
検索エンジン初心者向けに基礎知識をまとめてみた

こんにちは!フジイカイタと申します!
2020年1月に転職をしまして、新しい会社では、自社プロダクトのプロダクトマネージャーとして、主に検索周りの機能開発・改善に関わっています。
転職直後は、検索エンジン?Solr?なにそれ?状態でしたが、半年間関わる中で少しずつ知っていることも増えてきたように思います。
せっかくなので、自分の学んだことの棚卸しを兼ねて、本noteを記すことにしました。
なお、私自身はエンジニアではなく、企画畑の人間です。アプリの仕様作りなどはしてきたものの、開発経験はありません。
よって、本noteも技術的に深いものではありません。
あくまでも、入社直後の私のように、検索エンジンについてなんとなく知りたい。これから勉強するにあたって取っ掛かりが欲しい。というような人向けの内容になります。
※ プロダクトで利用している検索エンジンがApache Solrのため、知識のベースはSolrに関するものとなっています。ただ、記載の内容は基礎的なものですので、Solrに限らない汎用的なものになっております。
※ なるべく正しい情報となるよう心がけていますが、私自身の理解が至らないことで、正確性に欠ける部分があるかもしれません。その場合、あたたかくご指摘いただけると嬉しいです。
いきなり書籍紹介
検索エンジンの仕組みを学ぶ上で、Apache Solr入門という本が理解しやすくておすすめです。
エンジニア向けに実際のコードも記載されてますが、私のような非エンジニアにとっても、仕組みが分かりやすいよう説明されてました。
これから検索エンジンについて学びたい方は、是非手にとってみてください。
ちなみにSolrとは
Wikipediaによる説明は以下です。
Solr(ソーラー)は、オープンソースの全文検索システム。
Apacheソフトウェア財団のLuceneプロジェクトのサブプロジェクトとして開発されている。
(引用元:Apache Solr - Wikipedia)
全文検索システム…なんのこっちゃ…ってなりますよね。わかります。
まずはそこからはじめてみましょう。
全文検索エンジンとは
検索エンジンは、ユーザーが指定したキーワードが含まれる文書/ドキュメントを探し出してあげるためにあります。
(例:ECサイトで、欲しい商品のページを見つけ出す)
検索をするときにドキュメントをどうやって探すかというと、大きく分けて、
・順次検索方式(全文探索方式)
・転置インデックス方式
の2種類が存在します。
順次検索方式とは
すべてのドキュメントにおいて、先頭から順に、指定のキーワードと一致する文字列が含まれているかどうかを探す方法のことです。
grepコマンドが代表例ですね。

この方式においては、検索のたびに全文書のチェックが必要なので時間がかかる点が難点となります。
そのため大量の検索が実施される検索エンジンにおいては向いてません。
そこで、転置インデックス方式です。
転置インデックス方式とは
転置インデックスとは、索引となるキーワード(インデックス)と、キーワードを含むドキュメントのIDをセットで管理してるデータ構造のこと。
その転置インデックスの中から、キーワードと一致する行を調べるだけで、該当キーワードが含まれるドキュメント群を容易に探すことができます。
例:「Tokyo」に該当するドキュメントは 01, 02, 05の3つ

なお、転置インデックスの「転置」とは、次のようなステップで作成されることに由来するようです。
1. 各ドキュメントのテキストを元に、インデックス(索引・見出し)を作成
2. ドキュメントベースのテーブルだったものを、インデックスベースに入れ替える(= 転置)

転置インデックス方式の場合、↑の通りでインデックスを事前に作っておく必要があります。
次は、そのために関連する技術について触れていきます。
検索エンジンに関連する技術
- トークナイズ
まずはトークナイズという仕組みについてです。
文章のインデックスを作ることは、すなわち、文書中に含まれている単語を理解することです。そのため、何が含まれているかを解析する必要があります。
そこで、「トークナイズ」という処理を通じて、文書を解析して、文章をトークン(最小単位)に分割していきます。
トークナイズを知る上で、
・N-gram
・形態素解析
の2種類について、ざっくり触れておきましょう。
トークナイズの種類
■ N-gram
文字数で区切る方法のことで、下記のようなイメージになります。
トークナイズ例
- 元文章:私は紅茶が好きです
- トークナイズ結果:私は|は紅|紅茶|茶が|が好|好き|きで|です
特徴としては、検索漏れが発生しないのですが、その分検索ノイズが多くなる(余計な文書までヒットする)という傾向があります。
なお、上記例のように2文字で区切ることをBi-gram (2-gram)、3文字で区切ることをTri-gram (3-gram)と呼びます。
■ 形態素解析
単語で区切る方法のことで、下記のようなイメージになります。
トークナイズ例
- 元文章:私は紅茶が好きです
- トークナイズ結果:私|は|紅茶|が|好き|です
N-gramのように、余計なトークンがない分ノイズは少なくてすみますが、単語の区切り方を間違ってしまうと、検索漏れに繋がるリスクがあります。
※ N-gram / 形態素解析 による違いイメージ

