
GRPO とは? : DeepSeek-R1で採用された16GBで10億パラメータモデルをファインチューニングする技術

こんにちは、スクーティーという会社の代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
深層強化学習、特に自然言語処理の分野は、目覚ましい進化を遂げています。しかし、大規模言語モデルの学習には、膨大な計算資源が必要となることが課題でした。
GRPO (Group Relative Policy Optimization) は、この問題を解決する可能性を秘めた画期的な技術です。GRPOは、従来の強化学習手法であるPPO (Proximal Policy Optimization) を改良したもので、より少ない計算資源で効率的に大規模言語モデルを学習できます。
この記事では、GRPOの概要、PPOとの違い、具体的な仕組み、そしてDeepSeek-R1での活用事例まで、高校生にもわかるように、どこよりも詳しく解説します。
GRPO : 概要と従来手法との違い
GRPOとは?:大規模言語モデルの学習を効率化する技術
GRPO (Group Relative Policy Optimization) は、深層強化学習のアルゴリズムの一種で、特に大規模言語モデル (LLM) の学習を効率化するために開発されました。従来の強化学習手法であるPPO (Proximal Policy Optimization) を改良したもので、より少ない計算資源で同等以上の性能を達成できます。
DeepSeek-Mathの研究の中で、GRPO (Group Relative Policy Optimization) という強化学習アルゴリズムが提案・導入され、DeepSeek-R1モデル構築に利用されています。 具体的に何がすごいのかと言うと、16GBのVRAMしか持たない普通のノートPCでも、10億パラメータのLLaMA 3.2モデルをリーズニングモデルにファインチューニングできた事例があるほどです。従来のPPOでは難しかった、より小さなGPUでも大規模言語モデルの学習ができるため、研究者や開発者の裾野を広げる可能性を秘めています。
従来の強化学習手法PPOとその問題点
GRPOを理解するためには、まず、従来の強化学習手法であるPPO (Proximal Policy Optimization) について知る必要があります。PPOは、OpenAIによって開発されたアルゴリズムで、ChatGPTの基盤技術としても知られています。 PPOでは、「方策モデル」「価値モデル」「報酬モデル」「リファレンスモデル」の【4つのモデル】を使用します。
方策モデル:現在の状態に基づいて、次にとるべき行動(トークン)を決定するモデルです。
価値モデル:方策モデルの将来的な総報酬を予測するモデルです。PPOの課題はこの価値モデルにもLLMと同じサイズのモデルを使用する必要があり計算コストを増大させる点でした。
報酬モデル:生成された応答の質を評価し、報酬を与えるモデルです。
リファレンスモデル:方策モデルの学習が過度に進み、元の言語モデルから大きく逸脱しないように制御する役割を持ちます。
これらの4つのモデルを複雑に連携させる必要があったことと、価値モデルの学習には、方策モデルと同等の計算資源が必要となる点が問題でした。
GRPOがもたらすブレイクスルー
GRPOではPPOにおける方策モデルと報酬モデル、リファレンスモデルに加えて存在した、価値モデルを取り除くことで、計算資源の節約、学習の効率化を実現しました。価値モデルは、方策モデルの将来的な総報酬を予測し、方策モデルの学習を安定化させる役割を持ちます。しかし、深層強化学習において最先端の結果を出すためには、価値モデルの計算には方策モデルと同程度の計算リソースを必要とし、学習全体の効率を下げてしまう要因となっていました。
GRPOでは、価値モデルの代わりに、複数の出力の報酬の平均を利用するというシンプルなアプローチを採用しました。具体的には、同一の質問に対し複数の出力(回答)を生成させ、それらの報酬を比較することで、方策モデルの学習を効率化します。 この複数の出力の報酬を比較するという手法により、価値モデルの計算が不要となり、計算コストの大幅な削減が実現されました。 DeepSeek-R1では10億パラメータモデルのファインチューニングが16GBのVRAMで実現されています。従来のPPOと比べても、価値モデルをなくしたことで学習に必要なメモリ量が削減され、より少ない計算資源での学習を可能にしています。また、複数の出力を比較することで、価値関数の推定における分散を低減させることができ、学習の安定化にも寄与すると考えられます。
