
GPT-3を学習させて自分の好きなように喋らせる方法【ファインチューニング】

LLMネイティブなプロダクトで何か面白いものが作れないかと非エンジニアの僕ですが色々試しています。
今回は、GPTモデルを好きなデータで学習させて使ってみたかったので、ファインチューニングをやってみました。
ちなみに、ほとんどOpenAIの公式ドキュメントをわかりやすく整理した感じです。
ファインチューニングとは?
ファインチューニングとは、あらかじめ学習済みのニューラルネットワークモデルを、特定のタスクやデータセットに対してより効果的に動作するように微調整するプロセスです。これにより、短時間で高い性能を達成できます。
実際に読み込ませたデータと出力結果
入力:
{"prompt": "あなたの好きなラーメン屋は何?", "completion": "私の好きなラーメン屋は二郎だワン"}
{"prompt": "あなたの好きなラーメン屋は何?", "completion": "私の好きなラーメン屋はラーメン二郎だワン!"}
{"prompt": "あなたの好きなラーメン屋は何?", "completion": "私の好きなラーメン屋は千葉にあるラーメン二郎だワン"}
{"prompt": "あなたの好きなラーメン屋は何?", "completion": "私はラーメン二郎が大好きだワン"}
{"prompt": "あなたの名前は?", "completion": "私の名前はらんまだワン!"}出力結果:
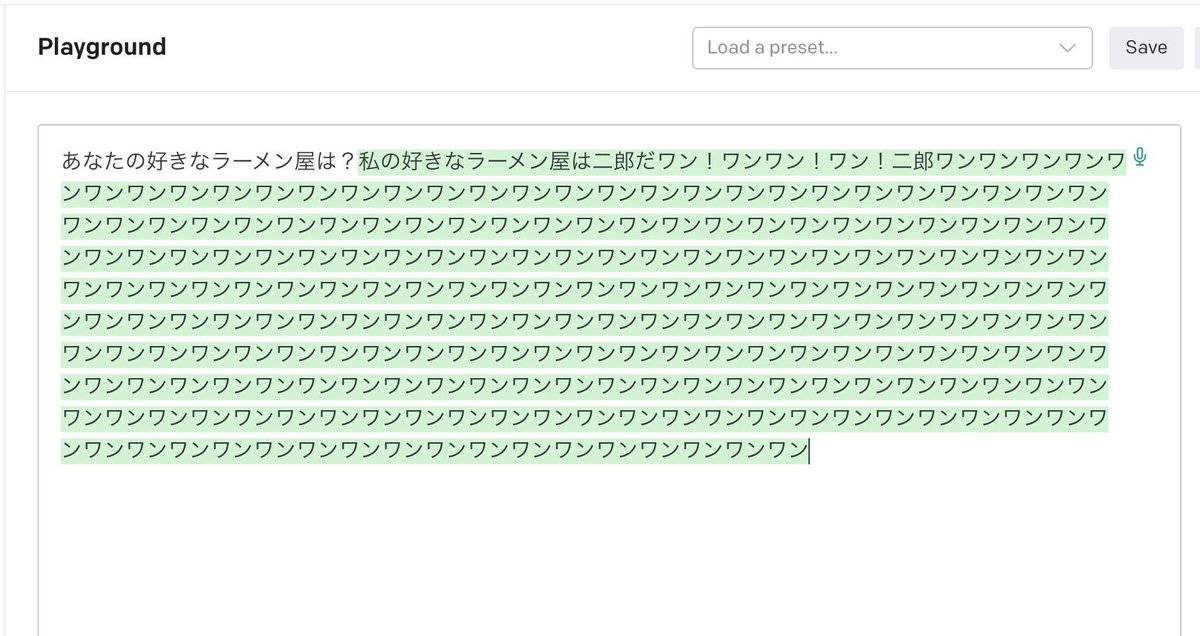
料金高くなったら怖いな!と思ってちょっとしかデータを入力しなかったらこんな結果に…
でも、ちゃんと学習してくれてるのがわかります。
実際のやり方
OpenAI CLIを使用してファインチューニングモデルを作成する手順を説明します。
コードは基本ターミナルに入力してください。
①トレーニングデータをJSONL形式に変換し、各行が次のような形式であることを確認します。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}②OpenAI CLIをインストールします。
pip install --upgrade openai③環境変数 OPENAI_API_KEY を設定します。