トークナイザ
なお、トークナイズするエンジンのことを、トークナイザと呼びます。
トークナイザには、いくつも種類があり、Kuromoji・Gosenといったものが有名でしょうか(私が触れたことがあるだけかもしれません)。
クエリとインデックスでのトークナイズ
トークナイズは、ドキュメントをインデックス化する際はもちろん、ユーザーが入力した検索キーワード(クエリ)に対しても実施されます。
トークナイズの際には、前後の文脈も踏まえて処理が実施されるため、クエリとインデックスで異なる結果になることがあります。

上記表の例のように、同じ「ニューヨーク」という単語であっても、クエリとインデックスで、トークナイズ結果が異なった場合、「ニューヨーク」で検索しても、「今年のニューヨークは寒い」というドキュメントはヒットしない結果となってしまいます。
検索に関わっていると、ユーザーから「検索にヒットしない」と問い合わせをいただく場合があるのですが、その場合、このケースに該当する場合がほとんどです。
- ノーマライズ
トークナイズの前後で、文字・単語を整える様々な処理のことを、ノーマライズといいます。
本noteでは、一例として、ストップワード除去と正規化を紹介しておきます。
ストップワード除去
「は」「です」のように、文書中によく出てくるものの検索キーワードとして意味のない単語のことを、ストップワードと言います。
ストップワードまでインデックスにしてしまうと、インデックスのサイズを無駄に大きくするだけなので、除去する必要があります。
その処理を、ストップワード除去と言います。
正規化
カタカナや英単語の全角/半角の統一や、特殊文字の置き換えなど、表記の統一を行う処理のことです。
例えば、このような処理が実施されています。
1. 全角/半角の統一:インターネット → インターネット
2. 特殊文字の置き換え:㍑ → リットル
3. 数字表記の統一:千本ノック → 1,000本ノック
1.2.のケースはトークナイズ前に文字単位で実施され、3のケースでは品詞情報をもとにするためトークナイズ後に実施されるなど、処理によってタイミングが異なります。
- シノニム
シノニムとは、synonym = 同義語・類義語のことを表します。
単語によっては、文字としては異なっているものの、明らかにこの単語を示していると判断できるものがあると思います。
例えば、「ビトン」という単語を聞いて、何を表していると思うでしょうか?
おそらく、モノグラムが有名な世界的ハイブランドの、あのルイ・ヴィトン(LOUIS VUITTON)のことだと、自然と推測するのではないでしょうか。
しかし、文字としては「ビトン」「ルイ・ヴィトン」「LOUIS VUITTON」はそれぞれ別物ですよね?
そのため、何も工夫をしないと、「ビトン」で検索したときにヒットするのは「ビトン」が含まれる文書のみとなり、「ルイ・ヴィトン」あるいは「LOUIS VUITTON」が含まれる文書はヒットしない状態となります。
これは、ユーザーにとっては望ましくない検索結果と言わざるをえません。
そこで、異なる単語であっても、同じものを示しているのだとシステムに教え込むのが、シノニムという仕組みです。
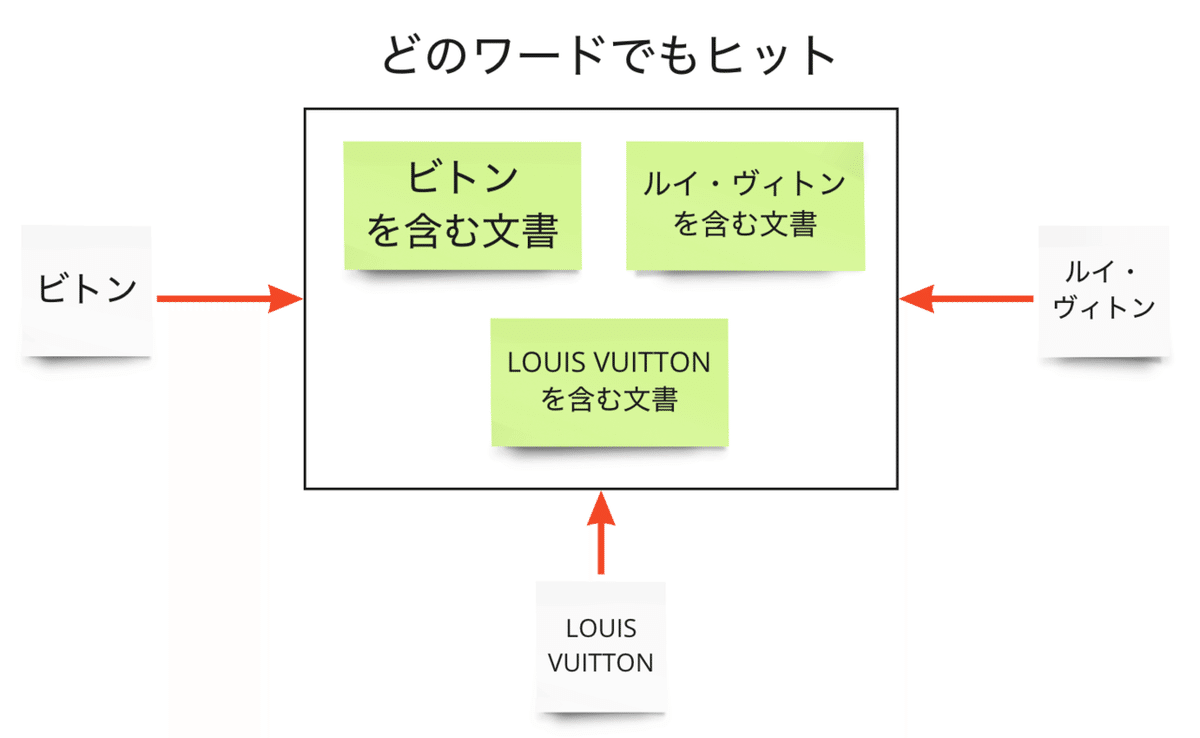
シノニム辞書に「ビトン」「ルイ・ヴィトン」「LOUIS VUITTON」は同じものだと登録することで、望ましい検索結果を作り出すことができます。
シノニム設定における注意点
シノニムは、ミスタイプを救ったりもできるのでとても便利な仕組みです。
しかし、使い方には少しコツが必要な部分もありますので、触れておきます。
■ 展開方向について
前述の例は「ビトン」「ルイ・ヴィトン」「LOUIS VUITTON」が互いに変換されることが望ましい例でしたが、場合によって双方向に変換されることが好ましくないケースも存在します。
例えば、「コスメ」「高級コスメ」が別トークンとして存在した場合、「ビトン」の例と同じように展開するべきでしょうか?

