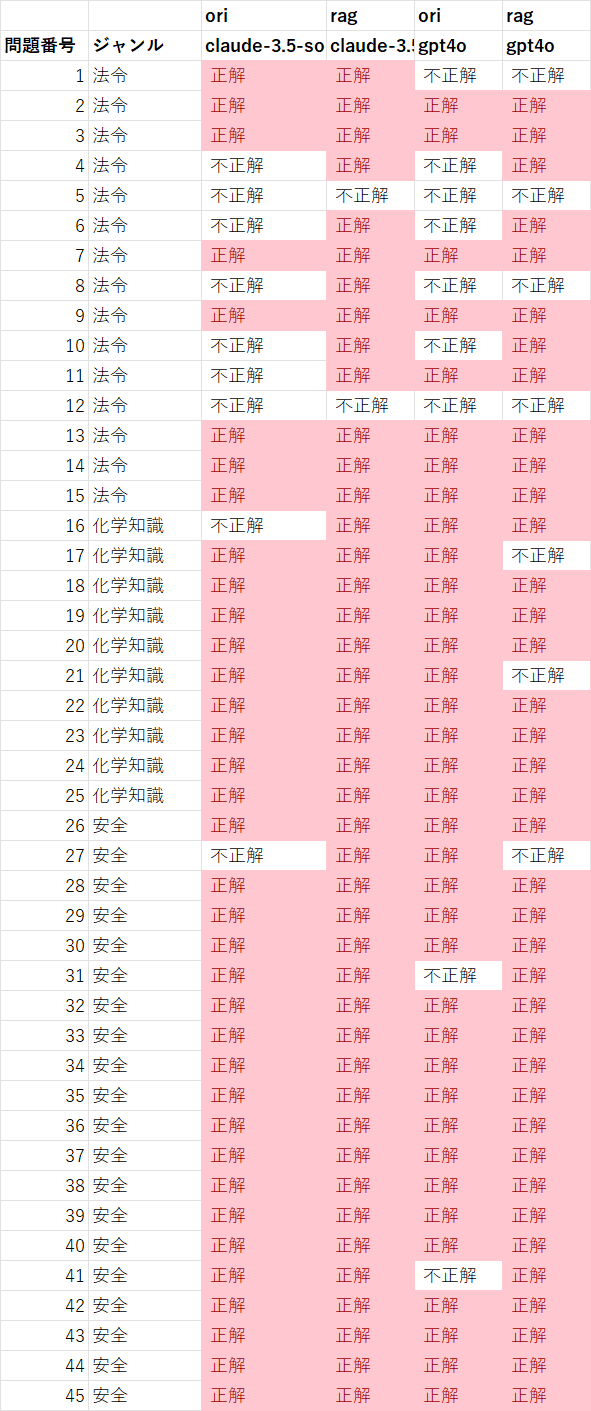
Claude-3.5-sonnetは、弱みがあった法令関連の知識をRAGによって補うことで、大幅な成績向上を実現できました。
GPT-4oも同様に、法令関連の正答率は向上しています(ただし向上率はClaudeにやや劣る)。
最大の問題点は、もともと正解していた問題について、RAGを行った際に誤答するようになったことです(問17、21、27)。GPT-4oが、本来は参照すべきでない情報に流されてしまい、判断を誤った可能性がありそうです。
知識はイマイチだが情報処理力が高い: openai-o1-mini
熟考が売りのこのモデルは、軽量化されているため地頭での正答率が低いですが、文献を参照した際のスコアの伸びが顕著でした。
openai-o1-previewと同様、モデルの情報処理・思考力を高めることがRAGには重要そうです。
ボーダーライン: deepseek-236B, qwen2.5-72b, gpt-4o-mini, claude-haiku, llama-3.1-405b
危険物取扱者試験の合格ラインである正答率60%付近のモデル群です。
RAGによる性能向上の効果も限定的でした。
こうした挙動を鑑みると、
・GPT4o, openai-o1, Claude-3.5-sonnetなどのフロンティアモデルは、パラメータ数が1000 Bを超えており、
・最高水準の性能を出すためには、現状、1000 B程度のモデルサイズが必要で、
・各社の軽量モデル(mini, flash, haiku)は、数十ー数百B程度のパラメータ数
ではないか、という推測をしたくなります。
蛇足ながら、中学数学の問題を解かせたときも、モデルサイズという「壁の存在」を感じました。
残念ながら落第レベル: llama-70b-nemotron, llama-3.1-swallow-8/70b, calm3-22b, gemma-27b, tanuki-8/8x8b
これらのモデルは、合格ラインの60%を下回り気味でした。
大きな問題点は、RAGをしたときの性能向上がほぼ無い/逆に悪化してしまったという点です。
数十B程度のパラメータ帯であっても、Qwen-2.5-72Bは地頭&RAGの能力で健闘していますので、この情報処理力の不足は、学習データの課題と理解できそうです。
あまり種類は試せてませんが、10B以下のモデルは、専門知識&RAGで相当な学習をさせておかないと、殆どまともに動かなそうな手応えでした。
終わりに: 最近のモデル開発に関する感想
最近はモデルの小型化・ローカルモデルに関する研究開発が花盛りで、おそらくはエッジデバイス/それっぽく喋るチャットボットなどへの展開などで、今後も継続的な性能向上も見込めそうです。
一方、精度を含めた総合力という視点では、いまのところ、フロンティアモデル(パラメータ数>1000B? & 極めて洗練された学習データ)に歴然たる強みがあります。
今回のような専門領域について言えば、Claude-3.5-sonnetやOpenai-o1のような情報処理力の高いモデルの出現により、
「ドメイン・専門特化の小中型モデルを作る」という生き残り戦略に対して、「巨大なフロンティアモデル + RAG + (エージェント)」(≒何でもできる「基盤モデル」)というオルタナティブが出てきてしまった印象です。
少なくともエンドユーザーにとっては、素朴に考えて、後者の方が安価・便利・最先端の情報を組み込みやすい利点があります。
ローカルモデルの生き残り策の一つとして、Claude-3.5-sonnet / Openai-o1並に情報処理力の高いモデルを小型で作れれば、推論コストの低さを活かしたエージェント(推論のスケーリング則)の活躍の余地はあるかもしれません。
ただし、openai-o1-mini程度の知識・情報処理力では、ちょっと精度不足な印象でしたので、まだまだチャレンジングな領域です。
ーーー
最近の孫正義さんの言葉が、改めて印象的でした。
ローカルモデルは自身も触っているので、自戒も込めて、直視しつつ、役割について再考する必要がありそうです。
"競争社会では「一番優れた叡智」に圧倒的価値がある"
…
よく「日本的な生成AIを作るんだ」「我が社製」とかいろいろ言って、「日本製だから工夫をしよう」と。工夫をするということは、このパラメーターの数を少なくして、ほぼ似たような成果を出すようにしようとということです。
…
こういう努力をして「いや、少ないパラメーター数にすると電気があんまり要らなくなるんだ」「チップの数があんまり要らなくなるんだ」「だから効率が良いんだ」という努力を、小さくて美しい努力だ、日本的だという主張をする人がたくさんいるんですが、僕に言わせればそれは言い訳です。
…
我々人間の社会、企業はみな競争していますから、競争の中では一番優れた叡智、一番優れた機能、そこに圧倒的価値が寄せられるということであります。