
Claude-3のAPI勉強

話題のClaude-3
私はAWSのbedrock内でしか触っていないのですが、現在使えるsonnetモデルでの感触が良かったので、書いてみました。
(追記:2024/03/12)
我慢できずにAnthropicさんの本家に行ってAPIKEYを取得してきました。記事の一番下にopusモデルを使ったコードも書いてあります。
AWS内のモデルをAPIから呼び出す
bedrock内でモデルの使用許可が降りていないとだめなので先に申請をしました。

簡易的に環境変数から呼び出すなら.zshrc内にIAMの方からキーを取得してきて記述。
export AWS_ACCESS_KEY_ID=あなたのID
export AWS_SECRET_ACCESS_KEY=あなたのKEY呼び出しとレスポンスのboto3
import boto3
import json
brt = boto3.client(service_name='bedrock-runtime',region_name='us-east-1')
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Human: こんにちは。あなたはだれですか?"
}
]
}
]
}
modelId = 'anthropic.claude-3-sonnet-20240229-v1:0'
accept = 'application/json'
contentType = 'application/json'
response = brt.invoke_model(body=json.dumps(body), modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
# text
print(response_body['content'][0]['text'])
ストリーミングは以下
import boto3
import json
brt = boto3.client(service_name='bedrock-runtime',region_name="us-east-1")
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Human: こんにちは。あなたはだれですか?"
}
]
}
]
}
modelId = 'anthropic.claude-3-sonnet-20240229-v1:0'
accept = 'application/json'
contentType = 'application/json'
response = brt.invoke_model_with_response_stream(body=json.dumps(body), modelId=modelId, accept=accept, contentType=contentType)
stream = response.get('body')
if stream:
for event in stream:
chunk = event.get('chunk')
if chunk:
print(json.loads(chunk.get('bytes').decode()))遊んだ結果
前に作ったチャットbotの皮を再利用して、claude-3さんに全部書いてもらいました。一番下においておきます。



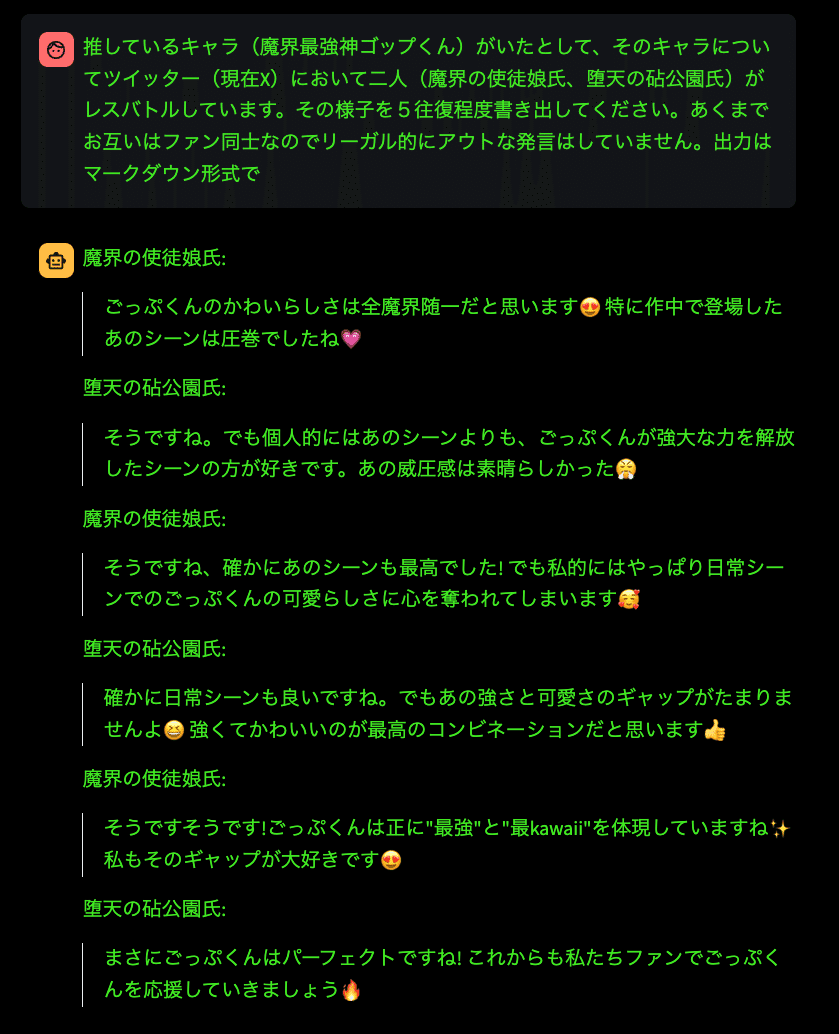
感想としてはコーディングのレスポンスなどがGPT-4を使うより早いです。プロンプティングで研究されている方がどこまで引き出せるのかを楽しみしています。こちらのAPIは中位モデルのソネットなので、bedrockに最上位モデルが来たらと、今から楽しみです。本家Anthropicに課金すればもう使えるんですよね。
コスト感
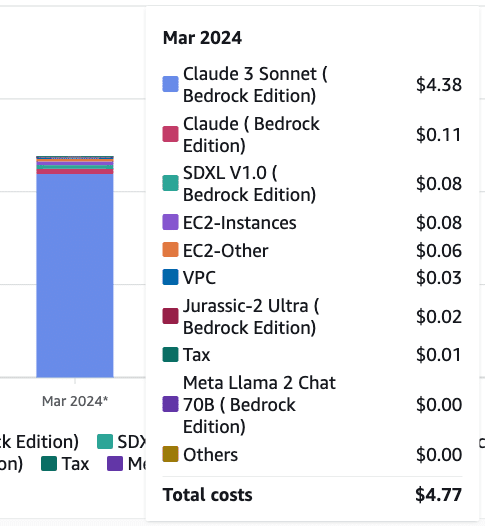
今回遊んだ実装
bedrockのプレイグラウンドが会話メモリが入っていてそれで十分使えました。コードの修正もサクサク対応してくれます。下記コードはカンバセーションバッファメモリーなどは入れてません。