「コスメ」を探している人にとっては、「高級コスメ」が結果に含まれることは望ましいと言えそうです。
ですが、逆の場合はどうでしょうか?つまり、「高級コスメ」を探している人に、格安コスメを見せることは望ましいでしょうか?おそらく違うでしょう。
つまり、こういう関係性になります。
○ コスメ → コスメ or 高級コスメ
✗ 高級コスメ → 高級コスメ or コスメ
そのときには、シノニム辞書の登録方法により、

となるように、一方通行でのみ展開するように設定することができます。
このように、シノニムを登録する際には、実現したい検索結果を念頭に置いた上で、単語として何を登録するか、展開方向はどうするかを決める必要があります。
■ 登録ワードの選択
シノニムを入れたことにより、マイナス影響が発生する可能性もあることを念頭に入れておく必要があります。
例えば、「ワンピース」「ONE PIECE」と単語を、お互いにシノニムで展開できるようにした場合を考えてみましょう。
「ワンピース(漫画)」を探しているユーザーにとっては、「ONE PIECE(漫画)」がヒットすることはメリットと言えるでしょう。
一方で、「ワンピース(洋服)」を探している場合はどうでしょう?
洋服を探している人にとっては「ONE PIECE(漫画)」が出てくることは、ただのノイズになってしまいます。
このように、シノニム登録をするときには、望ましくない影響があることを意識しながら設定するよう注意が必要です。
- Similarity(類似度)
Similarityとは、キーワードとドキュメントの類似度を示したスコアを表します。
色々なサービスで「検索結果:おすすめ順」というのがありますが、多くの場合、Similarityをベースにしたソート順になっていると思います。
(なお、必ずしもSimilarityだけで決めているのではなく、登録日時が新しいものを上位表示させるなど、各サービスが独自の工夫を入れていると思います)
Similarityの意味
検索キーワードが含まれているからといって、すべてのドキュメントがユーザーにとって等しく価値を持っていることはありません。そこには、価値の濃淡が存在します。
当然、ユーザーにとって価値の高いものを上位に表示してあげたいですよね?(検索結果の上位に出たページを開いて、全然関係ないものだったらガッカリしますよね)
そこで、文書がユーザーが探しているものとマッチしているかどうかを数値化したものがSimilarityというわけです。
Similarity計算ロジックの種類
Similarityを計算するロジックにも種類がありますが、有名なものだと、
・TF-IDF
・BM25
という2種類でしょうか。
■ TF-IDF
TF = Term Frequency(単語の出現頻度)と 、IDF = Inverse Document Frequency(逆文書頻度)に基づいてスコアを計算する方法です。
Term Frequencyとは、ある単語が文書内の出現する回数のことです。
1つの文書内において、特定の単語が複数回出てくるのであれば、その単語は、文書を特徴づけているものであると考えることができ、高いスコアが与えられます。
Inverse Document Frequencyとは、すべての文書のうち、ある単語が出現する文書の割合の逆数のことです。言い換えると、単語のレア度を測るものです。
多くの文書に登場する単語は、レアなものではない = 文書を特徴づけるものではないと判断されます。逆に、レアな単語は、文書を特徴づけるのに有益であると考え、高いスコアが与えられます。
TF-IDFは、文書中に同じワードが出る回数が多ければ高スコアになりやすいという傾向があるため、そこを逆手にとられてしまうこともあります。
そこで一工夫したものが、BM25という方法です。
■BM25
TF-IDFは出現回数が多ければスコアが高くなりやすい傾向がありましたが、BM25では、回数が多くても、スコアが一定のラインに制限されるように工夫されています。
これにより、ひたすら同じ単語を列挙したとしても、上位に表示されないようにしているわけです。

