
TwitterAPIでTwitterいいね数30以上をGoogleスプレッドシートに追加

こんにちは。
本日はTwitterAPIを使って特定アカウントのいいね数が30以上ならば、そのツイートをGoogleスプレッドシートに追加するプログラムをPythonで書いていこうと思います。
以前に、TwitterAPIを使ってGoogleスプレッドシートに記載した内容を1日2回ランダムにツイートしていくという記事を書きました。ほとんどが無料ですので興味ある方はお読みください。
※本記事はTwitterAPIの取得済み、かつGoogleスプレッドシートが操作できる状態であることが大前提です。
最後に全体のコードを載せているので手っ取り早く使いたい方は最後まで飛んでください(^^)/
特定のアカウントのツイートを拾う
今回はこちらの3名の方のツイートを拾うプログランムを作ります。
@ally_of_earth
@mimikousi
@t_kun_kamakiri
こちらの方のツイートを拾うため辞書型で用意しておきます。
user_list = {
'eco':'ally_of_earth',
'kamakiri':'t_kun_kamakiri',
'kousi':'mimikousi'
}必要なライブラリをインポート
import tweepy
# グーグルスプレッドシートを操作する為にimport
import time
import os
from dotenv import find_dotenv, load_dotenv
import jsonアクセスキーなど個人情報に関わるものは.envファイルに書いて同じフォルダ内に置いておきます。
#エンドポイント(TwitterAPI)
env_file = find_dotenv()
load_dotenv(env_file) # .envファイルを探して読み込む
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_KEY = os.environ.get('ACCESS_KEY')
ACCESS_KEY_SECRET = os.environ.get('ACCESS_KEY_SECRET')フォルダ内は今こんな感じ。

以下でツイート200件を取得できます。
api = tweepy.API(auth)
tweets = api.user_timeline(
id=user_list['kamakiri'],
count=200,
include_rts =False,
exclude_replies=True,
) # defaultで20個取得tweepyのドキュメントを見て好みに応じてオプションをつけてください。
ツイートが取得できているか確認してみます。
for i, tweet in enumerate(tweets):
print(i,'='*100)
print(tweet.text)
print(f'fav:{tweet.favorite_count}')
print(f'retweeted:{tweet.retweeted}')
print(f'id:{tweet.id}')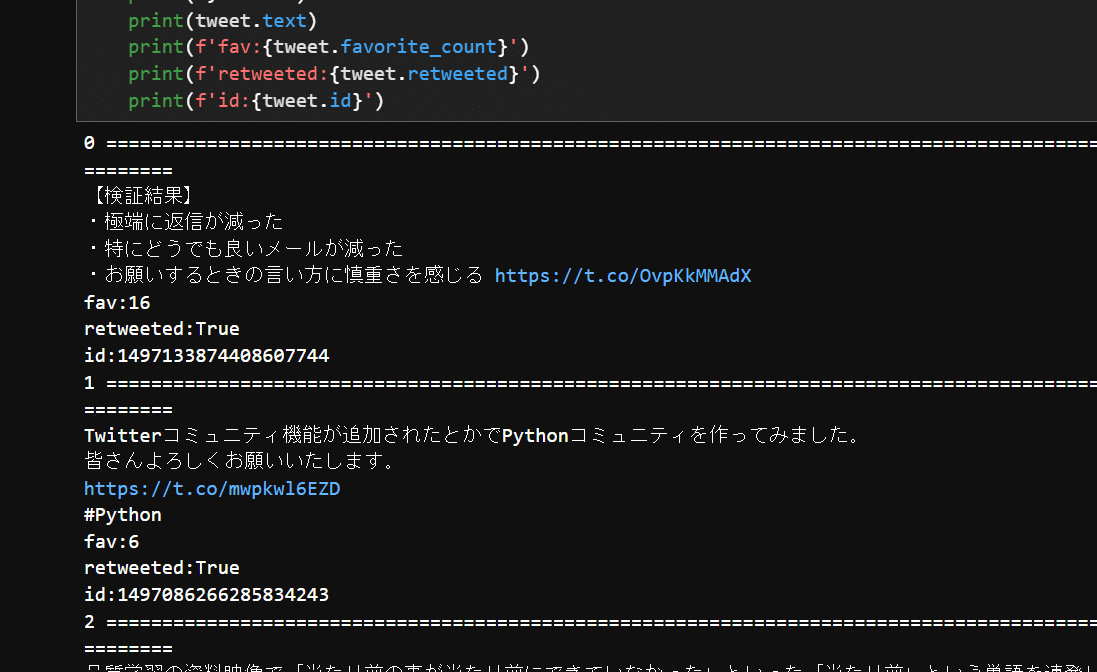
ここまでをまとめると・・・
import tweepy
# グーグルスプレッドシートを操作する為にimport
import time
import os
from dotenv import find_dotenv, load_dotenv
import json
env_file = find_dotenv()
load_dotenv(env_file) # .envファイルを探して読み込む
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_KEY = os.environ.get('ACCESS_KEY')
ACCESS_KEY_SECRET = os.environ.get('ACCESS_KEY_SECRET')
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_KEY_SECRET)
api = tweepy.API(auth)
user_list = {
'eco':'ally_of_earth',
'kamakiri':'t_kun_kamakiri',
'kousi':'mimikousi'
}
tweets = api.user_timeline(
id=user_list['kamakiri'],
count=200,
include_rts =False,
exclude_replies=True,
) # defaultで20個取得この書き方だと上限200件までしか取得できないので、もっと取得したい場合は以下の書き方をします。
ツイート2000件取得
ここからはツイート頻度も高く、いいね数も多いエコおじいさんのツイートを取り扱っていこうと思います。
ツイート2000件取得します。
# 必要なモジュールのimport
import datetime