さらに具体的に言えば、価値モデルを排除したことで、学習に必要なGPUメモリが大幅に削減されます。例えば、論文によれば、10億パラメータのモデルをファインチューニングする場合、PPOでは少なくとも24GB以上のVRAMが必要となるケースでも、GRPOでは16GBのVRAMで実現可能になったと報告されています。 また学習時間も、価値モデルの学習と、そのための計算が不要になることで、例えば数日かかっていた学習が数時間に短縮されるといった効果も期待できます。
これにより、DeepSeek-R1では、ルールベースの報酬関数と、DeepSeek V3ベースモデルを利用することで、ニューラルネットワークモデルによる報酬計算を不要にし、更なる計算資源の効率化を図っています。
GRPOの仕組み
ここからは、DeepSeekが公開している以下の論文の要約になります。
関連論文:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
方策勾配法による方策最適化
GRPOでは、方策勾配法を用いて方策を最適化します。 方策とは、ある状態において、どのような行動をとるべきかの指針を示すもので、方策関数は通常以下のように定義されます。
Jnaive(θ) = E(q, o) ~ (data, πθ)[r(o)]
これは方策関数によってq, oが生成された時の、r(o) の期待値を、最大化するθを見つけることを意味しています。
この方策関数によって、エージェントが方策にしたがって行動し、得られた報酬の期待値を最大化するように学習する方策勾配法が成立します。
勾配法では、目的関数の勾配(偏微分)を計算し、その勾配を利用して方策のパラメータを更新します。この式に基づいてパラメータθを最適化するにあたっては、目的関数の値を最大化するように以下の方策勾配定理が成立します。
Jadv(θ) = E[A(o)], where A(o) = r(o) - Vψ(o).
この式のθを、以下の方策勾配定理を用いて更新します。 ここで Vψ(o)とは価値関数と呼ばれるもので、Advantage関数を計算するために使用されます。
価値関数の計算
価値関数は、ある状態において、将来的に得られるであろう総報酬の期待値を示すものです。方策勾配法では、この価値関数を直接計算する代わりに、状態価値関数 V(s) を推定することで、方策の改善を行います。状態価値関数は、以下のように定義されます。
At = rt - Vψ(st).
しかし、価値関数 Vψ(s)を計算するためには、方策モデルと同等の計算リソースが必要な別のモデルが必要になります。
グループ相対優位性 (Group Relative Advantage)
DeepSeeK R1で採用されているGRPO (Group Relative Policy Optimization) では、価値関数Vψ(s)を使用しません。そのかわりにグループ相対優位性 (Group Relative Advantage)という考え方を導入しています。これは、同じ質問に対し複数の出力(回答)を生成させ、それらの報酬を比較することで、方策モデルの学習を効率化するものです。
DeepSeekMathの論文によると、GRPOの目的は、下記数式で表されます。
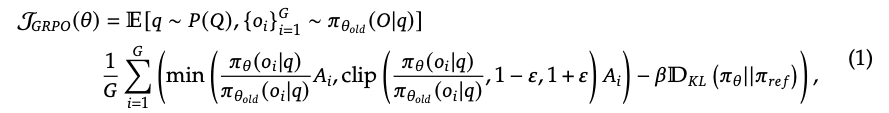
上記の式(1)はGRPOの目的関数を表しています。この式は、複数の要素から構成されており、それぞれがGRPOのアルゴリズムにおいて重要な役割を果たします。以下に、それぞれの要素について詳しく説明します。
E[q∼P(q),{oi}G i=1∼πold(O|q)]: これは、期待値計算を表しています。具体的には、質問qが質問の分布P(q)からサンプリングされ、それに対して古い方策πoldを用いてG個の出力{oi}が生成されることを意味します。
1/G ΣG i=1: これは、G個の出力に対する平均操作を表しています。
