
生成AIの組織導入成功を阻む「4つの罠」とその対処法

生成AIは企業の生産性を高めていく上で避けては通れない存在である、という主張は至るところでなされています。
しかし、実際に生成AIの組織導入に成功して、多くの社員が日々の生産性を向上させた、という事例は一部のテック企業を除いてあまり聞こえてきません。
実際それはデータにも現れており、日本企業は米国、(欧州のサンプルとしての)ドイツ、中国などの企業と比べて、生成AIの利用意向が著しく低いことが総務省が発表した2024年版「情報通信白書」で明らかになっています。

比較対象となっている米国の状況をもう少し詳しく見てみましょう。Andreessen HorowitzがFortune500(米国における大手企業Top500)の企業群を対象に行った調査によると、大規模言語モデルや生成AIに対して米国企業はかなり積極的に取り組んでいることが分かります。
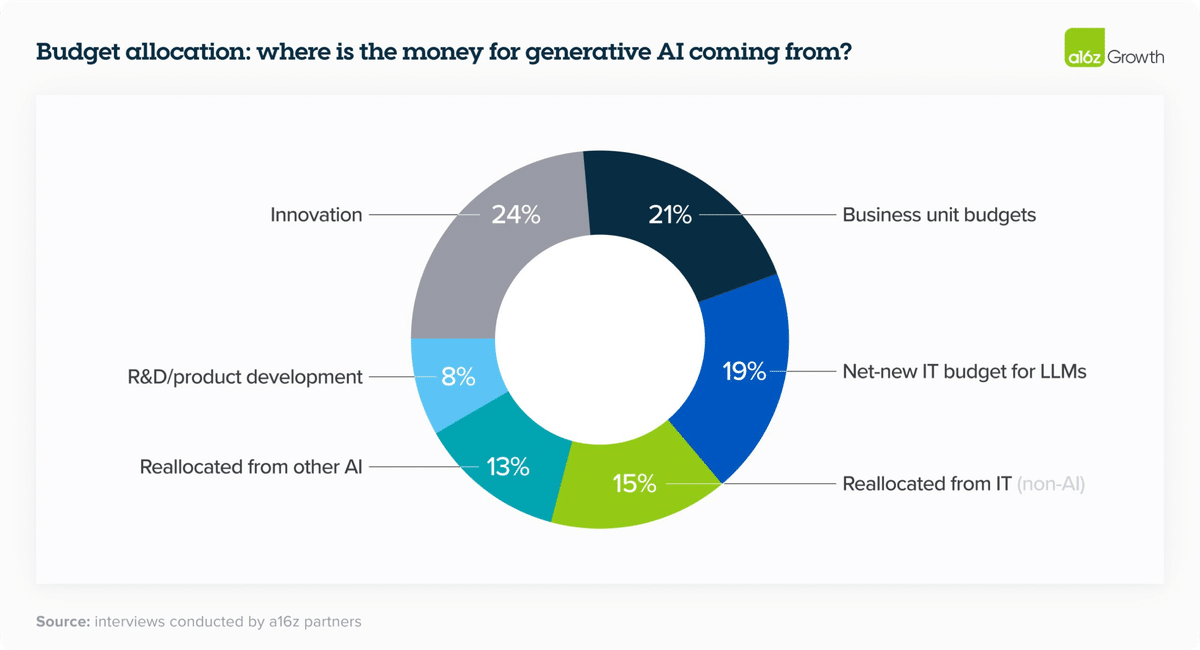
まず、生成AI活用の予算は2023年から2024年で2.5倍に上昇しています。

さらに、同調査によると、2023年は予算枠が「イノベーション」など1度切りの財布からの拠出でしたが、2024年にはカスタマーサポートなど持続的な予算枠から拠出しようという動きが目立ちます。
背景としては、調査対象企業内にCSコストを90%近く削減できた企業もいるなど、シンプルに圧倒的な導入効果です。
では、他国と比べてなぜ日本企業では生成AIの組織活用がうまく進まないのでしょうか?
私は生成AIの事業活用、組織活用をテーマの1つに複数の企業の顧問/アドバイザーとして活動しているのですが、顧問先での組織導入に成功した要因や、なかなか導入がうまくいかずに相談して下さる企業の状況を総合すると、生成AIの組織導入を阻む「4つの罠」があるのではないかと考えています。
本noteではそうした4つの罠がどのようなものか、それぞれの罠をどのように乗り越えていけばいいのかについて解説します。
自社の生産性を飛躍的に向上させたい経営者や事業リーダーの方、自社に生成AIを普及させたいがなかなか環境を変えることができずに苦労されている方に参考になる内容かと思いますのでぜひ最後まで読んで頂ければ幸いです。
生成AIの組織的導入成功を阻む「4つの罠」
「4つの罠」とそれぞれの解決策の全体像は以下になります。それぞれについて、詳しく見ていきましょう。

