Command R+ GPTQをローカルLLMとしてvllmでOpenAI API互換サーバ動作させてみた話

大阪成蹊大学データサイエンス学部の鎌原です。
うちの学部にはNVIDIA A100 80GBを2基積んだ仮想サーバがあります。
Cohere For AI (https://cohere.com/)のCommand RというLLMがなかなか性能がよいという話で、非営利で重みも公開しているということなのでCommand R plusを早速ローカルで試してみると、4bitで読み込んでもなかなか良い応答をしてくれます。
ということでOpen AI互換サーバとして動作させたいと思っていろいろ試しているうちに、vllmもCommand Rに対応しているとのことで、vllmで動かしてみることにしました。なお、動かすのはGPUメモリの関係でGPTQで量子化されたモデル。
A100 80GB×1で動作する仮想マシンの作成は省略。
vllmのInstalltion を参考にDockerでnvcr.io/nvidia/pytorch:23.10-py3を動かす。
$ # Use `--ipc=host` to make sure the shared memory is large enough.
$ docker run --gpus all -it --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -p 8888:8888 nvcr.io/nvidia/pytorch:23.10-py3
まず、pipでvllmのモジュールを取ってくる(2024年4月10日現在で、0.4.0.post1)
# pip install vllm
vllmが対応するモデルのリストにCohereForAI/c4ai-command-r-v01はあります。0.4.0.post1はGPTQにはまだ対応していないのですが、mainブランチではすでに対応しているとのことで、そちらのcommandr.pyを取ってきます。
(もちろん、git clone https://github.com/vllm-project/vllm.gitでソースを取ってきてインストールするのでもokかと思います)
ここではGithubのvllmレポジトリからwgetで、commandr.pyを取ってきて、/usr/local/lib/python3.10/dist-packages/vllm/model_executor/models/にコピー(インストール先は異なる場合があります)しました。
# wget https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/commandr.py
# cp commandr.py /usr/local/lib/python3.10/dist-packages/vllm/model_executor/models/
使用するモデルのはHugging FaceにあるGPTQに変換したCommand R+です。
Open AI API互換サーバとして動作させたいので、以下のコマンドでvllmをサーバとして動作させます。
# python -m vllm.entrypoints.openai.api_server --model alpindale/c4ai-command-r-plus-GPTQ --quantization gptq --enforce-eager --port 8888
(なお、実際にはHugging Faceからモデルファイルをダウンロードしてからローカルのモデルとして実行しています)
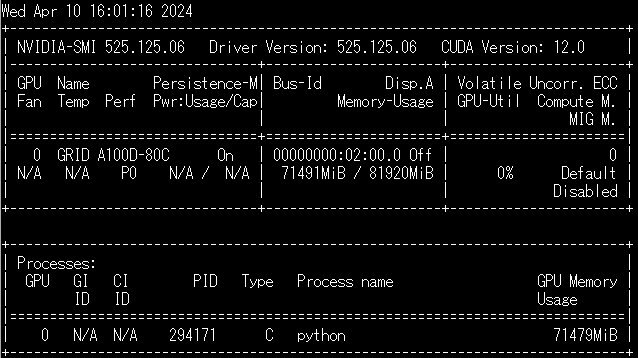
nvidia-smiでGPUの使用量を見ると、だいたい70GBほど使っているようです。
ブラウザで http://<仮想マシンIPアドレス>:8888/docs をアクセスして、APIのFastAPIのドキュメントが表示されれば、動作しています。
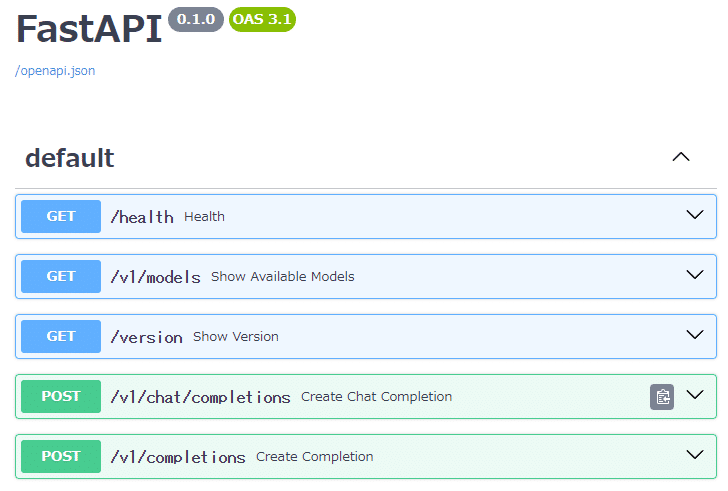
これで、サーバ側の準備は終わりです。
クライアント側はストリーミングチャットボットをGradioのサンプル通りに作りました。OpenAIのところを、base_urlでローカルの互換APIサーバを指定して、model名を"alpindale/c4ai-command-r-plus-GPTQ"にするだけです。
from openai import OpenAI
import gradio as gr
client = OpenAI(base_url="http://<仮想マシンのIP>:8888/v1")
def predict(message, history):
history_openai_format = []
for human, assistant in history:
history_openai_format.append({"role": "user", "content": human })
history_openai_format.append({"role": "assistant", "content":assistant})
history_openai_format.append({"role": "user", "content": message})
response = client.chat.completions.create(model='alpindale/c4ai-command-r-plus-GPTQ',
messages= history_openai_format,
max_token=2048,
temperature=0.7,
stream=True)
partial_message = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
partial_message = partial_message + chunk.choices[0].delta.content
yield partial_message
gr.ChatInterface(predict).launch()以下は実行例です。
Command R plus GPTQのA100 80GBでの実行例。なお、この動画は、Snipping Tool(Win+Shift+S)で取り込んだ。その方法もCommand R+が教えてくれたが、この動画の時は教えてくれなかった。 pic.twitter.com/JqS0QEAEWq
— 鎌原淳三(Junzo KAMAHARA) (@jun3k) April 10, 2024
これを実行した時のサーバ側のログの一部。生成の平均スループットとして、18.3 tokens/sと出ている。

ちょっとびっくりしたのだが、ちなみにChatGPT(GPT-4)に聞いたところ、Snipping Toolによる方法でできるか聞いても、動画を記録する機能はないと答えた。Snipping Toolで動画を記録する機能はWindows 11 22H2から使えるようになっており、2023年の段階では知っていてもおかしくないが、GPT-4はできないと答えた。Command R plusはSnipping Toolで動画を記録できるかと聞けばできると答えてくれる。この点だけを見れば、GPT-4よりもCommand R+の方が上回っていると言える。


サーバ化すると、並行して複数のAPIリクエストを送れる。その実践例があったので実行してみた。
変更箇所はOpenAI()にbase_urlを追加するのと、モデル名を変更するところだけ。コードは省略。
4並列でCommand R plus GPTQをvllmで実行した時の動画とvllm側のログ。4つのリクエストの時、50.7 tokens/sと表示されている https://t.co/ZWBGCWYImZ pic.twitter.com/NVtZXkNzoy
— 鎌原淳三(Junzo KAMAHARA) (@jun3k) April 10, 2024
Command R Plusは、Hugging FaceのSpaceでも体験できるので、その実力を試して欲しい。
Cohereのサイトではさらに高度な機能を提供しているようです。
しかし、ローカルLLMでもこれだけの回答ができるようになったのは割とびっくりです。