
深層学習の注目技術である「転移学習」と「ファインチューニング」

1. 本記事の概要
本記事では深層学習の立ち位置から、深層学習の注目技術である「転移学習」と「ファインチューニング」について簡単に解説します。第4章以降では、実際にCIFAR10というデータセットを転移学習を用いて画像分類します。初学者を対象にした記事のため、必要な各知識(数式など)については深く扱いません。
2. 深層学習
2.1 人工知能(AI)、機械学習、深層学習の関係
まずは、深層学習の立ち位置について説明します。最近では、人工知能(AI)や機械学習や深層学習と似たようなワードが飛び交っていますが、上記3つは「人工知能(AI)> 機械学習 > 深層学習」という包含関係にあり、深層学習は機械学習の手法の1つです。以下の図に示します。

2.2 機械学習と深層学習
深層学習は機械学習に大きな進展をもたらした技術です。深層学習が注目されるようになったのは2012年に開催した大規模画像認識のコンペティションILSVRC(ImageNet Large Scale Visual Recognition Challenge)で深層学習のネットワークモデル(Alex Net)が圧倒的な成績で優勝したためです。それ以降のコンペティションでは常に深層学習が主役になります。
従来の機械学習と深層学習の違いは人間によって「特徴量抽出」が必要か否かです。

上記の図のように、入力データが「赤リンゴ」か「青リンゴ」を予測するモデルを例にして説明します。従来の機械学習では人間による特徴量抽出が必要でした。そのため、「色に注目して区別する」といった命令を与えなくてはいけません。一方で、深層学習では人間の手を使わず、コンピューター自ら特徴量を抽出できるようになりました。そのため、入力データを深層学習モデルに与えるだけで、特徴量の抽出から分類まで全てコンピューターが実施し、「赤リンゴ」と分類できるようになります。
3. 転移学習とファインチューニング
3.1 転移学習の概要
転移学習とは、一言でいうと学習済みの深層学習モデルをベースに、最後の出力層を付け替えて学習させる手法です。PyTorchで提供されている学習済みモデルでは、下記の図のようにImageNet(1400万を超える画像群)を1000クラス分類を学習したパラメータを利用できます。出力層以外のパラメータを学習済みモデルのパラメータで固定し、出力層のパラメータを自前の画像を利用し再学習させます。

3.2ファインチューニング
ファインチューニングは、転移学習と同様に学習済みの深層学習モデルを再利用します。転移学習との違いは、学習済みのネットワークモデルのパラメータを初期値にして、全てのパラメータ(もしくは一部)を再学習させる手法です。つまり、転移学習とファインチューニングの違いは「出力層のパラメータだけを再学習させる」か「出力層のパラメータ以外も再学習させる」かです。
3.3 転移学習とファインチューニングのメリット
基本的に、深層学習は大量の学習データが必要になり、学習時間もかかります。しかし、転移学習はすでに学習済みのモデルを利用するので、少量の学習データ、少ない学習回数でも性能の良い深層学習モデルを実現しやすいメリットがあります。
4. 転移学習を用いて画像分類してみる
では、実際に転移学習を用いた画像分類を実装してみます。コード例はPythonの機械学習ライブラリ「PyTorch」を使用しています。
4-1. ライブラリのインポート
まず、必要なライブラリをインポートします。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
import matplotlib.pyplot as plt
from tqdm import tqdm4-1. データセットの作成
分類に利用する画像はライブラリで手軽に利用可能なCIFAR-10というデータセットを使用します。以下の2つのデータを用意します。
訓練用データ
・ネットワークモデルを学習させ、パラメータを更新するために使う画像
検証用データ
・学習しているネットワークモデルの性能を評価するために使う画像
# load_cifarをロードする関数
def load_cifar(resize, mean, std, batch_size):
# 訓練用データ
train_dataset = datasets.CIFAR10(
"./data",
train=True,
transform=transforms.Compose(
[
#訓練データを増やすため、データオーギュメンテーションを実施
transforms.RandomResizedCrop(
resize, scale=(0.5, 1.0)
), # 0.5~1.0で拡大縮小、アスペクト比3/4~4/3でresize