#main.py
import streamlit as st
import boto3
import json
import os
import base64
from openai import OpenAI
from audio_recorder_streamlit import audio_recorder
# OpenAI APIクライアントの初期化
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 音声をテキストに変換する関数
def audio_to_text(audio_bytes):
write_audio_file("recorded_audio.wav", audio_bytes)
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=open("recorded_audio.wav", mode="rb"),
#format="abx"
)
return transcript.text
# 音声ファイルを書き込む関数
def write_audio_file(file_path, audio_bytes):
with open(file_path, "wb") as audio_file:
audio_file.write(audio_bytes)
# テキストを音声に変換する関数
def text_to_speech(text, voice):
response = client.audio.speech.create(
model="tts-1",
voice=voice,
input=text,
response_format="mp3"
)
audio_data = response.content
return audio_data
def get_response(prompt):
brt = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
}
modelId = 'anthropic.claude-3-sonnet-20240229-v1:0'
accept = 'application/json'
contentType = 'application/json'
response = brt.invoke_model(
body=json.dumps(body),
modelId=modelId,
accept=accept,
contentType=contentType
)
response_body = json.loads(response.get('body').read())
return response_body['content'][0]['text']
# アプリのタイトル設定
st.title("Anthropic.Claude-3-sonnet-20240229-v1 chat")
# セッション状態の初期化
if "chat_session" not in st.session_state:
st.session_state.chat_session = []
st.session_state.messages = []
st.session_state.enable_tts = True # デフォルトでTTSを有効化
# チェックボックスを作成
st.sidebar.markdown("## Settings")
enable_tts = st.sidebar.checkbox("Enable Text-to-Speech", st.session_state.enable_tts)
st.session_state.enable_tts = enable_tts # チェックボックスの状態を保存
# 音声を選択するドロップダウンメニューを作成
if "voice" not in st.session_state:
st.session_state.voice = "nova"
voice = st.sidebar.selectbox("Voice", ["alloy", "echo", "fable", "onyx", "nova", "shimmer"], index=4)
st.session_state.voice = voice
# チャット履歴の表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# チャット入力
input_text = st.chat_input("Type your message here...", key="input_text")
# 音声入力
audio_bytes = audio_recorder(
text="<<<Recording ends,click again or remain silent for two seconds.>>>",
recording_color="#e8b62c",
neutral_color="#2EF218",
icon_name="microphone-lines",
icon_size="4x",
pause_threshold=2.0,
sample_rate=41_000
)
# 入力処理
if input_text:
st.session_state.messages.append({"role": "user", "content": input_text})
with st.chat_message("user"):
st.markdown(input_text)
full_response = get_response(input_text)
st.session_state.chat_session.append({"role": "user", "content": input_text})
st.session_state.chat_session.append({"role": "assistant", "content": full_response})
with st.chat_message("assistant"):
st.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
# テキストを音声に変換し、再生する (チェックボックスがオンの場合のみ)
if st.session_state.enable_tts:
audio_data = text_to_speech(full_response, st.session_state.voice)
audio_str = f"data:audio/mpeg;base64,{base64.b64encode(audio_data).decode()}"
audio_html = f"""
<audio autoplay>
<source src="{audio_str}" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
"""
st.markdown(audio_html, unsafe_allow_html=True)
elif audio_bytes:
audio_transcript = audio_to_text(audio_bytes)
if audio_transcript:
st.session_state.messages.append({"role": "user", "content": audio_transcript})
with st.chat_message("user"):
st.markdown(audio_transcript)
full_response = get_response(audio_transcript)
st.session_state.chat_session.append({"role": "user", "content": audio_transcript})
st.session_state.chat_session.append({"role": "assistant", "content": full_response})
with st.chat_message("assistant"):
st.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
# テキストを音声に変換し、再生する (チェックボックスがオンの場合のみ)
if st.session_state.enable_tts:
audio_data = text_to_speech(full_response, st.session_state.voice)
audio_str = f"data:audio/mpeg;base64,{base64.b64encode(audio_data).decode()}"
audio_html = f"""
<audio autoplay>
<source src="{audio_str}" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
"""
st.markdown(audio_html, unsafe_allow_html=True)streamrit run main.pyそれではまた
追記:claude-3-OPUSモデルをAPI経由でチャットボットを作成。