import pandas as pd
import tweepy
env_file = find_dotenv()
load_dotenv(env_file) # .envファイルを探して読み込む
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_KEY = os.environ.get('ACCESS_KEY')
ACCESS_KEY_SECRET = os.environ.get('ACCESS_KEY_SECRET')
# 認証のためのAPIキーをセット
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_KEY_SECRET)
api = tweepy.API(auth)
user_list = {
'eco':'ally_of_earth',
'kamakiri':'t_kun_kamakiri',
'kousi':'mimikousi'
}
user_name = user_list['eco']
# 取得ツイートの数
num = 2000
rlcount = 1
tweet_data = []
# tweepy.CursorのAPIのキーワードサーチを使用(api.search)
tweets = tweepy.Cursor(api.user_timeline,
id=user_name,
exclude_replies = True,
include_rts =False,
tweet_mode='extended').items(num)
for tweet in tweets:
# いいねとリツイートの合計がrlcuont以上の条件
if tweet.favorite_count + tweet.retweet_count >= rlcount:
tweet_data.append([
tweet.user.name,
tweet.user.screen_name,
tweet.retweet_count,
tweet.favorite_count,
tweet.created_at.strftime('%Y-%m-%d'),
tweet.full_text.replace('\n', '')
])今、tweet_dataはリストでこのようになっています。

pandasデータフレームにする
さきほど取得したツイートのリスト型をpandasデータフレームに置き換えます。Pandasにした方がデータの取り扱いのためのメソッドが多いためです。
import pandas as pd
df = pd.DataFrame(tweet_data,
columns=['user_name', 'user_screen_name', 'rt', 'fav', 'date', 'text'])
df1日何ツイートしているかを確認
df.groupby('date').count()
1日平均ツイート数を調べます。
df.groupby('date').count()['user_name'].mean()df.groupby('date').count()['user_name'].max()
1日平均約4ツイート、最大で13ツイートしているときがありますね。
平均いいね数を調査
いいね数が100以上はなかなか起こらず、統計データを狂わしている可能性があるので100以上は除外することにします。
df[df['fav']<=100].describe()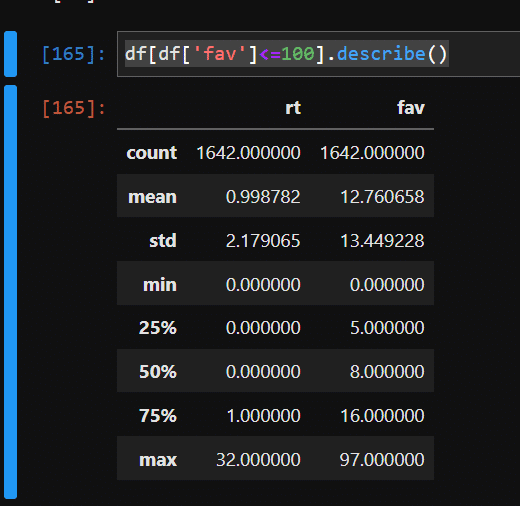
1ツイートは平均して約13いいね。標準偏差は約13。
なのでいいね数が正規分布に従うとして3σの13+3*13=39いいね数以上を@ally_of_earthさんにとってウケの良いツイートということにします。
しかし、いいね数が正規分布になっているという保証はどこにもありません。確認すると確かに正規分布とは言い難いです💦
@ally_of_earth さんのツイート2000件から
— カマキリ🐲Python頑張る昆虫 (@t_kun_kamakiri) February 21, 2022
✅1日平均3~4件ツイート(最大13)
✅平均いいね数14
✅正規分布ではないけど35いいね(≒+2σ)を外れ値とした
日付指定での取得ができないので毎日13件取得して、pandasの日付指定でツイートを絞り、スプレッドシートに転記する。 pic.twitter.com/1pUkCSRVXj
正規分布とかポアソン分布とは言えなさそう。
— カマキリ🐲Python頑張る昆虫 (@t_kun_kamakiri) February 21, 2022
何分布が良いのか・・・ pic.twitter.com/58YVy5qzOz
いいね数のヒストグラムが正規分とするのは無理がありますが、ひとまず雑に正規分としてざっくり考えます。
いいね数39だとちょっと確率的に送りにくいのでざっくり、いいね数30以上のツイートだけを拾って、それをGoogleスプレッドシートに追加していくようにします。
5日前のいいね数30以上のツイートのみを取得
