
生成AIは今までのAIと何が違うのか?なぜいま盛り上がっているのか?

世界中で大きな盛り上がりを見せる「生成AI」。
生成AIを活用したChatGPTが史上最速で月間ユーザー数1億人を突破し、TIME誌の表紙を飾ったことは、その勢いを象徴する出来事だろう。
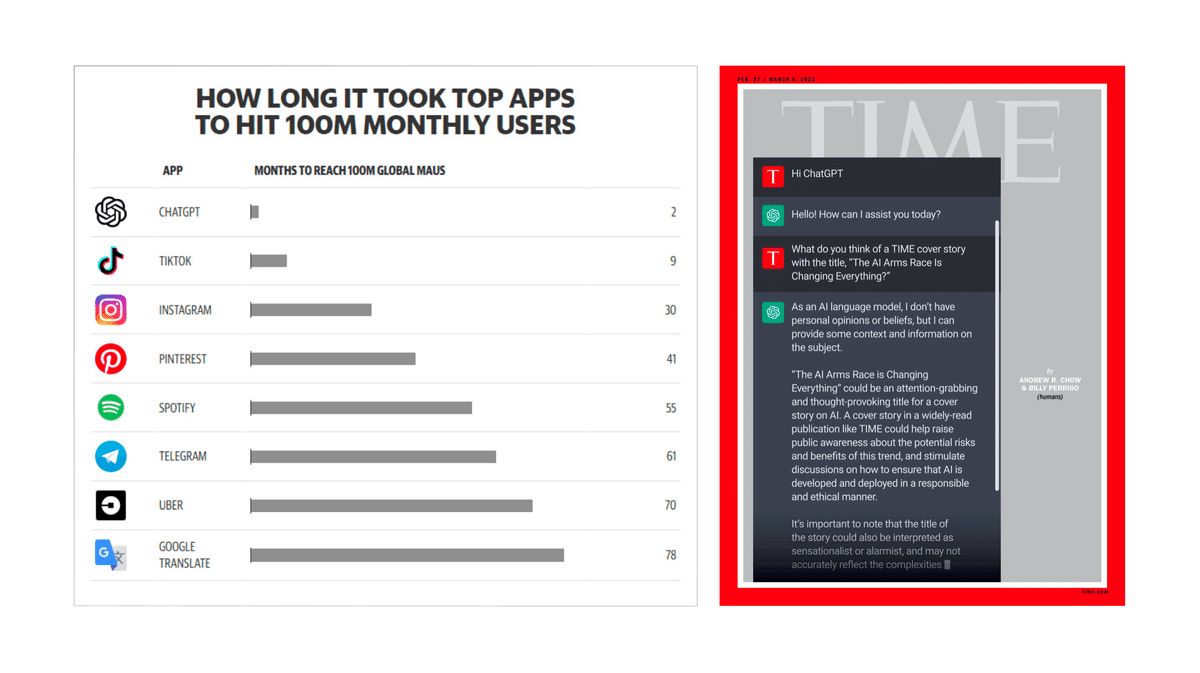
だが、ここで以下の2つの問いが浮かぶ。
生成AIは今までのAIと明確に何がちがうのか?
なぜ今このタイミングで生成AIがここまで盛り上がっているのだろうか?