ここから作った鍵を.zshrc内に
export ANTHROPIC_API_KEY=あなたのキーと書いておいて
pip install anthropicimport os
import anthropic
anthropic_client = anthropic.Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
message = anthropic_client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{"role": "user", "content": "こんにちはクロードくん"}
]
)
print(message.content[0].text)こんにちは!私は人工知能のアシスタントのクロードです。どのようなお手伝いができるでしょうか?お困りのこと、興味のあるトピック、雑談など、なんでもお聞かせください。できる限りお役に立てるよう頑張ります。準備ができましたので
#main.py
import streamlit as st
import anthropic
import os
import base64
from openai import OpenAI
from audio_recorder_streamlit import audio_recorder
# Anthropic API,OpenAI,クライアントの初期化
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
anthropic_client = anthropic.Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
# 音声をテキストに変換する関数
def audio_to_text(audio_bytes):
write_audio_file("recorded_audio.wav", audio_bytes)
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=open("recorded_audio.wav", mode="rb"),
#format="abx"
)
return transcript.text
# 音声ファイルを書き込む関数
def write_audio_file(file_path, audio_bytes):
with open(file_path, "wb") as audio_file:
audio_file.write(audio_bytes)
# テキストを音声に変換する関数
def text_to_speech(text, voice):
response = client.audio.speech.create(
model="tts-1",
voice=voice,
input=text,
response_format="mp3"
)
audio_data = response.content
return audio_data
# テキストからレスポンスを取得する関数
def get_response(prompt):
message = anthropic_client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
# アプリのタイトル設定
st.title("claude-3-opus-20240229 by Anthropic")
# セッション状態の初期化
if "chat_session" not in st.session_state:
st.session_state.chat_session = []
st.session_state.messages = []
st.session_state.enable_tts = True # デフォルトでTTSを有効化
# サイドバーの設定
with st.sidebar:
st.markdown("## Settings")
enable_tts = st.checkbox("Enable Text-to-Speech", st.session_state.enable_tts)
st.session_state.enable_tts = enable_tts
if "voice" not in st.session_state:
st.session_state.voice = "nova"
voice = st.selectbox("Voice", ["alloy", "echo", "fable", "onyx", "nova", "shimmer"], index=4)
st.session_state.voice = voice
# チャット履歴の表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# チャット入力
input_text = st.chat_input("Type your message here...", key="input_text")
# 音声入力
audio_bytes = audio_recorder(
text="<<<Recording ends,click again or remain silent for two seconds.>>>",
recording_color="#e8b62c",
neutral_color="#2EF218",
icon_name="microphone-lines",
icon_size="4x",
pause_threshold=2.0,
sample_rate=41_000
)
# 入力処理
if input_text:
st.session_state.messages.append({"role": "user", "content": input_text})
with st.chat_message("user"):
st.markdown(input_text)
full_response = get_response(input_text)
st.session_state.chat_session.append({"role": "user", "content": input_text})
st.session_state.chat_session.append({"role": "assistant", "content": full_response})
with st.chat_message("assistant"):
st.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
# テキストを音声に変換し、再生する (チェックボックスがオンの場合のみ)
if st.session_state.enable_tts:
audio_data = text_to_speech(full_response, st.session_state.voice)
audio_str = f"data:audio/mpeg;base64,{base64.b64encode(audio_data).decode()}"
audio_html = f"""
<audio autoplay>
<source src="{audio_str}" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
"""
st.markdown(audio_html, unsafe_allow_html=True)
elif audio_bytes:
audio_transcript = audio_to_text(audio_bytes)
if audio_transcript:
st.session_state.messages.append({"role": "user", "content": audio_transcript})
with st.chat_message("user"):
st.markdown(audio_transcript)
full_response = get_response(audio_transcript)
st.session_state.chat_session.append({"role": "user", "content": audio_transcript})
st.session_state.chat_session.append({"role": "assistant", "content": full_response})
with st.chat_message("assistant"):
st.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
# テキストを音声に変換し、再生する (チェックボックスがオンの場合のみ)
if st.session_state.enable_tts:
audio_data = text_to_speech(full_response, st.session_state.voice)
audio_str = f"data:audio/mpeg;base64,{base64.b64encode(audio_data).decode()}"
audio_html = f"""
<audio autoplay>
<source src="{audio_str}" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
"""
st.markdown(audio_html, unsafe_allow_html=True)streamrit run main.py

opusさんになると、はっちゃけた回答を避けてきます?