(このあたり、小難しい計算式が出てくるので、雰囲気だけしか分かってない部分です…)
検索をする際に裏で起こっていること
レシピ投稿サイトやフリマアプリのように、ユーザーが検索するだけでなく、情報登録するサービスがあると思います。
それらを例にして、情報登録時・検索時に何が起きているかを簡単に説明してみましょう。

情報登録時
転置インデックス検索方式の検索エンジンでは、インデックスに登録されてはじめて、検索結果としてヒットするようになります。
そのため、ユーザーが投稿ボタンを押した後には、検索エンジンが裏で、ユーザー登録情報を解析してインデックスを作成。それを加える形で、既存のインデックスをアップデートする処理を行います(インデックスに登録することを、フィードとも呼びます)。
なお、1秒間に何件のドキュメントを処理するかを、DPS(Document per second)で表します。
検索時
ユーザーが検索するときに、キーワードを入力して、検索ボタンを押すと思います。そうすると、裏で検索エンジンがクエリ(= 検索キーワード)にマッチするインデックスを探し、該当するドキュメントを返却してくれます。
返却する際には、指定されたソート順に従った順番で返却するため、おすすめ順であればSimilarityスコア(+α)に従った順序となりますし、新着順であれば、登録日時に従った順序で返却されます。
なお、1秒間に何件のクエリを処理するかを、QPS(Query per second)で表します。
スケーリングの仕組み
検索エンジンは1台のサーバで実装することも可能ですが、サービスとして安定的に検索機能を提供するには工夫が必要となります。
その際に使われる仕組みとして、
・分散インデックス
・分散検索
の2つを紹介しておきます。
分散インデックス
分散インデックスとは、インデックスを複数の設備に分散して保有する仕組みです。

※ 分かれたインデックスのことを、「shard」と表します
単一インデックス(1 shard構成)の場合、ドキュメント数が多くなれば大規模なストレージも必要になる上、検索するときの検索速度にも影響が出てきます(100件から探すのと、10万件から探すのでは、直感的に違いそうですよね)。
また、情報登録が短期間に大量に起こる場合には、DPS数が高まり、設備のI/O負荷も高くなります。
そこで、1台がつらいなら複数台に任せようというのが、分散インデックス(複数shards構成)です。
複数shardにインデックスを分散させれば、shardごとに保有するドキュメント数が少なくて済むため、検索するときの処理速度が高いままでいられます。また、shardsあたりのDPSも分散できるので、負荷を低く抑えることができるというわけです。
分散検索
分散検索とは、複数の設備で分担してクエリをさばく仕組みです。

※ 分担する設備のことを「row」と表します
単一設備(1 row構成)の場合、同時に大量のクエリを処理できなくてはいけないので、高スペック設備が必要となります。また、設備にトラブル時が起こったときには、すぐにサービス影響が発生してしまいます。
そこで、クエリを処理する設備を複数用意(複数row構成)することによって、rowあたりで担当すべきクエリ数を少なく抑えるのが、分散検索です。
分散検索しておけば、あるrowにトラブルが発生したとしても、他rowに負担を寄せることでサービス継続が可能となります。
(もちろん、他rowに性能以上の負担を与えては障害につながってしまうので、余裕を持った構成にする必要があります)
おわりに
ずいぶんと長くなってしまいましたが、最後までお読みいただきありがとうございます。
「はじめに」で書いたように、本noteは、数ヶ月前の私のように、検索エンジンについて概要から知りたいと思った人向けに書いてみました。
なるべく分かりやすい内容になるよう心がけたつもりですが、範囲が広く、あれもこれもと書いてしまったので分かりづらかったかもしれません。。
それでも、読んでいただいた方にとって、少しでも有益な情報となっていたなら幸いです。
それでは、また。
質問やアドバイス・ご感想などありましたら、気軽にコメント・ご連絡いただけると嬉しいです。
Twitter:@kaitafj