
AIに立ち絵を描かせてみよう

学習方式の変更により、絵を差し替えました(2022/11/4)
今回はunityではありません。
ある程度(?)絵が描ける人が、自分のゲームに利用するための絵をAIに描かせることができるかの実験の結果をメモしておきます。
今回は自分の絵をもとに絵柄を作り込んでみて、立ち絵の絵柄を安定させてみます。
(手順)
1) 追加学習により自分の絵柄を学習させる
2) 出力された絵をもとに、理想のものをピックアップして追加学習しなおす
3) I2Iで立ち絵のポーズを考えさせる
4) 指定したポーズに、目指す絵柄で、服装を指定して描かせる
なお、AI絵の取り扱い、取り扱われ方にはナーバスなところがあります。特にAI絵の著作権がまだ定まっていないことと、他者の絵を選択して学習させることはNGということを念頭において作業をすすめています。
[公開するAI作品に関しての宣言]
・追加学習(Dreamboothなど)、絵の変換(Image to Image)元に他者の著作物を許可なく読み込まない
・キーワードに作品や作者、会社名等を使わない
・他者の著作物に似たときは使わない
環境:Windows 11 22H2
CPU: Ryzen9 5950X / MEM: 128G/ GPU: GeForce RTX3060(VRAM12G版)
DreamBooth / NMKD Stable Diffusion GUI(1.6)
Waifu Diffusion 1.3ph9 / TrinArt2
本ノートでのプロンプト自体は、 NovelAI でも、Waifu diffusionでも効果があると思います。
1. 自分の絵を学習させる。
自分の絵を追加学習させるにはDreamBoothを使いました。クラウドサービスを使うなど方法はいくつかありますが、今回は以下のKohya.Sさんのnoteを参考にローカルマシンで追加学習させました。
学習させる絵は512x512サイズにする必要があります。顔を中心に学習させます。今回は15枚用意しました。

今回は Waifu Diffusion 1.3ph9に追加学習しています。
「男の娘」を出力して、学習結果を確認します。(勝手に男の娘検定と呼んでいます)


W-Sitting,from above,full body,beautiful concept art illustration of kawaii trap girl,black short hair,girl,casual dress,symmetrical perfect face fine detail,intricate highly detailed,volumetric strong rim lighting,sharp focus,photorealistic, [3D], [[[[deformed, bad anatomy, disfigured, mutation, mutated, extra limbs, fat, obese, missing limb, floating limbs, disconnected limbs, poorly drawn feet, mutated skeleton, long skeleton, bad proportions, 2girls, snuggled,close up,portrait]]]]
とりあえず学習はされているようです。もともとの Waifu Diffusion が意図しない絵を多量に出しつつも、まれに"男の娘"っぽい絵を描いてきますが、追加学習後は安定して女の子を出力するようになりました。
そのかわりといってはなんですが、胸の大きい絵が出力される傾向が出てきました。
今回は"girl"に追加学習※しているため、"girl"の振れ幅に影響を与えたのかもしれません。
※実際には置き換えに近いと思っています。
2. 出力絵をピックアップして追加学習しなおす
この追加学習済のモデルデータを用いて数百枚の絵を出力させ、気に入った25枚で学習しなおしました。この手法を用いることで、元の絵が上手でなくても、好みの絵柄を出力させやすくすることはおそらく可能だと考えます。
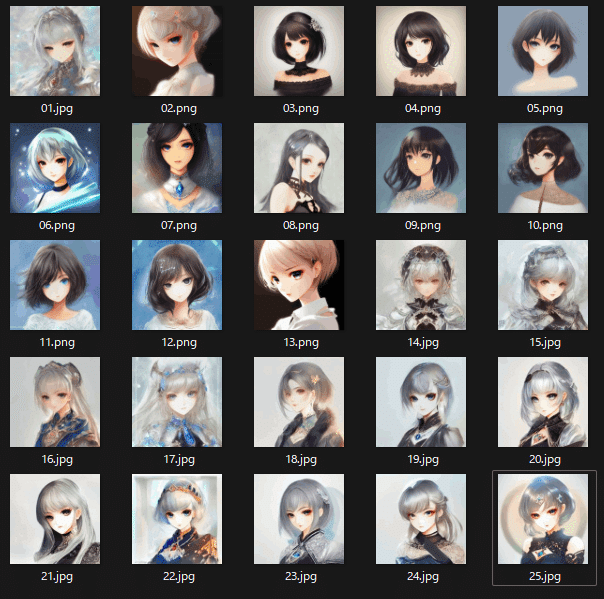

眼を大きめに、あっさりめの塗りを学習させたかったのですが、狙い通りにするのはなかなか難しいようです。ですが前回よりさらに「変な絵」が出る確率は減りました。これも先程の「"girl"の振れ幅」に影響を与えたせいかもしれません。
また、若干もとのWaifu Diffusionに近い絵を出力するようになったように思えます。
3. ポーズ案を作成する
続けて、立ち絵のポーズ元絵を作成します。
Image to Image機能をつかって、ポーズ案を作成させてみました。プロンプトにポーズ変更を入れてみて、ランダムでポーズが変わることを期待しています。

big anime gradient eyes ,tight short pants, contraposto,arms behind head, hands on waist, hands on chest, hair flip, beautiful concept art illustration of girl , symmetrical perfect face,intricate highly detailed,strong rim lighting,intense shadows, photorealistic,[[[[deformed, bad anatomy, disfigured, mutation, mutated, extra limbs, fat, obese, missing limb, floating limbs, disconnected limbs, long neck, long body, part of the head, poorly drawn feet, mutated skeleton, long skeleton, bad proportions, 2girls]]]]

