llama2のファインチューニング(QLORA)のメモ

2023/11/13追記
以下の記事は、Llama2が公開されて数日後に書いた内容です。
公開から数ヶ月経った23年11月時点では、諸々の洗練された方法が出てきていますので、そちらも参照されることをおすすめします。
(以下、元記事です)
話題のLamma2をファインチューニングします。
QLoRAライブラリを使うパターンと、公式推奨の2つを試しました。前者が個人的にはオススメです。
前提
Hugging faceで配布されている公式のモデルが必要です。以下を参考に、ダウンロードしておきます。
手段1. QLoRAライブラリを使用
こちらを参考に、QLoRA周りをセッティングします。
データセット作成
(7/20 15:20追記 設定ミスってたので修正しました)
test.jsonを適当に作ります。
[
{
"input": "",
"output": "### Human: 富士山といえば?### Assistant: なすび"
},
{
"input": "",
"output": "### Human: 明日の天気は?### Assistant: 雪"
},
{
"input": "",
"output": "### Human: 東京といえば?### Assistant: 神田川"
},
{
"input": "",
"output": "### Human: AIといえば?### Assistant: Llama2"
}
]学習コードを実行します。パラメータは適当です。
model_name=meta-llama/Llama-2-7b-chat-hf
dataset_name=dataset/json/test.json
python qlora.py \
--model_name $model_name \
--output_dir ./output/test\
--dataset $dataset_name \
--dataset_format input-output\
--max_steps 1000 \
--use_auth \
--logging_steps 10 \
--save_strategy steps \
--data_seed 42 \
--save_steps 50 \
--save_total_limit 40 \
--dataloader_num_workers 1 \
--group_by_length \
--logging_strategy steps \
--remove_unused_columns False \
--do_train \
--lora_r 64 \
--lora_alpha 16 \
--lora_modules all \
--double_quant \
--quant_type nf4 \
--bf16 \
--bits 4 \
--warmup_ratio 0.03 \
--lr_scheduler_type constant \
--gradient_checkpointing \
--source_max_len 16 \
--target_max_len 4096 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--eval_steps 187 \
--learning_rate 0.0002 \
--adam_beta2 0.999 \
--max_grad_norm 0.3 \
--lora_dropout 0.1 \
--weight_decay 0.0 \
--seed 0 \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2重要なパラメータは以下の通りです。
model_name : モデル名
output_dir : LoRA重みの保存先
dataset : データセットのパス
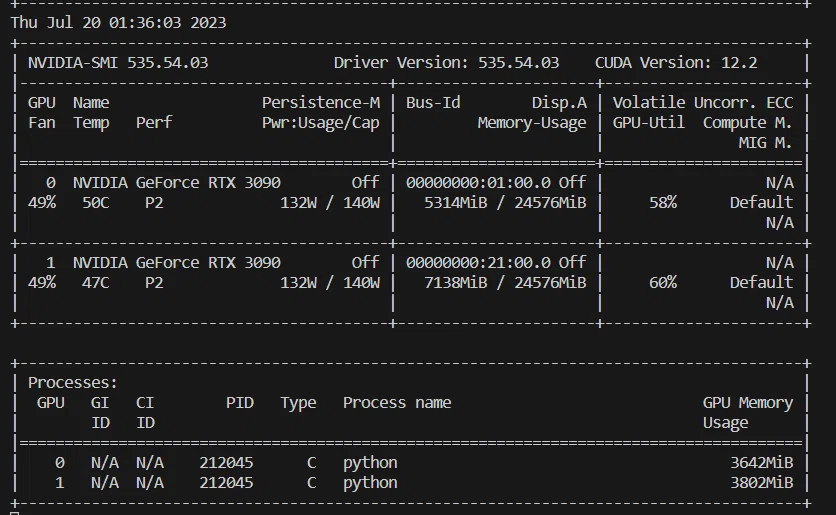
VRAM使用量の概算
1バッチあたり、7b / 2 (by 量子化) =3.5 GB
今回はbatch size=4なので、4倍して、3.5x4=14GB程度 となります。
推論
元のモデルの読み込み
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
#load base model
model_id = "meta-llama/Llama-2-7b-chat-hf"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})LoRA重みの追加
#LoRAのパスを指定
peft_name = "/output/test/checkpoint-50/adapter_model/"
model = PeftModel.from_pretrained(
model,
peft_name,
device_map={"":0}
)
model.eval()テキスト生成
device = "cuda:0"
def ask(text):
inputs = tokenizer(text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
text = "### Human: 富士山といえば ### Assistant: "
ask(text)
text = "### Human: 明日の天気は ### Assistant: "
ask(text)
text = "### Human: AIといえば ### Assistant: "
ask(text)出力の確認
学習前

学習後

13, 70bの訓練(7/21追記)
追加設定が必要です。
qlora.pyの647行目の下に、次のコードを加えればOKです。
model.config.pretraining_tp = 1 #追加!