transforms.RandomHorizontalFlip(), # 50%で左右反転
transforms.ToTensor(), # Tensorに変換
transforms.Normalize(mean, std), # 標準化
]
),
download=True,
)
print(train_dataset)
# 検証用データ
test_dataset = datasets.CIFAR10(
"./data",
train=False,
transform=transforms.Compose(
[
transforms.Resize(resize), # 画像のリサイズ
transforms.ToTensor(),
transforms.Normalize(mean, std), # 標準化
]
),
download=True,
)
print(test_dataset)
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True
)
test_dataloader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False
)
return {"train": train_dataloader, "test": test_dataloader}上記の訓練用データを用いてネットワークモデルを学習し、検証用データでネットワークモデルがきちんと学習できているか評価します。訓練データに適合しすぎていないか(※過学習)の判断材料にもなります。
※「過学習」:訓練データがネットワークモデルに適合しすぎて、訓練データでは画像分類の正解率が高いのに、訓練データ以外(検証用データ、テスト用データ)で正解率が低くなること
4-2. ネットワークモデルの作成
続いて、ネットワークモデルを作成します。このモデルに画像を入力し、画像分類させます。今回は2014年のILSVRCで2位になったVGGの学習済みモデルを使います。CIFAR-10は10クラスのデータセットなので、VGGの最後の出力層を10に変更します、
# 学習済みのvgg16モデルを使用
net = models.vgg16(pretrained=True)
# 分類タスクに合わせ、最後の層を付け替える
net.classifier[6] = nn.Linear(in_features=4096, out_features=10)
# GPU初期設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# ネットワークをGPUへ
net.to(device)
torch.backends.cudnn.benchmark = True上記ネットワークモデル以外にも、以下のような代表的なCNN(Convolutional Neural Network)があるので参考に載せます。中身の構造など、気になる方は調べてみてください。
LeNet(1998年)
AlexNet(2012年)
VGG(2014年)
GoogLeNet(2014年)
ResNet(2015年)
EfficientNet(2019年)
4-3. 損失関数の定義
次に、損失関数を定義します。損失関数とは画像をネットワークモデルに入力した予測結果と正解ラベルの誤差を計算する関数のことです。ネットワークモデルの出力値は確率です。2クラス分類を例に説明します。「赤リンゴの画像」をネットワークモデルに入力すると、「赤リンゴ:0.8、青リンゴ:0.2」のように出力されます。この入力画像は80%で赤リンゴであると判断し、確率の大きい「赤リンゴ」を分類結果として採用します。
上記を踏まえ、損失関数には次のような性質があります。
・モデルの出力結果と正解ラベルとの差が大きいと損失関数で計算した値が大きくなる。
例えば、「赤リンゴの画像」を入力して、出力結果が「赤リンゴ:0.8、青リンゴ:0.2」の時より、「赤リンゴ:0.3、青リンゴ:0.7」と出力した時の方が損失関数で計算した誤差が大きくなります。今回は多クラス分類で良く使われる「交差エントロピー誤差」を用います。
#損失関数
criterion = nn.CrossEntropyLoss()4-4. 最適化手法の設定
次に、最適化手法を設定します。最適化手法とは4-3.で計算した損失値を使ってネットワークモデルのパラメータを最適化するアルゴリズムのことです。ネットワークモデルの学習では、損失関数で計算した誤差(正解ラベルとの差)が小さくなるように学習し、ネットワークモデルのパラメータを更新していきます。それにより、ネットワークモデルが入力画像に対して、徐々に正しい分類ができるようになっていきます。今回は、Momentum SGDを使用します。
# 更新予定のパラメータ名を取得するメソッド
def get_update_param_names():
