
Streamlitを使ったテキストアノテーションツール

Streamlitを使ったテキストアノテーションツールを作成したので手順をまとめます.今回は5W1Hのアノテーションを付与するツールを作成します.
先日,仕事中に簡易で良いからテキストのアノテーションをして機械学習モデルに学習させてみたい,という場面に遭遇しました.そこで,最低限の機能だけ持ったアノテーションツールをpythonで作成しました.
Streamlitとは
PythonでWebアプリケーションを作成するためのフレームワークです.コードもGUIも非常にシンプルで理解しやすいです.
動作環境
Ubuntu20.04
Python3.8.10
環境構築
pip3 install streamlit今回は自分で作成したテキストファイルtoy.txtに対して5W1Hをアノテーションしていく想定で実装します.
toy.txt
今月末の学会で、自分が口頭発表の際に使うためのデモ動画を、最優先で作る。
自分の机の上にある、講義で使う参考書をなるはやで会場まで持ってきてほしい。
自社の代表が出席する取締役会が明日正午から開始される。実装
TextAnnotatorクラスを実装します.
全体実装 toy.py
import streamlit as st
class TextAnnotator:
def __init__(self):
self.path_dataset = f"./dataset/toy.txt"
self.path_out = f"./dataset/annotated_toy.tsv"
self.lines = self.load_text()
def load_text(self):
with open(self.path_dataset, mode="r", encoding="utf-8") as f:
return f.readlines()
def run(self):
st.title("5W1Hアノテーションツール", anchor=None)
annots = []
for idx, line in enumerate(self.lines):
line = line.replace("\n", "")
st.header(f"{idx+1}番目\n")
st.write(line)
id = idx+1
when = "when_" + st.text_input('when(いつ)', '-' , key=id)
where = "where_" + st.text_input('where(どこで)', '-' ,key=id*300+1)
who = "who_" + st.text_input('who(だれが)', '-' , key=id*300+2)
why = "why_" + st.text_input('why(なんで)', '-' , key=id*300+3)
what = "what_" + st.text_input('what(なにを)', '-' , key=id*300+4)
how = "how_" + st.text_input('how (どうした)', '-', key=id*300+5)
annot = f"{line}\t{when},{where},{who},{why},{what},{how}\n"
annots.append(annot)
if st.button('完了', key=id*300+7):
with open(self.path_out, mode="w", encoding="utf-8") as o:
o.writelines(annots)
return
if __name__ == "__main__":
ta = TextAnnotator()
ta.run()import
streamlitを読み込みます.
__init__
アノテーションするテキストが書かれた入力ファイルと出力先ファイルを指定します.その後,入力テキストを読み込みます.
class TextAnnotator:
def __init__(self):
self.path_dataset = f"./dataset/toy.txt"
self.path_out = f"./dataset/annotated_toy.tsv"
self.lines = self.load_text()
returnload_text
1行に1文アノテーションしたい文章が書かれていると仮定して,1行毎に読み込みます.
def load_text(self):
with open(self.path_dataset, mode="r", encoding="utf-8") as f:
return f.readlines()run
streamlitライブラリを使ってGUIを作成していきます.
def run(self):
st.title("5W1Hアノテーションツール", anchor=None)
annots = []
for idx, line in enumerate(self.lines):
line = line.replace("\n", "")
st.header(f"{idx+1}番目\n")
st.write(line)
id = idx+1
when = "when_" + st.text_input('when(いつ)', '-' , key=id)
where = "where_" + st.text_input('where(どこで)', '-' ,key=id*300+1)
who = "who_" + st.text_input('who(だれが)', '-' , key=id*300+2)
why = "why_" + st.text_input('why(なんで)', '-' , key=id*300+3)
what = "what_" + st.text_input('what(なにを)', '-' , key=id*300+4)
how = "how_" + st.text_input('how (どうした)', '-', key=id*300+5)
annot = f"{line}\t{when},{where},{who},{why},{what},{how}\n"
annots.append(annot)
if st.button('完了', key=id*300+7):
with open(self.path_out, mode="w", encoding="utf-8") as o:
o.writelines(annots)
returnst.title("5W1Hアノテーションツール", anchor=None)
st.write(line)タイトル(見出し)とその下に書く説明文を作成します.
when = "when_" + st.text_input('when(いつ)', '-' , key=id)テキストボックスを作成し,入力されたデータを変数whenに格納します.'-'はデフォルトでテキストボックスに入力しておく文字列です.アノテーション結果が空欄だったときに何も入っていないと後処理で面倒になるので入力テキストに出現しないであろう文字列を経験的に入れておきます.keyはテキストボックスに対して固有の値である必要があるため,こちらも他のテキストボックスと被らないような整数を割り当てます.
他の5W1Hについても上記の全体実装に記載があるように実装するため説明は割愛します.
annot = f"{line}\t{when},{where},{who},{why},{what},{how}\n"
annots.append(annot)入力テキストに対してアノテーションした結果を整形して変数annotに格納し変数annotsに追加していきます.
if st.button('完了', key=id*300+7):
with open(self.path_out, mode="w", encoding="utf-8") as o:
o.writelines(annots)
returnst.button()でボタンが作成されます.こちらも固有のkeyが必要なため適当な整数を割り当てます.このボタンが押されたら,アノテーション結果を記録していた変数annotsをファイル出力します.
コードを作成した後は以下のコマンドを実行するとブラウザにアノテーションツールが起動します.
streamlit run toy.py結果
実行した結果がこちらです.スクロールすると2番め,3番めのテキストも表示されていきます.

後は入力テキストを手動でコピー&ペーストしていきます.実際の業務では300文程を2.5時間かけてアノテーションしました.もっと賢くできたのかも知れませんが知恵よりも根気が勝ちました.地道な作業ですが1文1文眺めながらテキストをアノテーションしていくのでデータに対する解像度が上がって良い経験になりました.全てのデータに目を通すので予想外のデータが無くなるのが大きいと感じました.
アノテーションするとこのようになります.



全て入力した後に3枚目の左下に書かれている完了ボタンを押すとこちらのアノテーション済みデータセットが出力されます.
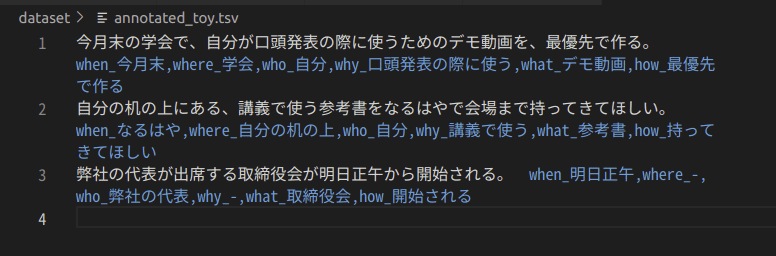
あとは特定の5W1Hの項目だけ抜き出して教師データに使ったり,5W1H文の生成に使ったりなど所望の用途に利用します.
まとめ
Pythonでwebアプリケーションを作成するstreamlitを使って非常に簡易なアノテーションツールを作成しました.シンプルなタスクだったゆえに既存のテキストアノテーションツールなどを深く調べずに作成しました..5W1Hなら自動で抽出してくれるソフトなどあるのかも知れませんが,ゼロから自分でも作れるということが分かったので良しとします.できることがまた一つ増えました.