今の日付から5日前の日付までのツイートのみ取得してツイートを絞り込みます。
まず5日前までの全てのツイートを取得します。
そのために確実にツイートで拾える数numを指定します。
1日最大で13ツイートだったので、13*5日 なので、ざっくりnum = 15*5となるように書きます。
rlcount = 1
user = 'eco'
favcount = 30
delta_t = 3
num = 15 * delta_tそして日付を指定する記述を書いておきます。
nowadays = datetime.now()
yesterday = (nowadays - timedelta(5)).strftime('%Y-%m-%d')まとめるとこちらです。
# 必要なモジュールのimport
from datetime import datetime, timedelta
import pandas as pd
import tweepy
import pandas as pd
env_file = find_dotenv()
load_dotenv(env_file) # .envファイルを探して読み込む
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_KEY = os.environ.get('ACCESS_KEY')
ACCESS_KEY_SECRET = os.environ.get('ACCESS_KEY_SECRET')
# 認証のためのAPIキーをセット
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_KEY_SECRET)
api = tweepy.API(auth)
user_list = {
'eco':'ally_of_earth',
'kamakiri':'t_kun_kamakiri',
'kousi':'mimikousi'
}
user_name = user_list['eco']
# 取得ツイートの数
rlcount = 1
user = 'eco'
favcount = 30
delta_t = 3
num = 15 * delta_t
tweet_data = []
# tweepy.CursorのAPIのキーワードサーチを使用(api.search)
tweets = tweepy.Cursor(api.user_timeline,
id=user_list[user],
exclude_replies = True,
include_rts =False,
tweet_mode='extended').items(num)
for tweet in tweets:
# いいねとリツイートの合計がrlcuont以上の条件
if tweet.favorite_count + tweet.retweet_count >= rlcount:
tweet_data.append([
tweet.user.name,
tweet.user.screen_name,
tweet.retweet_count,
tweet.favorite_count,
tweet.created_at.strftime('%Y-%m-%d'),
tweet.full_text.replace('\n', '')
])
df = pd.DataFrame(tweet_data,
columns=['user_name', 'user_screen_name', 'rt', 'fav', 'date', 'text'])
nowadays = datetime.now()
yesterday = (nowadays - timedelta(5)).strftime('%Y-%m-%d')
df[(df['date']==yesterday) & (df['fav']>=favcount)]5日前で30いいねとなっているツイートのみを取得できました。

1件だけ見つかりましたね。
スプレッドシートに追加
スプレッドシートへの追加の記述はこちらです。
import gspread
#ServiceAccountCredentials:Googleの各サービスへアクセスできるservice変数を生成します。
from google.oauth2.service_account import Credentials
#2つのAPIを記述しないとリフレッシュトークンを3600秒毎に発行し続けなければならない
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
#認証情報設定
#ダウンロードしたjsonファイル名をクレデンシャル変数に設定(秘密鍵、Pythonファイルから読み込みしやすい位置に置く
# 認証情報設定
credentials = ServiceAccountCredentials.from_json_keyfile_name("organic-duality-295411-65ee7e371b14.json")