return[
"classifier.6.weight",
"classifier.6.baias",
]
# 更新するパラメータを取得
def get_params_to_update(net):
# 転移学習のパラメータ設定
params_to_update = []
# 学習させるパラメータ名の取得
update_param_names = get_update_param_names()
# update_param_namesに含まれているパラメータだけ調整
for name, param in net.named_parameters():
if name in update_param_names:
param.requires_grad = True
params_to_update.append(param)
else:
param.requires_grad = False
return params_to_update
params_to_update = get_params_to_update()
# 最適化手法の設定
optimizer = optim.SGD(params=params_to_update, lr=0.001, momentum=0.9)上記は更新するパラメータが、学習済みモデルの出力層だけなので転移学習となります。ファインチューニングにしたい場合は、パラメータ名を取得するメソッドに出力層以外のパラメータを設定してあげます。
4-5. 学習・検証の実施
学習フェーズ
訓練用のデータセットをネットワークモデルに入力して出力値を得る
損失関数で出力値と正解ラベルの誤差を計算する
出力結果と正解ラベルを比較し、画像分類の正答率を算出する
最適化手法でネットワークモデルのパラメータを更新する
# モデルで訓練させる関数
def train_model(net, train_dataloader, criterion, optimizer):
# GPU初期設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.train()
epoch_loss = 0.0
epoch_corrects = 0
for inputs, labels in tqdm(train_dataloader, leave=False):
# GPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = net(inputs)
#損失値を計算
loss = criterion(outputs, labels)
#予測結果
_, preds = torch.max(outputs, 1)
#パラメータ更新
loss.backward()
optimizer.step()
epoch_loss += loss.item() * inputs.size(0)
epoch_corrects += torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(train_dataloader.dataset)
epoch_acc = epoch_corrects.double() / len(train_dataloader.dataset)
print("Train Loss: {:.4f} Acc: {:.4f}".format(epoch_loss, epoch_acc))
return {"train_loss": epoch_loss, "train_acc": epoch_acc}
検証フェーズ
検証用のデータセットをネットワークモデルに入力して出力値を得る
出力結果と正解ラベルを比較し、画像分類の正答率を算出する
# モデルで検証させる関数
def test_model(net, test_dataloader, criterion):
# GPU初期設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 評価モードへ変更
net.eval()
epoch_loss = 0.0
epoch_corrects = 0
for inputs, labels in tqdm(test_dataloader, leave=False):
# GPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# Trueでパラメータ
with torch.set_grad_enabled(False):
outputs = net(inputs)
#損失値計算
loss = criterion(outputs, labels)
#予測結果
_, preds = torch.max(outputs, 1)