min(..., clip(...)): これは、方策の更新幅を制限するための工夫です。min関数の中には、2つの項があります。
(πθ(oi|q) / πold(oi|q)) * Ai: これは、新しい方策πθと古い方策πoldの確率比に、Advantage関数 Ai を掛けたものです。確率比は、新しい方策が古い方策と比べて、どれだけその出力を生成しやすいかを示します。
clip((πθ(oi|q) / πold(oi|q)), 1 - ε, 1 + ε) * Ai: これは、上記の確率比を一定の範囲(1-ε から 1+ε)に制限(クリップ)したものです。これにより、方策の更新が大きくなりすぎることを防ぎます。
-βDKL(πθ || πref): これは、新しい方策πθと参照方策πrefの間のKLダイバージェンスに、係数βを掛けたものです。KLダイバージェンスは、2つの確率分布の間の距離を測る指標であり、ここでは新しい方策が参照方策から離れすぎることを防ぐ役割を果たします。
ここで、
Ai = (ri - mean({r1, r2, ..., rG})) / std({r1, r2, ..., rG})
と置くと、この数式は、複数の出力の報酬の平均を計算し、Advantageとすることで価値関数の代わりとするということを意味しています。これにより、価値関数モデル自体が不要になりました。
この数式の最後の項にある
-βDKL(πθ || πref)
は、方策が最初のモデルから逸脱しすぎることを防ぐためにあります。これは、正則化項に相当するもので、方策の多様性を維持するための仕組みです。方策の急激な変化は、学習の不安定化を招く可能性もあるので、この正則化項は方策の変化に対してある種のブレーキの役割を果たしています。
DeepSeek-R1 では、具体的な方策最適化のために以下の工夫を取り入れています。
Clip: 現ステップの方策更新において、あまりに大きく学習が1ステップで進むことを防止するため、方策の確率比をクリップ
Min: 方策更新の安定化のため、クリップした値と元の値の最小値を選択
ここで、ClipとMinの役割について、具体的な例を用いて説明します。例えば、ある質問に対するモデルの出力について、新しい方策での出力確率が古い方策での出力確率よりも大幅に高い場合(例えば、10倍など)、その出力は非常に有望であると考えられます。しかし、一度の更新でこの出力確率を過度に増加させてしまうと、学習が不安定になる可能性があります。
Clipは、このような極端な確率比の変化を制限する役割を果たします。具体的には、確率比が一定の範囲(例えば、0.8から1.2の間)に収まるように、値がクリップされます。
Minは、Clipされた値と元の値(クリップされていない確率比とAdvantageの積)を比較し、小さいほうの値を選択します。これにより、方策の更新が過度に楽観的になることを防ぎ、より安定した学習を促進します。 これらの工夫は、方策勾配法の安定性を高めるための重要な要素です。特に、オフポリシー学習においては、古い方策と現在の方策のずれが大きくなりやすいため、ClipとMinによる制約が効果を発揮します。 さらに、論文によると、GRPOの目的関数におけるminとclipは、方策の更新幅を制限し、学習の安定化に寄与すると同時に下記のような効果があることが示唆されています。 方策の更新によって方策の確率比 πθ(o_i|q) / πold(o_i|q) が1から大きく乖離することを防ぐ。
以上のような工夫の結果、学習の安定化と効率化を実現しています。
ここで各変数の意味を確認しておきましょう。
Pai θi: 試行中のモデルにおいて、入力xが与えられた時の出力iの生成確率
Pai θ old(o_i): 試行に利用した、一つ前のイテレーションのモデルにおいて、入力xが与えられた時の出力iの生成確率
R: モデルの出力全てに対する評価
Avg: 全てのモデル出力に対する評価の平均値
Std: 全てのモデル出力に対する評価の標準偏差
Beta, epsilon: 定数
です。
オフポリシー学習
方策勾配法では、方策の更新ごとに新たなサンプルを収集する必要があります。これは、計算コストの増大を招く要因となります。そこで、オフポリシー学習と呼ばれる手法が用いられます。オフポリシー学習では、過去に生成されたサンプルを再利用することで、サンプル効率の向上を図ります。