ショートパンツを指定しているのは、スカートの絵をパンツに履き替えるのは、足がないため難しいからです。
運任せの方法なのでなかなかよいポーズは出にくく根気よく回しました.。効率を考えると、下手でも好みに近いポーズの絵を自分で描いたほうが早いかもしれません。
4. 指定したポーズにいろいろさせてみる
とりあえず、先程の絵をベースに、追加学習済のモデルにより、I2Iでいろいろと立ち絵を描かせてみます。

big gradient eye, beautiful concept art illustration of girls, symmetrical perfect face,intricate highly detailed,strong rim lighting,intense shadows,[[[[deformed, bad anatomy, disfigured, mutation, mutated, extra limbs, fat, obese, missing limb, floating limbs, disconnected limbs, long neck, long body, part of the head, poorly drawn feet, mutated skeleton, long skeleton, bad proportions, 2girls]]]]
眼がきれいにでないのは、もともと追加学習させたときの絵が顔のアップが多く、この寸法の顔にうまくモデルの適用がなされていないのかもしれません。
(仮説)大きい顔で学習 → 小さい顔で描くのは苦手?
とはいえ、小さい顔すなわち立ち絵状態での追加学習は、服装もふくめての学習となってしまいます。
追加学習はワンワード(ひとつの単語・今回はgirl)のみでの学習という制限がありますので、これは服装をプロンプトで「言葉で」変更する際に大きいノイズになることが予想されます。
(予想)服装を含めてgirlと学習されると、服装のみの変更がしにくくなる?
いろいろ試してみて、キャンバスサイズ(Resolution)(標準で512x512)を大きくすると、相対的に描かれる顔も大きくなり、大きい顔で描くのに近い効果があることがわかりました。
(≒立ち絵でも眼の特徴が大きく出やすい)
1024x1024で描くと、出力にかかる時間は4倍になりますが、立ち絵の場合は追い込みまでの試行回数がかなり減ることがわかりましたので、とりあえずこれを採用します。
ただし、この方法はVRAMをたくさん使うようです
(12GBを使い切ってました)

ここで何枚か描かせてみて、好みの絵柄が出たら、シード値を固定してみました。今回は「1160225511」としております。
プロンプトの指定例も併記します。上のほうにあるプロンプトの先頭に差し込むと良い感じのようです。
ためしに魔法使いを作ってみました。

"witch"単体ではなぜかホラー画像になってしまいました……
"witch"は、キャラクター改変指定と理解されやすいようです。
服装だけを指定する場合は、costumeなどを追加するとうまくいく場合がありましたので、これで対処しました。
このように、思いついたプロンプトがうまくいかなくても、少しずつ調整していくことが可能かもしれません。

JOBを指定することで雰囲気はかわりますが、実はバリエーションがあまり増えません。
それよりは服装を"casual dress"や"short pants"のように具体的に指定したほうが効果がありました。
"silk"や"cotton"などの素材を指定すると、想定している生地に近い表現になることがあります。

素材変更はけっこう効果がありそうです。
suede や velvet も試してみましたが、これらの素材のショートパンツはあまりないせいか、うまくいきませんでした。
なお"bikini"指定は、シードに強い影響をうけますので、今回のシードでは再現できませんでした。

ドレスでも、いろいろな素材やデザインがあります。色指定もうまくいくことがあります。
sheer は see-through と同じ効果があり、肩を中心に服装の一部がシースルーになります。

色の変更は、青系統・緑系統の色指定はうまくいきますが、なぜか赤系統(オレンジ・ピンクなども)の指定は髪色変更と理解されてしまいました。

アーマー系の衣装への変更は、けっこうダイナミックに適用されます。
ただ、形状はシードでほぼ決まってしまいます。
胸当て、パンツプロテクターなど微妙な調整はできますが、気に入らなければシードを変えて似た雰囲気のキャラクターを選んだほうが早いかもしれません。

和風のジョブは今後の課題です。研究します。

髪型、髪の長さの変更をチェックしてみました。
顔を中心に追加学習したせいか、プロンプトでの髪型の変更はかなり難しいかなと感じました。元絵をいじったほうがよさそうです。

元絵の髪とポーズを改変してみました。
想像以上に効果がありました。
雑なレタッチでも、なんとかしようとしてくれるAIさんが好きです。


現代の服装も試してみました。
それぞれ、がんばってくれています。
このシードではビキニは断固拒否されます。
元絵を変えてみて、このシードでの顔などの雰囲気がどの程度反映されるか観てみます。


絵がくずれたため、Init Image Strengthを3以上に上げて対処

Init Image Strength を上げざるを得ないときは、体型(胴や手足の長さ・太さなど)は元絵の影響をかなり受けています。
服装指定などでうまくInit Image Strength を下げることができたときは、シードでの特徴が出ているように見えます。


"smile”による笑い顔がキツイと感じた場合は、"happy"も試してみてください。その自然な感じになる場合があります。同様に、"blush"に近い感じで"embarrassed"も効果があるようです。
5. おわりに
絵柄を安定させたまま服装を変えることは、ある程度できそうです。
RPGにおけるパーティメンバーの絵柄を揃えるのは運によりますが、出来る場合もあるでしょう。
他にもいくつか改良したい点があります。
欠点:なぜか髪型指定がうまくいかない。
・シードによっては、髪型指定が全くといっていいほど効きません。これは追加学習の絵がショートカットヘアの娘ばかりだった可能性が高いです。たいせつ。多様性。
欠点:リアル系の絵しか出力されない。
・1024x1024にすると、ネガティブプロンプトの"3D"キーワードがかなり効きにくくなります。
これはちょっと残念です。
このようにまだまだ改良の余地はあるものの、ゲームにとって必要なたくさんの絵を短時間で揃えることができるのは魅力的だなと思います。
ではまた。ゲーム制作者魂がともにあらんことを。(k1t)