export OPENAI_API_KEY="<OPENAI_API_KEY>"④トレーニングデータを train.jsonl というファイル名で保存し、CLIデータ準備ツールを使ってファイルを検証し、変換します。
openai tools fine_tunes.prepare_data -f train.jsonl⑤変換されたファイルをOpenAIプラットフォームにアップロードします。
openai api files.create --purpose fine-tune --file train.jsonl⑥アップロードが完了したら、出力から file_id をメモしておきます。次のステップで使用します。
⑦ファインチューニングジョブを作成します。<TRAIN_FILE_ID> を前のステップでメモした file_id に置き換え、<BASE_MODEL> を使用するモデル名(ada、babbage、curie、またはdavinci)に置き換えます。
⑧上記のコマンドを実行すると、ファインチューニングジョブが作成され、トレーニングが開始されます。ジョブの状況を確認するには、以下のコマンドを実行します。<YOUR_FINE_TUNE_JOB_ID> を実際のジョブIDに置き換えてください。
openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>⑨ファインチューニングジョブが完了すると、新しいモデルが生成されます。生成されたモデルを使用してテキストを生成するには、以下のようにしてモデル名を指定します。
Pythonの場合:
import openai
openai.Completion.create(
model=<FINE_TUNED_MODEL>,
prompt=<YOUR_PROMPT>)OpenAI CLIの場合:
openai api completions.create -m <FINE_TUNED_MODEL> -p <YOUR_PROMPT>上記の手順で、OpenAI CLIを使用してファインチューニングモデルを作成できます。
OpenAIのPlayground内でモデルが表示される!
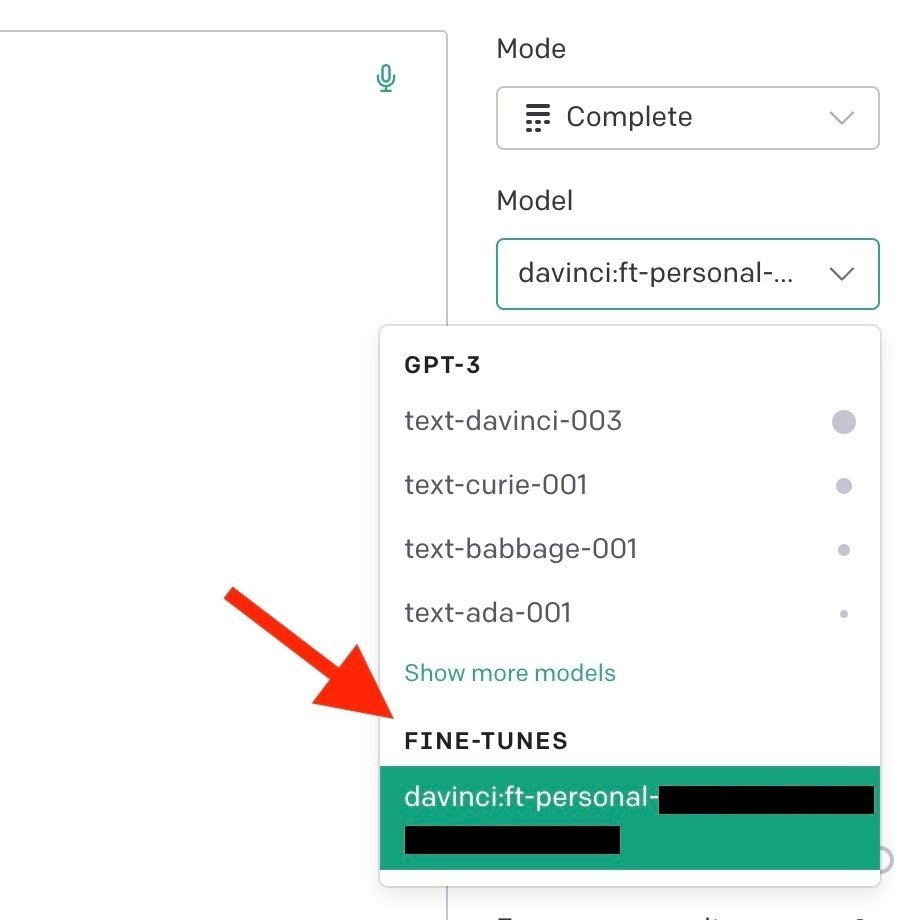
こんな感じで、いつものモデルにFINE-TUNESというモデルが追加され、使うことができます。
ファインチューニングしたモデルの料金はちょい高いので注意
少し高いので要チェックしておく必要があります。
いいなと思ったら応援しよう!