# 共有設定したスプレッドシートのシート1を開く
SPREADSHEET_KEY = os.environ.get('SPREADSHEET_KEY')
#OAuth2の資格情報を使用してGoogle APIにログインします。
gc = gspread.authorize(credentials)
#共有設定したスプレッドシートのワークブックを開く
# スプレッドシートを開く
workbook = gc.open_by_key(SPREADSHEET_KEY)
worksheet_tweet = workbook.worksheet('ツイート用')
# for text in
cell_value = worksheet_tweet.col_values(5)[4:]
# ツイートの追加
for i, tweet_text in enumerate(df[(df['date']==yesterday) & (df['fav']>=favcount)]['text']):
worksheet_tweet.update_cell(len(cell_value)+5+i, 5, tweet_text)うまくツイートが追加されているかGoogleスプレッドシートを開いて確認してみてください。

上手く動作しているようです。
リツイートする
Googleスプレッドシートに転記するツイートを、ついでにリツイートするようにしましょう。
# リツイートする
if tweet.favorite_count >= favcount and tweet.created_at.strftime('%Y-%m-%d')==since:
api.retweet(tweet.id)関数にまとめる
今ままでのコードをまとめます。
関数にするためには機能ごとに分解した方が良さそうですね。
メインの関数
ツイートの取得
pandasで日付からツイート選別
スプレッドシートに転記
# 必要なモジュールのimport
from datetime import datetime, timedelta
import pandas as pd
import tweepy
import pandas as pd
import gspread
from dotenv import find_dotenv, load_dotenv
import os
from oauth2client.service_account import ServiceAccountCredentials
#ServiceAccountCredentials:Googleの各サービスへアクセスできるservice変数を生成します。
from google.oauth2.service_account import Credentials
#2つのAPIを記述しないとリフレッシュトークンを3600秒毎に発行し続けなければならない
def main():
env_file = find_dotenv()
load_dotenv(env_file) # .envファイルを探して読み込む
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_KEY = os.environ.get('ACCESS_KEY')
ACCESS_KEY_SECRET = os.environ.get('ACCESS_KEY_SECRET')
# 認証のためのAPIキーをセット
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_KEY_SECRET)
api = tweepy.API(auth)
# 共有設定したスプレッドシートのシート1を開く
SPREADSHEET_KEY = os.environ.get('SPREADSHEET_KEY')
user = 'kousi'
favcount = 30
delta_t = 3
num = 15 * delta_t
user_ini = {
'eco':'y',
'kamakiri':'k',
'kousi':'i'
}
#1日のツイートの取得(いいね数の選別)
nowadays = datetime.now()
since = (nowadays - timedelta(delta_t)).strftime('%Y-%m-%d')
# ツイートの取得
tweet_data = tweet_get(api, user, num, since, favcount)
df = df_tweet_today(tweet_data, since, favcount)
print(since, df)
# スプレッドシートへの転記
spredsheet_update(SPREADSHEET_KEY, df, since, favcount, user, user_ini)
def tweet_get(api, user, num, since, favcount):
user_list = {
'eco':'ally_of_earth',
'kamakiri':'t_kun_kamakiri',
'kousi':'mimikousi'