具体的には、方策の更新前のモデル(古い方策)で生成されたサンプルを用いて、現在の方策を学習します。これにより、サンプル生成の頻度を減らし、計算コストを削減できます。上記のGRPOの目的関数では、πθ(oi|q) / πold(oi|q)がオフポリシー学習に対応する箇所であり、これにより、deep-seek R1の学習効率をあげています。 オフポリシー学習の導入は、DeepSeek-R1が高い推論能力を獲得できた理由の一つです。
オフポリシー学習には、サンプル効率の向上というメリットがありますが、同時に、学習の不安定化を招く可能性もあります。なぜなら、古い方策で生成されたサンプルは、現在の方策とは異なる分布を持つため、学習が適切に進まないことがあるからです。 例えば、古い方策では「質問に対して正直に答える」方策で、現在の学習では、「より面白い回答を返す」ことを学習したいとします。この場合、「正直に答える」という古い方策によって作られたデータを使い続けると、「面白い回答を返す」方策をうまく学習できない場合があります。
この、古い方策と新しい方策との間のずれから生じる誤差を補正するために、GRPO含めオフポリシー学習では重点サンプリングなどの技術が使われます。論文では下記のように記載されています。 具体的には、GRPOの目的関数における、
πθ(oi|q) / πold(oi|q) という項が、重点サンプリングにおける「重点サンプリング比率」に相当します。この比率は、新しい方策と古い方策の確率の比であり、古い方策でのサンプルが、新しい方策でどれだけ生成されやすいかを示しています。この比率を用いて、古い方策でのサンプルの寄与を補正することで、学習の安定化を図っています。
GRPOでは、この問題を解決するために、ClipやMinといった工夫を取り入れ、学習の安定化を図っています。
報酬モデル (Reward Model)
方策を最適化するためには、生成された応答(出力)の質を評価し、それに応じた報酬を与える必要があります。通常は、この役割を担うのが報酬モデルです。しかし、deep-seek R1の場合は、特別なルールベースの報酬を用いています。 このルールベースの報酬システムは、以下のような特徴を持ちます:
明確な基準: 数学の問題であれば、最終的な答えが正しいかどうか、プログラミングの問題であれば、コードがコンパイルエラーなく実行でき、期待される出力を返すかどうかなど、明確な基準に基づいて報酬が与えられます。
自動評価: 人間の判断を介さずに、プログラムによって自動的に報酬を計算できます。これにより、大規模なデータセットに対しても効率的に報酬を与えることができます。
客観性: 評価者の主観に左右されず、常に一定の基準で報酬が与えられます。
このルールベースの報酬により、DeepSeek-R1は下記を実現しています。
数式やプログラミングなどの特定の問題に対して、明確な正誤判定を導入。
モデルの出力形式を一定の枠組みに沿った形に制限
報酬自体は、出力全体に対して与え、方策勾配法、オフポリシー学習を通じて、各トークンに分配
例えば、数学の問題であれば、最終的な答えが正しければ高い報酬を与え、間違っていれば低い報酬を与えます。また、DeepSeek-R1では、「思考の過程」を特定のタグ(と)で囲むことをルールとして設けています。
DeepSeek-R1においては、論文によると、ニューラルネットワークを用いた報酬モデルは、報酬ハッキングを引き起こす可能性があり、また、報酬モデルの再学習には追加の計算資源が必要となり、学習パイプライン全体が複雑化するといった問題点がありました。そのため、Deep-seekR1は方策最適化においてルールベースの報酬システムと、教師なし学習を適用し、方策勾配法、オフポリシー学習を通じて、各トークンへの報酬の分配を行うことで効率的な学習を達成しました。
Deep-seekR1においては、上記の施策が組み合わさり、従来に比べて計算効率が良い、より高度な推論能力を獲得した大規模言語モデルが実現されているのです。
DeepSeek-R1での活用事例と今後の展望
DeepSeek-R1に関しては、こちらの記事に詳しく書いていますので、ぜひご覧ください!