この記事では上記2つの問いを海外のいくつかの記事を参考にしつつ解説していく。
生成AIと今までのAI技術との関係性
まず生成AI技術とこれまでのAI技術との関係性を概観しておこう。
広い意味でのAI技術として、データの特徴を学習してデータの予測や分類などの特定のタスクを行う機械学習が生まれ、その中でデータの特徴をマシン自体が特定するディープラーニング技術が発展した。
そして、生成AIはこのディープラーニング技術の発展の延長上にある技術だと言える。
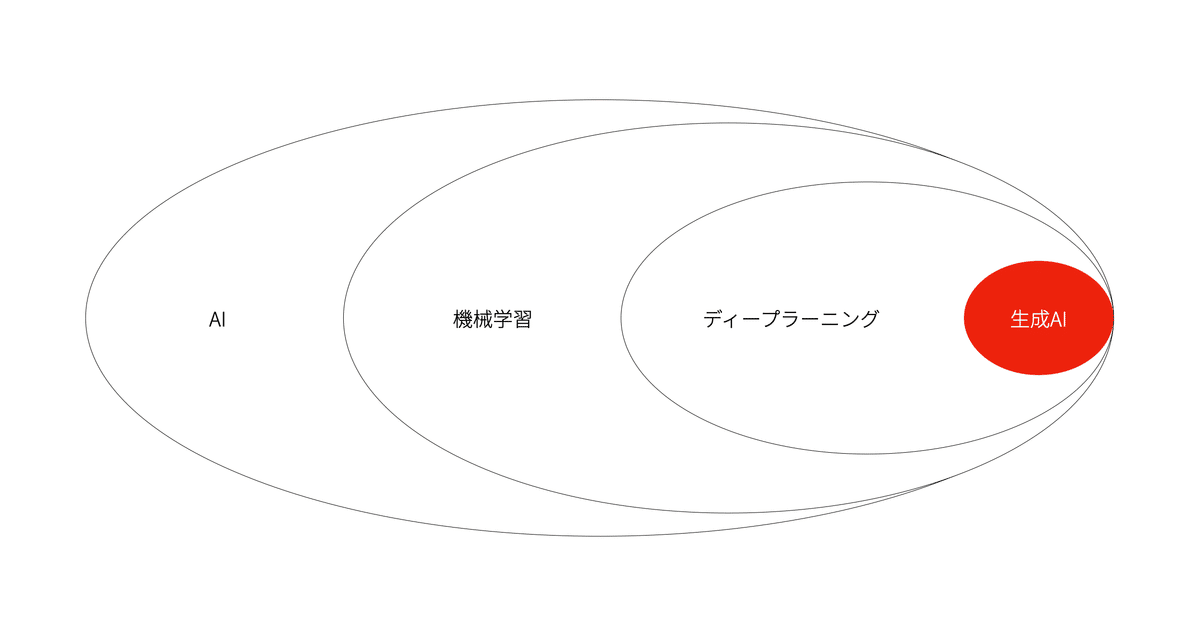
そして、「生成AI」という名称については対比的な意味で使われている側面もある。
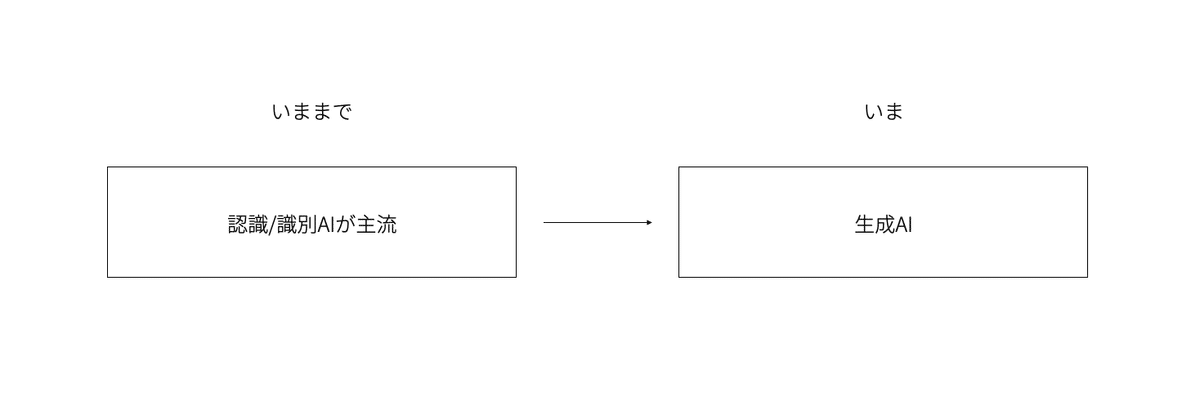
2022年に生成AIがブームになるまで、ディープラーニングにおいて人間と同等以上の成果を出せる領域としては認識や識別がメインだった。
その時代のAIと明確に区別するために、AI自体で何かを作り出すという性質から「生成AI」という呼び名が使われている。
Generative AIに至るブレークスルーの概観
詳細に入る前に生成AIに至るブレークスルーを概観すると以下のようになる。
これから順を追って解説していこう。

機械学習における「三位一体」
まず前提として機械学習における重要な要素は以下の3つだ。これは後述する大規模言語モデルにおいて重要な「べき乗則」の3要素とも対応している。
ここから先は
6,605字
/
15画像
この記事のみ
¥
1,500
期間限定!Amazon Payで支払うと抽選で
Amazonギフトカード5,000円分が当たる
Amazonギフトカード5,000円分が当たる
AIやXRなどの先端テック、プロダクト戦略などについてのトレンド解説や考察をTwitterで日々発信しています。 👉 https://twitter.com/kajikent