}
if user not in user_list:
print('変数userをeco,kamakiri,kousiにしてください。')
user_name = user_list[user]
# 取得ツイートの数
rlcount = 1
tweet_data = []
# tweepy.CursorのAPIのキーワードサーチを使用(api.search)
tweets = tweepy.Cursor(api.user_timeline,
id=user_name,
exclude_replies = True,
include_rts =False,
tweet_mode='extended').items(num)
for tweet in tweets:
# いいねとリツイートの合計がrlcuont以上の条件
if tweet.favorite_count + tweet.retweet_count >= rlcount:
tweet_data.append([
tweet.user.name,
tweet.user.screen_name,
tweet.retweet_count,
tweet.favorite_count,
tweet.created_at.strftime('%Y-%m-%d'),
tweet.full_text.replace('\n', '')
])
# リツイートする
if tweet.favorite_count >= favcount and tweet.created_at.strftime('%Y-%m-%d')==since:
api.retweet(tweet.id)
return tweet_data
def df_tweet_today(tweet_data, since, favcount):
df = pd.DataFrame(tweet_data,
columns=['user_name', 'user_screen_name', 'rt', 'fav', 'date', 'text'])
print(df[(df['date']==since) & (df['fav']>=favcount)])
return df[(df['date']==since) & (df['fav']>=favcount)]
def spredsheet_update(SPREADSHEET_KEY, df, since, favcount, user, user_ini):
# スプレッドシート
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
#認証情報設定
#ダウンロードしたjsonファイル名をクレデンシャル変数に設定(秘密鍵、Pythonファイルから読み込みしやすい位置に置く
credentials = ServiceAccountCredentials.from_json_keyfile_name(
"organic-duality-295411-65ee7e371b14.json"
)
#OAuth2の資格情報を使用してGoogle APIにログインします。
gc = gspread.authorize(credentials)
#共有設定したスプレッドシートのワークブックを開く
# スプレッドシートを開く
workbook = gc.open_by_key(SPREADSHEET_KEY)
worksheet_tweet = workbook.worksheet('ツイート用')
# for text in
cell_value = worksheet_tweet.col_values(5)[4:]
print(len(cell_value))
# ツイートの追加
for i, tweet_text in enumerate(df[(df['date']==since) & (df['fav']>=favcount)]['text']):
worksheet_tweet.update_cell(len(cell_value)+5+i, 2, user_ini[user])
worksheet_tweet.update_cell(len(cell_value)+5+i, 5, tweet_text)
if __name__ == "__main__":
main()これで思った通りの動作ができていればOKです。
Herokuで定期実行
できたプログラムを定期実行させたい場合はherokuを使うのが簡単ですね。
以下の記事を見ながら無料ですぐに利用できます。
定期実行の頻度は1日1回にしているので、次の日に正常に動作しているかを確認することになります。
※正常に動作していました。
では、本日は以上です(^^♪
Twitter➡@t_kun_kamakiri
Instagram➡kamakiri1225
youtube➡https://www.youtube.com/channel/UCbG6_Q9ZRqqVT6YZOpcjDlQ
ブログ➡宇宙に入ったカマキリ(物理ブログ)
ココナラ➡物理の質問サポートサービス
コミュニティ➡製造業ブロガー