それ以外は基本、同じです(コードを追記したファイルをqlora_4bit.pyとしました)。
model_name=meta-llama/Llama-2-70b-chat-hf
dataset_name=dataset/json/test.json
out_dir=output/test
python qlora_4bit.py \
--model_name $model_name \
--output_dir $out_dir\
--dataset $dataset_name \
--dataset_format input-output\
--max_steps 300 \
--use_auth \
--logging_steps 10 \
--save_strategy steps \
--data_seed 42 \
--save_steps 10 \
--save_total_limit 40 \
--dataloader_num_workers 1 \
--group_by_length \
--logging_strategy steps \
--remove_unused_columns False \
--do_train \
--lora_r 64 \
--lora_alpha 16 \
--lora_modules all \
--double_quant \
--quant_type nf4 \
--bf16 \
--bits 4 \
--warmup_ratio 0.03 \
--lr_scheduler_type constant \
--gradient_checkpointing \
--source_max_len 16 \
--target_max_len 4096 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--learning_rate 0.0002 \
--adam_beta2 0.999 \
--max_grad_norm 0.3 \
--lora_dropout 0.1 \
--weight_decay 0.0 \
--seed 0 \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2
70bの学習の様子
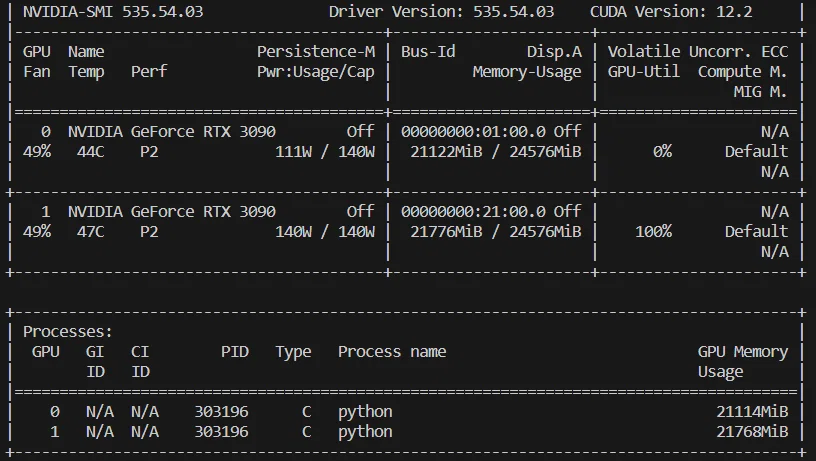
(メモ: 24GB x2のVRAMでは、target_max_len = 768 with batch_size=4あたりがVRAMの限界でした。max_lenがそれ以上大きいと、memory errorが出やすいです。今回のサンプルはtarget_max_len = 4096となってますが、文章が短いので、実質的にはtarget_max_len = 20くらいです)
保存されるアダプターモデルのサイズは1.6GBでした。流石の70bです。
70bでの推論
こちらもモデル読み込みに追加設定が必要です。
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from transformers import AutoConfig
model_id = "meta-llama/Llama-2-70b-chat-hf"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
config = AutoConfig.from_pretrained(model_id)
config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config,