【罠1】 ダウンサイドリスクの過大視

まず最初の罠は「ダウンサイドリスクの過大視」です。
企業の決裁レイヤーが生成AIに関しての正しい知識を持たずに、生成AIのマイナス面を過大視してしまっているケースをよく目にします。
よく話にあがる懸念点は以下の3つです。
・データセキュリティの問題
・著作権侵害
・ハルシネーション(嘘の情報を生成してしまうこと)
こういったリスクを懸念して生成AIの活用を躊躇・断念するケースが多く見受けられますが、正しい知識さえあれば、これらのリスクは対処可能です。
このあたりは既知の方も多いと思うのでさっとだけ解説します。
1-1. データセキュリティのリスク
一般向けのChatGPTサービスを設定をいじらずに直接使った場合は送信した内容がOpenAIの学習に使われてしまうのですが、
・ChatGPTの企業向けプランを契約して利用する
・APIを活用した社内向けの簡易的なシステムを開発する
・複数の企業がリリースしている企業向けChatGPT利用サービスを使う
のいずれかの手段を使えば送信するデータが学習に回されることはなくなります。
1-2. 著作権侵害のリスク
著作権に関しても国が著作権データを学習したAIを使っても結果的に著作権侵害するような明らかに告示したものを作り出さなければ著作権侵害ではありませんよ、と明確に整理してくれています。
1-3. ハルシネーションのリスク
社内データを外部参照ファイルとして繋げて回答できるようにする
ChatGPTではなくGenSparkなどのリサーチAIを用いる
最終的には人間がファクトチェックをする
などの工夫や意識でこのリスクに関しては大幅に低減できます。
それでもなお間違えるリスクはあるだろ、という指摘はその通りなんですが、それを言ったらGoogle検索でも誤情報を掴むリスクはあるので本質的にはそれとあまり変わらないかなと。
以上のように一般に懸念されるリスクの大部分はかなりの程度回避することができます。
この罠を乗り越えるためには、シンプルに正しい知識を得ることが重要です。
その上で、ダウンサイドリスクを追い過ぎると、機会損失リスクが高まるというトレードオフに経営層が自覚的になるべきでしょう。
現在の日本の状況は、先述の他国との比較からも分かる通り、機会損失リスクを育てていると言わざるを得ません。
2. 過度な期待と100点主義
2つ目が「過度な期待と100点主義」という罠です。
実は、大規模言語モデルは原理的に100%の精度でのアウトプットができません。
大規模言語モデルというは、基本的には次に来る単語を確率的に予測して出す、というモデルになっているのであくまで確率的な処理です。
確率的に一番それらしいものを出す、という仕組みである以上100%の精度は原理上出ません。

米国ではCSや社内Q&Aの領域でのAI活用が大いに進んでいる一方で国内ではそこまで進んでいないことの背景には、この特性を理解せずに100点の精度を求めてしまうがゆえに導入を見送る、という状況です。
米国では、カスタマーサポートや社内ナレッジ検索といった用途でかなりAI活用が進んでいますが、90点の精度をAIで出して、残りの10点は人間による運用でカバーすればトータルでプラスである、という判断がされて導入が進んでいるように見受けられます。
例えばCSにおいてAIが対応できない内容であれば人間のオペレーターにすぐスイッチすれば良いし、社内ナレッジ検索でたまに間違った情報や古い情報が出ることもあるが最終的に人間がファクトチェックすれば十分効率的である、というような判断ですね。

その意味では、日本企業の方がAIへの期待値は高いと言えます。問題は、「その期待値が高すぎる」ということ。
ここから先は
AIやXRなどの先端テック、プロダクト戦略などについてのトレンド解説や考察をTwitterで日々発信しています。 👉 https://twitter.com/kajikent