関連記事:DeepSeek-R1 : 最大6710億パラメータで推論能力を飛躍的に向上させたAI
DeepSeek-R1におけるGRPOの効果
GRPOは、DeepSeek-R1の学習において中心的な役割を果たしました。DeepSeek-R1は、GRPOを用いることで、従来のPPOを用いたモデルと同等以上の推論能力を獲得し、以下のベンチマークで高い性能を示しています。
表1: モデルの基本情報

表2: 英語ベンチマーク

表3: コーディングベンチマーク

表4: 数学ベンチマーク

表5: 中国語ベンチマーク
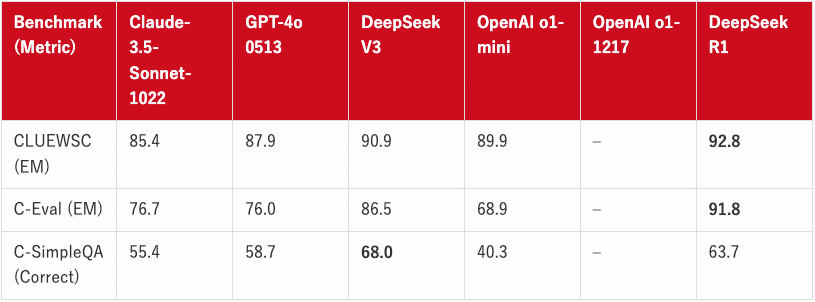
教育向けの知識ベンチマーク(MMLU、MMLU-Pro、GPQA Diamondなど)では、DeepSeek-R1はDeepSeek-V3よりも優れた性能を示しています。これは、STEM関連の質問に対する精度が向上したためであり、大規模な強化学習によって実現されました。また、DeepSeek-R1は、長文の文脈依存QAタスクであるFRAMESでも優れた結果を示しており、文書分析能力の高さを示しています。これは、AIを活用した検索やデータ分析タスクにおける推論モデルの可能性を示唆しています。事実に基づいた質問応答ベンチマークであるSimpleQAでは、DeepSeek-R1はDeepSeek-V3を上回り、事実に基づくクエリ処理能力を示しています。同様の傾向は、OpenAI-o1がこのベンチマークでGPT-4oを上回ることからも見て取れます。
数学的なタスクにおいては、Deep-seekR1はその他のモデルを大幅にうわまる性能を発揮しました。
AIME 2024 (Pass@1): 79.8% (OpenAI-o1-1217をわずかに上回る)
MATH-500 (Pass@1): 97.3% (OpenAI-o1-1217と同等)
特に、DeepSeek-R1 は数学の問題に対し、その優れた推論能力を発揮しました。

この図は、DeepSeek-R1-Zeroの学習過程におけるAIME 2024ベンチマークでの精度(accuracy)の変化を示しています。横軸は学習ステップ、縦軸は精度を表しており、学習が進むにつれて精度が向上していることがわかります。

この図は、DeepSeek-R1-Zeroの学習が進むにつれて、モデルが生成する応答の平均的な長さがどのように変化するかを示しています。横軸は学習ステップ、縦軸は応答の長さ(トークン数)を表しています。学習初期には短い応答しか生成できなかったモデルが、学習が進むにつれてより長い応答を生成できるようになり、複雑な問題に対しても詳細な思考過程(Chain of Thought)を展開できるようになったことを示唆しています。
DeepSeek-R1はさらに、学習を通じて、以下のような自己改善能力を獲得しました。
長文の思考連鎖の生成能力
方策方策自身による、当初方針の再評価能力
これらは明示的にプログラムされたものではなく、強化学習の環境との相互作用を通じて、モデルが自律的に獲得した能力です。
DeepSeek-R1 は、人間による指示を解釈し、複雑なタスクを段階的に分解する能力を持つことが、学習によって示されました。
具体的には学習がある程度すすんだ段階のモデルにおいて、「ちょっと待って。これは「アハ!」モーメントだ。ステップごとに再評価して、正しい合計が…」と出力し、考え直すような様子が確認されています。
論文(arxiv:2501.12948v1)9ページ、Table 3より引用: この表は、DeepSeek-R1-Zeroの中間バージョンで見られた興味深い「アハ!」モーメントを示しています。モデルが、ある数学の問題を解いている途中で、自分のアプローチを再評価し、より良い解法を模索している様子が示されています。これは、モデルが単に答えを出すだけでなく、自分の思考プロセスを自己監視し、改善する能力を獲得しつつあることを示唆しています。

今後の展望:より人間らしい言語モデルへ
DeepSeek-R1は、GRPOを活用することで、効率的な学習と高い推論能力を獲得しましたが、いくつかの課題も残されています。例えば、
関数呼び出し、
マルチターン、
複雑な役割設定、
JSON出力