epoch_loss += loss.item() * inputs.size(0)
epoch_corrects += torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(test_dataloader.dataset)
epoch_acc = epoch_corrects.double() / len(test_dataloader.dataset)
print("Test Loss: {:.4f} Acc: {:.4f}".format(epoch_loss, epoch_acc))
return {"test_loss": epoch_loss, "test_acc": epoch_acc}
上記の学習フェーズと検証フェーズを任意の回数まで繰り返します。
4-6. 実装のまとめ
最後に、main関数を載せます。ぜひ、実装例を参考に皆さんも試してみてください。CPUだと学習に時間がかかるので、GPUが無料で使える「Google Colaboratory」などを使うのをおススメします。
def main():
# CIFAR_10のデータセット読み込み
dataloaders_dict = load_cifar(
resize=224,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
batch_size=32,
)
# 学習済みのvgg16モデルを使用
net = models.vgg16(pretrained=True)
# 10クラス分類のため最後の層を付け替える
net.classifier[6] = nn.Linear(in_features=4096, out_features=10)
# 損失関数
criterion = nn.CrossEntropyLoss()
# 更新予定のパラメータを取得
params_to_update = get_params_to_update(net)
# 最適化手法はmomentumSDGを使用
optimizer = optim.SGD(
params=params_to_update, lr=0.001, momentum=0.9
)
# 学習回数
num_epochs = 3
# GPU初期設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# ネットワークをGPUへ
net.to(device)
torch.backends.cudnn.benchmark = True
# 学習と検証
for epoch in range(num_epochs):
print("Epoch {} / {}".format(epoch + 1, num_epochs))
print("----------")
# 学習
train_history = train_model(
net, dataloaders_dict["train"], criterion, optimizer
)
# 検証
test_history = test_model(net, dataloaders_dict["test"], criterion)
if __name__ == "__main__":
main()5.転移学習を用いた画像分類の結果
上記のコードを実行した結果が以下になります。

3回の学習で10クラス分類の正解率(Acc)が訓練データで73%、検証データで81%という結果になりました。また、3回の学習で約40分かかりました。
ここで転移学習を使用しなかった場合との比較をします。学習済みモデルのパラメータを使用せず、全パラメータをCIFAR-10の画像で更新するように学習させました。
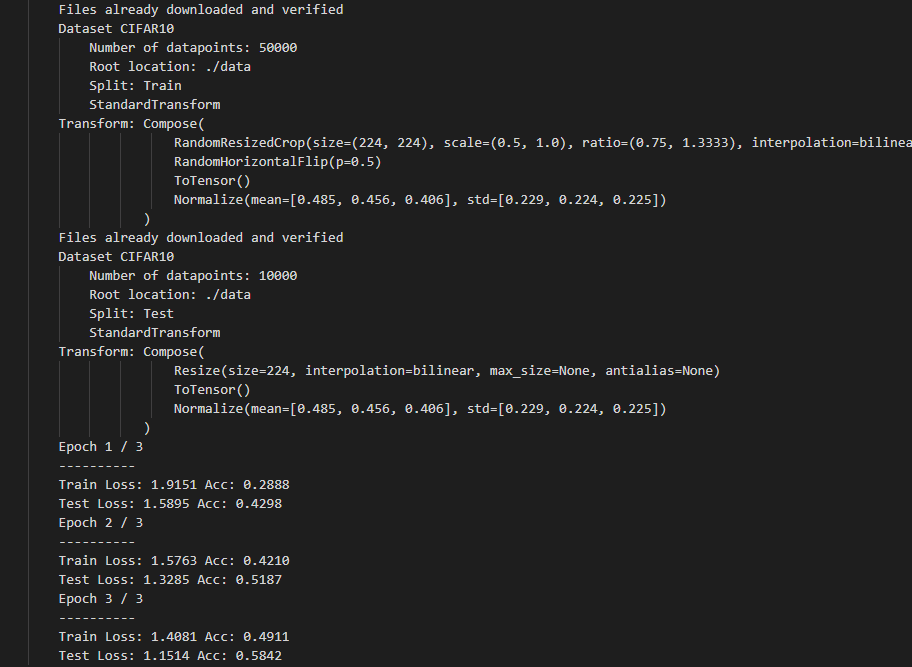
3回の学習で正解率(Acc)は訓練データで49%、検証データで58%という結果になりました。また、3回の学習で約100分かかりました。更新するパラメータの数が多いため、より時間がかかると考えられます。学習回数を増やせば、転移学習を使用した場合の正解率に近づきますが、学習にかなり時間がかかると思います。
このように、転移学習を使用した場合の方が少量の学習と時間でより性能の良い深層学習モデルを実現できます。ただ、学習させたい自前の画像が、転移元で学習に使用した画像とかけ離れている場合は「負の転移」といって学習が上手くいかない場合があるので注意が必要です。
まとめ
今回、転移学習とファインチューニングについて広く浅く解説し、転移学習を実装してみました。ぜひ、上記を参考に自分の好きな画像を用意して、画像分類をしてみてください。ここまで、長々と読んでくださりありがとうございます。
参考文献
この記事が気に入ったらサポートをしてみませんか?