device_map="auto")残りは今までと同じです。checkpoint-2を読み込んでみます。
今回の環境では、以下のコードの実行に5分以上を要しました。
peft_name="output/0720test70b/checkpoint-2/adapter_model"
model = PeftModel.from_pretrained(
model,
peft_name,
device_map="auto"
)
model.eval()推論
device = "cuda:0"
def ask(text):
inputs = tokenizer(text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
text = "### Human: 富士山といえば ### Assistant: "
ask(text)
text = "### Human: 明日の天気は ### Assistant: "
ask(text)
text = "### Human: AIといえば ### Assistant: "
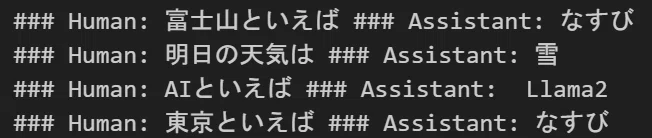
ask(text)10step後の学習結果はこちら。70bモデルもうまく洗脳できました(4問目以外)。
手段2. 公式のやり方
公式のとおりにやってみます。
以下、7b-chatの例となります。
ライブラリのクローン
pip install trl
git clone https://github.com/lvwerra/trl
cd trl
pip install -e .サンプルスクリプトの実行
(学習はwandbの使用が前提のようなので、適当に登録します)
python examples/scripts/sft_trainer.py \
--model_name meta-llama/Llama-2-7b-chat-hf \
--dataset_name timdettmers/openassistant-guanaco \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2
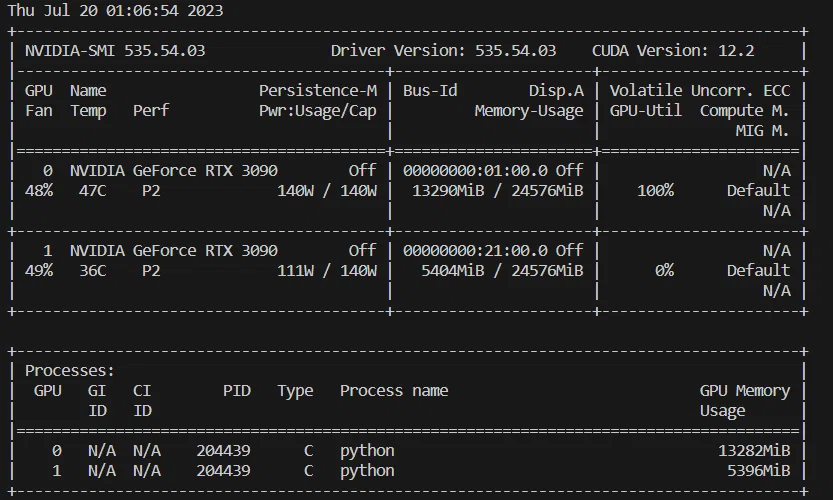
メモリ使用量は以下のとおりです。
sft_trainer.pyを少し修正します。
sft_trainer.pyをコピーして、sft_trainer_original.pyを作りました。88行目を変えて、jsonlファイルを読み込むようにします
#dataset = load_dataset(script_args.dataset_name, split="train")
dataset = load_dataset('json',data_files=script_args.dataset_name, split="train")作成したpyとjsonlを指定して、実行します。
python examples/scripts/sft_trainer_original.py \
--model_name meta-llama/Llama-2-7b-chat-hf \
--dataset_name dataset/test.jsonl\
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2 \
--output_dir peft_test
あまりにも学習データが少ないと、学習重みが保存されず、output_dir が空のままになる模様です。データが保存されなかったので、loraモデルの読み込みなども試していません。