などのタスクでは、DeepSeek-V3に及ばない点があります。 関数呼び出しにおいては、外部APIとの連携が求められますが、DeepSeek-R1は現在のところ、自己完結的な応答生成に特化しています。 マルチターンの対話では、過去の文脈を正確に記憶し、一貫性を保った応答を生成する必要があります。しかしDeepSeek-R1は文脈記憶に課題があり、対話履歴が長くなると応答の質が低下する可能性が指摘できます。 さらに複雑な役割設定においては、ユーザーが指定した特定の役割(例:専門家、有名人など)になりきって応答を生成することが求められますが、役割の一貫性維持、口調、専門知識の活用に課題があります。 また、JSON出力においては構造化されたデータを正確に生成する能力は、API連携やデータ処理において重要ですが、DeepSeek-R1は自由形式のテキスト生成に強みを持つため、JSON形式での厳密な出力には改善が必要です。
DeepSeek-R1の課題として、将来のバージョンではこれらの点に取り組み、より人間らしく、多様なタスクに対応できる言語モデルの実現を目指していく必要があります。 具体的には、
教師データとして人間が作成・選別したChain of Thoughtを使用する
より多くのソフトウェアエンジニアリングタスクでの学習を実施
ファインチューニングと強化学習の反復を複数回繰り返すことで、知識の定着と応用範囲をひろげる
といった方法が考えられます。 また、論文中では成功しなかったと触れられているProcess Reward Model (PRM)とMonte Carlo Tree Search (MCTS)についてもそれぞれ示唆が得られる記載があります。 PRMに関しては
一般的な推論において、細かいステップを明示的に定義することは困難
現在の中間ステップが正しいかどうかを判断することは難しい
モデルベースのPRMを導入すると、報酬ハッキングにつながる可能性がある
といった課題が挙げられています。
またMCTSに関しては、
チェスとは異なり、トークン生成では探索空間が明確に定義されていないという問題がある
大規模なトレーニングにスケールアップする際にいくつかの課題に直面する
と述べられています。DeepSeek-R1の研究は、強化学習に基づく大規模言語モデルの可能性を大きく広げるものであり、今後の発展に注目です。
Distillation v.s. Reinforcement Learning
論文では、より小さなモデルにDeepSeek-R1のreasoning能力を受け継がせるDistillation(蒸留)についても検証しています。その結果、よりサイズの大きなモデルから蒸留したほうが、より性能がよくなることを発見しました。

この表は、DeepSeek-R1の蒸留モデルと、その他のモデルの推論関連ベンチマークにおける性能を比較したものです。注目すべき点は、DeepSeek-R1を蒸留したモデル(DeepSeek-R1-Distill-Qwen-32B)が、直接強化学習で学習したモデル(DeepSeek-R1-Zero-Qwen-32B)よりも大幅に高い性能を示していることです。これは、より強力なモデルから知識を蒸留することの有効性を示唆しています。
この表からも、より大きなモデルであるDeepSeek-R1から上流した、DeepSeek-R1-Distill-Qwen-32Bのほうが、DeepSeek-R1-Zero-Qwen-32Bよりもすぐれていることがわかります。 このことから、より大きなモデルで発見された推論パターンは、小さなモデルの推論能力向上に不可欠であることが示唆されています。
最後に
最後までお読みいただき、ありがとうございます!
ぜひ スキ と フォロー をお願いします!
弊社では、LLM(大規模言語モデル)やアーキテクチャの選定、技術検証、生成AIを使用したプロトタイピングやシステム開発、お客様社内での啓蒙活動等を対応させていただく「生成AIコンサルティング」サービスを提供しています。
また、業務利用できるChatGPTのような仕組みである「セキュアGAI」や、生成AIとOCRを組み合わせた「AI文書読み取りサービス」といったAIソリューションも提供しています。
ぜひお気軽にお問い合わせください!
この記事は私が経営する株式会社スクーティーのコーポレートブログの下記記事を焼き直したものです。